FrugalPrompt: Reducing Contextual Overhead in Large Language Models via Token Attribution
作者: Syed Rifat Raiyan, Md Farhan Ishmam, Abdullah Al Imran, Mohammad Ali Moni
分类: cs.CL
发布日期: 2025-10-18 (更新: 2025-10-22)
🔗 代码/项目: GITHUB
💡 一句话要点
FrugalPrompt:通过Token归因减少大语言模型中的上下文开销
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 提示压缩 Token归因 上下文精简 效率优化
📋 核心要点
- 大型语言模型依赖冗长的上下文,导致高昂的计算成本和延迟,而许多token是冗余的。
- FrugalPrompt通过token归因,仅保留最重要的token,从而压缩提示,减少计算开销。
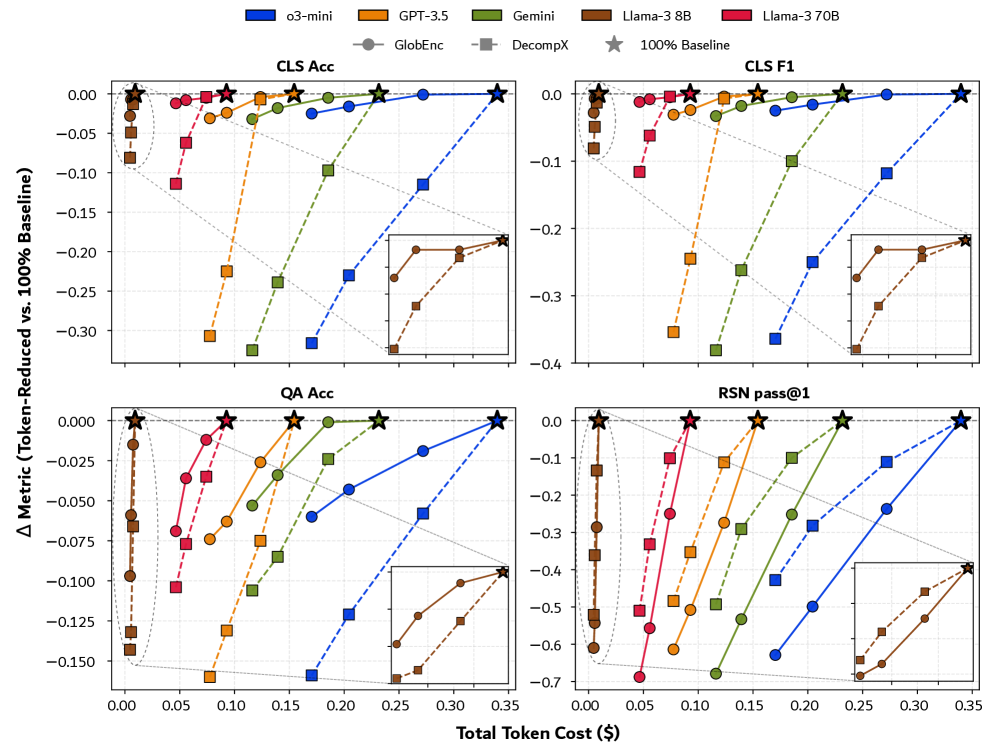
- 实验表明,在情感分析等任务中,大幅压缩提示仅造成少量性能损失,但在数学推理中性能下降明显。
📝 摘要(中文)
大型语言模型(LLM)的出色性能很大程度上归功于其庞大的输入上下文,然而,这种冗长性增加了经济成本、碳足迹和推理延迟。这种开销主要源于典型提示中存在的冗余低效token,因为通常只有一小部分token携带了大部分语义权重。为了解决这种低效问题,我们引入了FrugalPrompt,这是一种新颖的LLM提示压缩框架,它仅保留语义上最重要的token。利用两种先进的token归因方法GlobEnc和DecompX,我们为输入序列中的每个token分配显著性分数,对其进行排序以保留前k%的token,并获得一个稀疏的简化提示。我们在情感分析、常识问答、摘要和数学推理四个NLP任务中使用一系列前沿LLM评估了该方法。对于前三个任务,20%的提示缩减仅导致任务性能的边际损失,表明现代LLM可以从高显著性线索中重建省略的上下文。相比之下,数学推理的性能急剧下降,反映出对完整token连续性的更强依赖性。对bottom-k%和random-k% token的进一步分析揭示了不对称的性能模式,这可能表明潜在的任务污染效应,其中模型可能对传统NLP任务采用来自预训练暴露的浅层记忆模式。我们认为,我们的工作有助于更细致地理解LLM在性能-效率权衡中的行为,并划定了容忍上下文稀疏性的任务与需要详尽上下文的任务之间的界限。我们的源代码和模型可在https://github.com/Starscream-11813/Frugal-ICL获得。
🔬 方法详解
问题定义:现有的大型语言模型依赖于大量的上下文信息来获得良好的性能,但同时也带来了巨大的计算开销,包括更高的经济成本、更大的碳排放和更长的推理时间。一个主要原因是,在输入提示中存在大量的冗余和低效的token,这些token对于最终的预测结果贡献很小。因此,如何减少提示中的冗余信息,同时保持模型的性能,是一个重要的研究问题。
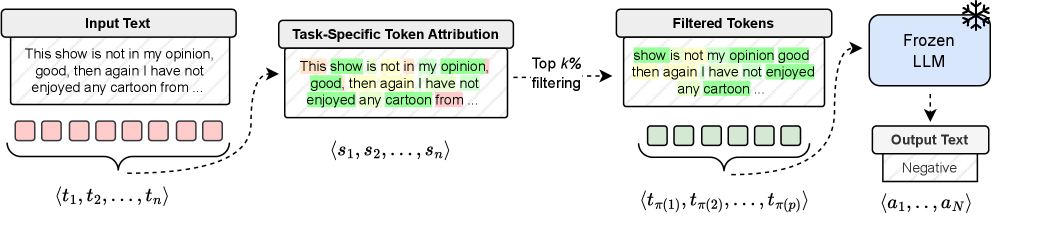
核心思路:FrugalPrompt的核心思路是通过token归因的方法,识别出提示中最重要的token,并只保留这些token,从而实现提示的压缩。该方法假设,只有一小部分token携带了提示中的大部分语义信息,而其他的token可以被安全地移除,而不会对模型的性能产生显著的影响。
技术框架:FrugalPrompt框架主要包含以下几个步骤:1. 使用现有的token归因方法(如GlobEnc和DecompX)为输入序列中的每个token计算一个显著性分数。2. 根据显著性分数对token进行排序。3. 保留前k%的token,并按照原始顺序将它们组合成一个新的、压缩后的提示。4. 将压缩后的提示输入到大型语言模型中进行推理。
关键创新:FrugalPrompt的关键创新在于它提出了一种通用的提示压缩框架,该框架可以与不同的token归因方法和大型语言模型相结合。此外,该论文还通过实验证明了,在许多NLP任务中,大幅压缩提示并不会显著降低模型的性能,这表明大型语言模型具有一定的上下文重建能力。
关键设计:该方法使用了两种现有的token归因方法:GlobEnc和DecompX。GlobEnc是一种基于全局编码的token归因方法,它通过计算每个token对整个序列表示的贡献来评估其重要性。DecompX是一种基于分解的token归因方法,它通过将模型的预测结果分解为各个token的贡献来评估其重要性。实验中,作者使用了不同的k值(即保留的token的比例)来评估压缩效果。没有特别设计新的损失函数或网络结构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在情感分析、常识问答和摘要等任务中,将提示压缩到原来的20%只会导致性能的轻微下降。例如,在某些任务中,性能下降不到1%。然而,在数学推理任务中,性能下降非常明显,这表明该任务对上下文的完整性要求更高。对不同token选择策略(top-k%, bottom-k%, random-k%)的分析揭示了任务污染的可能性。
