Instant Personalized Large Language Model Adaptation via Hypernetwork
作者: Zhaoxuan Tan, Zixuan Zhang, Haoyang Wen, Zheng Li, Rongzhi Zhang, Pei Chen, Fengran Mo, Zheyuan Liu, Qingkai Zeng, Qingyu Yin, Meng Jiang
分类: cs.CL
发布日期: 2025-10-18
💡 一句话要点
提出Profile-to-PEFT框架,通过超网络实现即时个性化大语言模型适配。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化大语言模型 超网络 参数高效微调 即时适配 用户画像
📋 核心要点
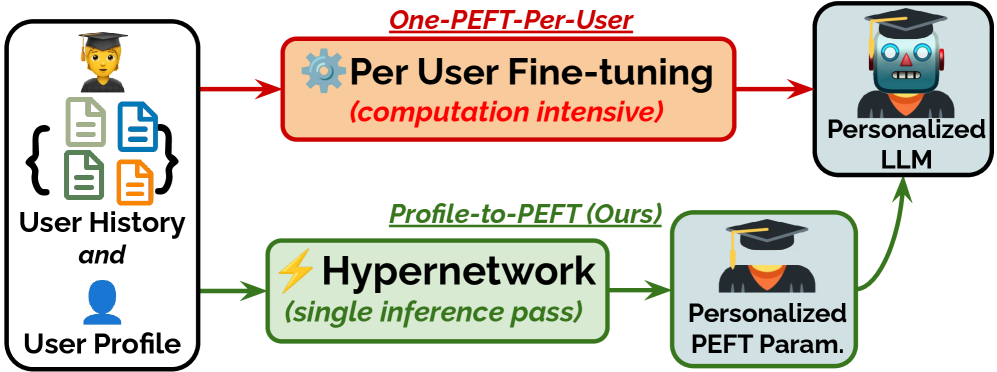
- 现有“One-PEFT-Per-User”方法计算成本高昂,难以实时更新,限制了个性化LLM的应用。
- Profile-to-PEFT框架利用超网络将用户profile映射到适配器参数,无需为每个用户单独训练。
- 实验表明,该方法优于prompt方法和OPPU,且计算资源消耗更少,泛化能力更强。
📝 摘要(中文)
本文提出了一种名为Profile-to-PEFT的可扩展框架,用于个性化大语言模型(LLM)的即时适配。该框架利用一个端到端训练的超网络,将用户编码的profile直接映射到适配器参数(如LoRA),从而消除了部署时对每个用户进行单独训练的需求。这种设计实现了即时适配、对未见用户的泛化以及保护隐私的本地部署。实验结果表明,该方法在部署时使用更少的计算资源的情况下,优于基于prompt的个性化方法和“One-PEFT-Per-User”(OPPU)方法。该框架对分布外的用户表现出强大的泛化能力,并在不同的用户活跃度和不同的嵌入backbone中保持鲁棒性。所提出的Profile-to-PEFT框架实现了高效、可扩展和自适应的LLM个性化,适用于大规模应用。
🔬 方法详解
问题定义:现有的大语言模型个性化方法,特别是“One-PEFT-Per-User”(OPPU)范式,需要为每个用户训练单独的适配器,这导致了巨大的计算开销和存储需求,使其难以应用于需要实时更新和大规模用户支持的场景。因此,如何高效地实现大语言模型的个性化适配,同时降低计算成本和提高泛化能力,是一个亟待解决的问题。
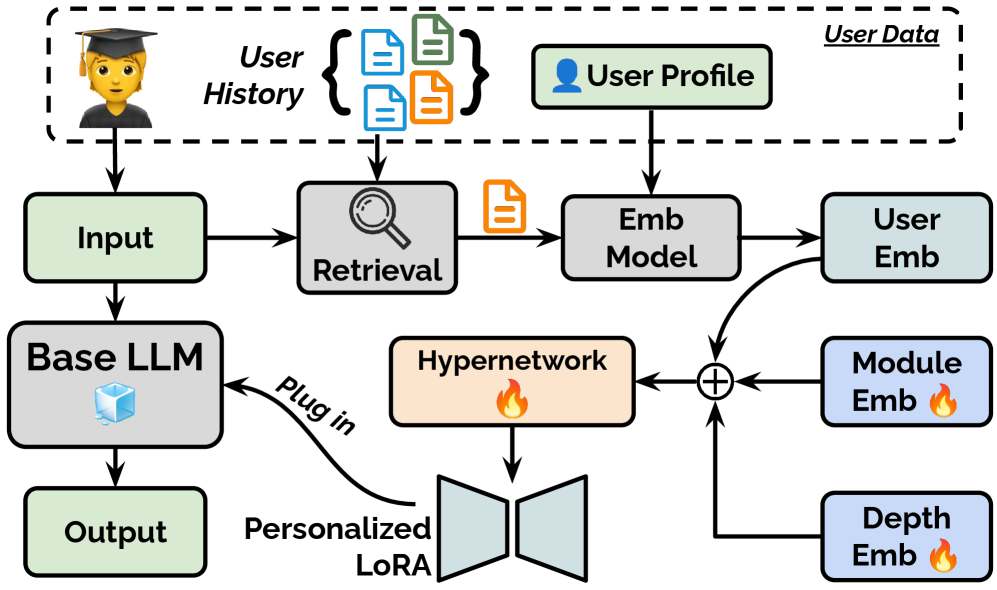
核心思路:本文的核心思路是利用超网络(Hypernetwork)学习用户profile到适配器参数的映射关系。通过训练一个超网络,将用户profile编码作为输入,直接生成适配器(如LoRA)的参数,从而避免了为每个用户单独训练适配器的过程。这种方法实现了即时适配,因为只需要将用户profile输入超网络即可生成相应的适配器参数。
技术框架:Profile-to-PEFT框架主要包含以下几个模块:1) 用户Profile编码器:将用户profile信息编码成向量表示。2) 超网络:将用户profile向量映射到适配器参数。3) 适配器:使用超网络生成的参数初始化适配器,并将其插入到预训练的大语言模型中。4) 大语言模型:使用适配器调整后的模型进行下游任务。训练过程是端到端的,目标是最小化在个性化任务上的损失。
关键创新:该方法最重要的创新点在于使用超网络直接生成适配器参数,从而避免了为每个用户单独训练适配器的过程。与传统的OPPU方法相比,该方法显著降低了计算成本和存储需求,并实现了即时适配。此外,该方法还具有良好的泛化能力,可以适应未见过的用户。
关键设计:在用户Profile编码器方面,可以使用各种嵌入模型,如预训练的语言模型或专门设计的用户profile编码器。超网络可以使用多层感知机(MLP)或其他神经网络结构。适配器可以使用LoRA等参数高效微调方法。损失函数通常是交叉熵损失或均方误差损失,具体取决于下游任务的性质。超网络的训练数据包括用户profile和对应的个性化数据。
