Utilising Large Language Models for Generating Effective Counter Arguments to Anti-Vaccine Tweets
作者: Utsav Dhanuka, Soham Poddar, Saptarshi Ghosh
分类: cs.CL
发布日期: 2025-10-18
备注: 14 pages, 1 figure, work done as a part of B.Tech project at IIT Kharagpur
💡 一句话要点
利用大型语言模型生成针对反疫苗推文的有效反驳论点
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 反疫苗信息 反驳论点生成 提示工程 微调 多标签分类 虚假信息对抗
📋 核心要点
- 现有方法难以实时生成针对反疫苗信息的定制化反驳论点,缺乏针对性的辩驳削弱了信息对抗效果。
- 利用大型语言模型生成反驳论点,通过提示工程和微调优化生成效果,并结合推文分类增强上下文感知能力。
- 实验结果表明,整合标签描述和结构化微调能有效提升反驳论点的质量,为大规模对抗疫苗虚假信息提供可行方案。
📝 摘要(中文)
在公共健康日益受到社交媒体信息影响的时代,对抗疫苗怀疑论和虚假信息已成为重要的社会目标。围绕疫苗接种的误导性叙述广泛传播,阻碍了高免疫率的实现,并削弱了对健康建议的信任。虽然检测虚假信息的努力取得了显著进展,但生成针对此类主张的实时反驳论点仍然是一个未被充分探索的领域。本文探讨了大型语言模型在生成针对疫苗虚假信息的合理反驳论点方面的能力。在先前关于揭穿虚假信息的研究基础上,我们实验了各种提示策略和微调方法,以优化反驳论点的生成。此外,我们训练分类器将反疫苗推文分类为多标签类别,例如对疫苗功效、副作用和政治影响的担忧,从而实现更具上下文意识的反驳。通过人工判断、基于大型语言模型的评估和自动指标进行的评估表明,这些方法之间具有很强的一致性。我们的研究结果表明,整合标签描述和结构化微调可以提高反驳论点的有效性,为大规模减轻疫苗虚假信息提供了一种有前景的方法。
🔬 方法详解
问题定义:论文旨在解决针对社交媒体上反疫苗推文,自动生成有效反驳论点的问题。现有方法难以针对特定类型的反疫苗信息生成定制化的、有说服力的反驳,并且缺乏对反疫苗信息背后深层原因的理解。这导致反驳效果不佳,难以有效消除公众的疑虑。
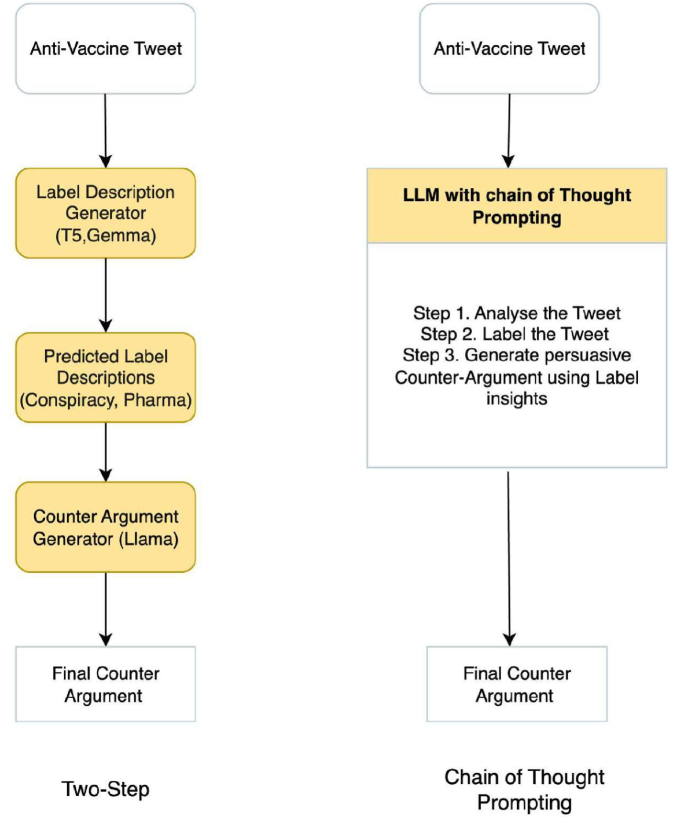
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大生成能力,通过精心设计的提示(Prompt)和微调(Fine-tuning)策略,使其能够生成针对特定反疫苗推文的有效反驳论点。同时,通过训练分类器对反疫苗推文进行分类,从而使LLM能够根据推文的类别生成更具针对性的反驳。
技术框架:整体框架包含以下几个主要模块:1) 反疫苗推文分类器:用于将推文分类到不同的类别,例如对疫苗功效的担忧、对副作用的担忧、政治影响等。2) 反驳论点生成器:基于大型语言模型,通过提示工程和微调生成反驳论点。3) 评估模块:通过人工评估、基于LLM的评估和自动指标来评估生成反驳论点的质量。
关键创新:论文的关键创新在于:1) 结合了推文分类和反驳论点生成,使得反驳更具针对性。2) 探索了不同的提示策略和微调方法,优化了反驳论点的生成效果。3) 采用了多种评估方法,包括人工评估、基于LLM的评估和自动指标,从而更全面地评估了生成反驳论点的质量。
关键设计:在提示工程方面,论文尝试了不同的提示模板,例如包含标签描述的提示。在微调方面,论文采用了结构化微调方法,即针对不同类别的反疫苗推文,使用不同的微调数据集。分类器使用了多标签分类,允许一条推文属于多个类别。损失函数使用了标准的交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,整合标签描述和结构化微调能够显著提高反驳论点的有效性。具体而言,与基线方法相比,该方法在人工评估、基于LLM的评估和自动指标上均取得了显著提升。例如,在人工评估中,该方法生成的反驳论点在相关性、流畅性和说服力方面均优于基线方法。这些结果表明,该方法为大规模对抗疫苗虚假信息提供了一种有前景的解决方案。
🎯 应用场景
该研究成果可应用于社交媒体平台,自动生成针对虚假信息的反驳论点,从而提高公众对疫苗等公共卫生信息的信任度。此外,该方法还可以扩展到其他领域,例如对抗气候变化否认言论、政治宣传等,具有广泛的应用前景和社会价值。未来,可以进一步研究如何提高反驳论点的说服力,以及如何将该方法与用户交互相结合,实现更有效的虚假信息对抗。
📄 摘要(原文)
In an era where public health is increasingly influenced by information shared on social media, combatting vaccine skepticism and misinformation has become a critical societal goal. Misleading narratives around vaccination have spread widely, creating barriers to achieving high immunisation rates and undermining trust in health recommendations. While efforts to detect misinformation have made significant progress, the generation of real time counter-arguments tailored to debunk such claims remains an insufficiently explored area. In this work, we explore the capabilities of LLMs to generate sound counter-argument rebuttals to vaccine misinformation. Building on prior research in misinformation debunking, we experiment with various prompting strategies and fine-tuning approaches to optimise counter-argument generation. Additionally, we train classifiers to categorise anti-vaccine tweets into multi-labeled categories such as concerns about vaccine efficacy, side effects, and political influences allowing for more context aware rebuttals. Our evaluation, conducted through human judgment, LLM based assessments, and automatic metrics, reveals strong alignment across these methods. Our findings demonstrate that integrating label descriptions and structured fine-tuning enhances counter-argument effectiveness, offering a promising approach for mitigating vaccine misinformation at scale.