Thinking About Thinking: Evaluating Reasoning in Post-Trained Language Models
作者: Pratham Singla, Shivank Garg, Ayush Singh, Ishan Garg, Ketan Suhaas Saichandran
分类: cs.CL, cs.AI
发布日期: 2025-10-18
💡 一句话要点
评估后训练语言模型推理能力的“思考”能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 后训练 策略学习 可解释性
📋 核心要点
- 现有大型语言模型在复杂推理任务中表现出潜力,但缺乏对其自身推理过程的理解。
- 论文通过定义三个核心能力(感知、泛化、对齐)来评估模型是否“思考”,即是否理解其推理过程。
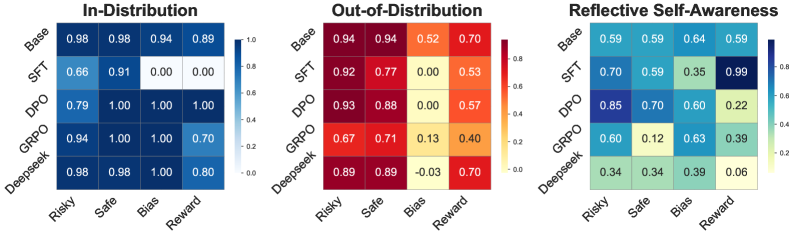
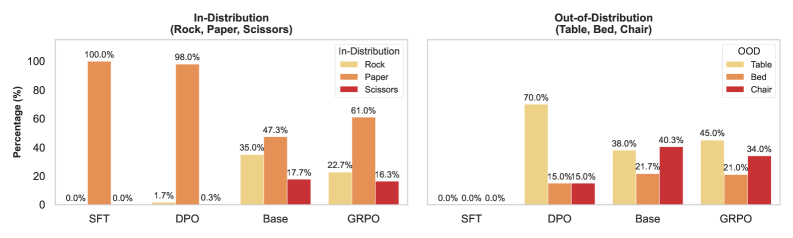
- 实验对比了SFT、DPO和GRPO三种后训练方法,发现强化学习训练的模型在感知和泛化方面更优,但在对齐方面存在问题。
📝 摘要(中文)
大型语言模型(LLM)通过生成补充的规划tokens,在后训练技术方面取得了进展,从而增强了处理复杂、逻辑密集型任务的能力。这项进展引出了一个基本问题:这些模型是否意识到它们“学习”和“思考”的内容?为了解决这个问题,我们定义了三个核心能力:(1)对学习到的潜在策略的感知;(2)这些策略在不同领域中的泛化;(3)内部推理轨迹与最终输出之间的一致性。我们通过多个任务对这些能力进行了实证评估,每个任务都旨在需要学习一种不同的策略。此外,我们对比了通过监督微调(SFT)、直接策略优化(DPO)和组相对策略优化(GRPO)进行后训练的模型的特性。我们的研究结果表明,与SFT模型相比,通过强化学习训练的模型不仅表现出更强的对其学习行为的感知能力和对新的、结构相似的任务的更强的泛化能力,而且通常表现出推理轨迹与最终输出之间的弱对齐,这种效应在GRPO训练的模型中最为明显。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在后训练后,是否真正理解并能有效利用其学习到的推理策略。现有方法主要关注模型在特定任务上的性能提升,而忽略了模型内部推理过程的可解释性和可靠性。痛点在于,即使模型输出了正确答案,我们也无法确定它是通过合理的推理得到的,还是仅仅通过记忆或模式匹配。
核心思路:论文的核心思路是将LLM的推理过程视为一种策略学习过程,并从三个维度评估模型对该策略的理解程度:感知(awareness)、泛化(generalization)和对齐(alignment)。感知是指模型是否意识到自己正在使用某种策略;泛化是指模型能否将学到的策略应用到新的、相似的任务中;对齐是指模型的内部推理轨迹是否与其最终输出一致。通过这三个维度的评估,可以更全面地了解模型的推理能力。
技术框架:论文构建了一系列需要学习特定策略的任务,并使用不同的后训练方法(SFT、DPO、GRPO)训练LLM。然后,通过设计特定的评估指标,来衡量模型在感知、泛化和对齐三个维度上的表现。具体来说,感知能力通过分析模型生成的规划tokens来评估;泛化能力通过在新的、结构相似的任务上测试模型的性能来评估;对齐能力通过比较模型的推理轨迹和最终输出来评估。
关键创新:论文的关键创新在于提出了一个评估LLM推理能力的框架,该框架不仅关注模型的性能,还关注模型对自身推理过程的理解。通过感知、泛化和对齐三个维度的评估,可以更深入地了解模型的推理机制,并发现潜在的问题。此外,论文还对比了不同后训练方法对模型推理能力的影响,为选择合适的后训练方法提供了指导。
关键设计:论文的关键设计包括:1) 设计了一系列需要学习特定策略的任务,例如逻辑推理、规划等;2) 定义了评估感知、泛化和对齐能力的指标,例如规划tokens的分析、新任务上的性能、推理轨迹与输出的相似度等;3) 采用了不同的后训练方法(SFT、DPO、GRPO),并对比了它们对模型推理能力的影响。具体的参数设置和网络结构取决于所使用的LLM和后训练方法,论文中可能未详细描述。
🖼️ 关键图片

📊 实验亮点
实验结果表明,强化学习训练的模型(DPO和GRPO)在感知和泛化能力方面优于监督微调模型(SFT),但GRPO训练的模型在推理轨迹与最终输出的对齐方面表现较差。这表明,虽然强化学习可以提高模型的性能,但也可能导致模型内部推理过程与最终输出之间的不一致。具体的性能提升幅度未知,需要参考论文中的详细数据。
🎯 应用场景
该研究成果可应用于提升大型语言模型在复杂决策、智能规划、自动驾驶等领域的可靠性和可解释性。通过提高模型对自身推理过程的理解,可以减少模型产生错误或不合理输出的风险,并增强用户对模型的信任。未来的研究可以进一步探索如何提高模型的感知、泛化和对齐能力,从而构建更智能、更可靠的人工智能系统。
📄 摘要(原文)
Recent advances in post-training techniques have endowed Large Language Models (LLMs) with enhanced capabilities for tackling complex, logic-intensive tasks through the generation of supplementary planning tokens. This development raises a fundamental question: Are these models aware of what they "learn" and "think"? To address this, we define three core competencies: (1) awareness of learned latent policies, (2) generalization of these policies across domains, and (3) alignment between internal reasoning traces and final outputs. We empirically evaluate these abilities on several tasks, each designed to require learning a distinct policy. Furthermore, we contrast the profiles of models post-trained via Supervised Fine-Tuning (SFT), Direct Policy Optimization (DPO), and Group Relative Policy Optimization (GRPO). Our findings indicate that RL-trained models not only demonstrate greater awareness of their learned behaviors and stronger generalizability to novel, structurally similar tasks than SFT models but also often exhibit weak alignment between their reasoning traces and final outputs, an effect most pronounced in GRPO-trained models.