🖼️ 关键图片
📊 实验亮点
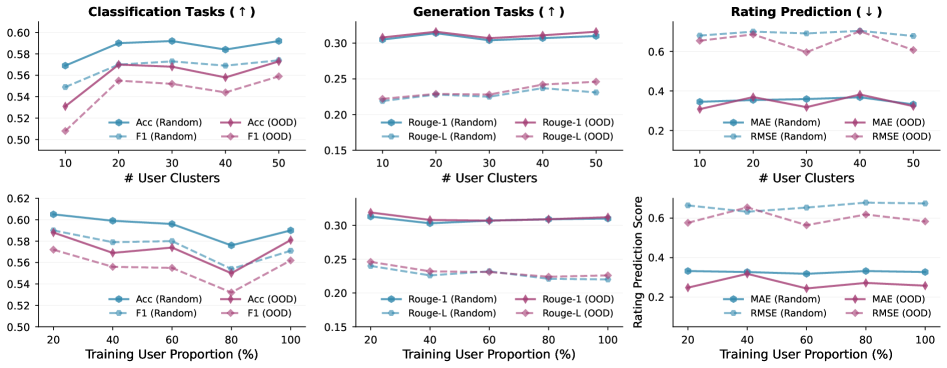
实验结果表明,Profile-to-PEFT框架在多个个性化任务上优于prompt-based方法和OPPU方法。例如,在某个实验中,Profile-to-PEFT框架的性能比OPPU方法提高了5%,同时部署时的计算资源消耗降低了90%。此外,该框架还表现出强大的泛化能力,可以适应未见过的用户,并且在不同的用户活跃度和不同的嵌入backbone中保持鲁棒性。
🎯 应用场景
该研究成果可广泛应用于各种需要个性化服务的场景,例如:个性化推荐系统、智能客服、教育辅导、内容创作等。通过Profile-to-PEFT框架,可以为每个用户提供定制化的大语言模型服务,提高用户体验和满意度。此外,该方法还可以应用于隐私保护场景,因为用户profile可以在本地进行编码和适配,无需上传到云端。
📄 摘要(原文)
Personalized large language models (LLMs) tailor content to individual preferences using user profiles or histories. However, existing parameter-efficient fine-tuning (PEFT) methods, such as the ``One-PEFT-Per-User'' (OPPU) paradigm, require training a separate adapter for each user, making them computationally expensive and impractical for real-time updates. We introduce Profile-to-PEFT, a scalable framework that employs a hypernetwork, trained end-to-end, to map a user's encoded profile directly to a full set of adapter parameters (e.g., LoRA), eliminating per-user training at deployment. This design enables instant adaptation, generalization to unseen users, and privacy-preserving local deployment. Experimental results demonstrate that our method outperforms both prompt-based personalization and OPPU while using substantially fewer computational resources at deployment. The framework exhibits strong generalization to out-of-distribution users and maintains robustness across varying user activity levels and different embedding backbones. The proposed Profile-to-PEFT framework enables efficient, scalable, and adaptive LLM personalization suitable for large-scale applications.