🎯 应用场景
FrugalPrompt具有广泛的应用前景,可以应用于各种需要使用大型语言模型的场景,尤其是在资源受限的环境中,例如移动设备或边缘计算设备。通过减少提示的长度,可以降低计算成本和延迟,从而提高用户体验。此外,该方法还可以用于保护用户隐私,因为可以移除提示中的敏感信息。
📄 摘要(原文)
Large language models (LLMs) owe much of their stellar performance to expansive input contexts, yet such verbosity inflates monetary costs, carbon footprint, and inference-time latency. Much of this overhead manifests from the redundant low-utility tokens present in typical prompts, as only a fraction of tokens typically carries the majority of the semantic weight. We address this inefficiency by introducing FrugalPrompt, a novel prompt compression framework for LLMs, which retains only the most semantically significant tokens. Leveraging two state-of-the-art token attribution methods, GlobEnc and DecompX, we assign salience scores to every token in an input sequence, rank them to preserve the top-k% tokens in their original order, and obtain a sparse frugalized prompt. We evaluate the approach across four NLP tasks: Sentiment Analysis, Commonsense QA, Summarization, and Mathematical Reasoning, using a suite of frontier LLMs. For the first three tasks, a 20% prompt reduction incurs only a marginal loss in task performance, demonstrating that contemporary LLMs can reconstruct elided context from high-salience cues. In contrast, performance on mathematical reasoning deteriorates sharply, reflecting a stronger dependence on complete token continuity. Further analysis with bottom-k% and random-k% tokens reveals asymmetric performance patterns that may suggest potential task contamination effects, wherein models may resort to shallow memorized patterns from pretraining exposure for conventional NLP tasks. We posit that our work contributes to a more nuanced understanding of LLM behavior in performance-efficiency trade-offs, and delineate the boundary between tasks tolerant to contextual sparsity and those requiring exhaustive context. Our source code and models are available at: https://github.com/Starscream-11813/Frugal-ICL.