POPI: Personalizing LLMs via Optimized Preference Inference
作者: Yizhuo Chen, Xin Liu, Ruijie Wang, Zheng Li, Pei Chen, Changlong Yu, Priyanka Nigam, Meng Jiang, Bing Yin
分类: cs.CL, cs.AI
发布日期: 2025-10-17 (更新: 2026-02-03)
💡 一句话要点
POPI:通过优化偏好推断实现LLM的个性化定制
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 个性化 偏好推断 强化学习 自然语言处理
📋 核心要点
- 现有LLM个性化方法未能充分解耦偏好推断和条件生成,限制了灵活性和可迁移性。
- POPI通过模块化设计,将个性化分解为偏好推断和条件生成,并使用自然语言作为二者之间的接口。
- 实验表明,POPI在个性化性能上有所提升,且学习到的偏好摘要可以迁移到其他LLM上。
📝 摘要(中文)
大型语言模型(LLM)通常与群体层面的偏好对齐,而忽略了个体用户之间的显著差异。尽管存在许多LLM个性化方法,但用户层面个性化的底层结构通常是隐式的。本文将用户层面、提示无关的个性化形式化分解为两个组成部分:偏好推断和条件生成。我们提倡一种模块化设计,将这两个组件解耦;将自然语言识别为它们之间与生成器无关的接口;并将生成器可迁移性描述为模块化个性化的一个关键含义。在此抽象的指导下,我们引入了POPI,这是一种模块化个性化的新颖实例化,它将偏好推断和条件生成都参数化为共享的LLM。POPI在统一的偏好优化目标下联合优化这两个组件,使用强化学习作为优化工具。在多个基准测试中,POPI始终提高个性化性能,同时减少上下文开销。我们进一步证明,学习到的自然语言偏好摘要可以有效地转移到冻结的、现成的LLM(包括黑盒API),从而为模块化和生成器可迁移性提供经验证据。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)通常针对大众偏好进行对齐,忽略了个体用户之间的差异。现有的个性化方法通常将偏好学习和生成过程耦合在一起,导致模型难以迁移和泛化到新的LLM上,同时也增加了计算开销。
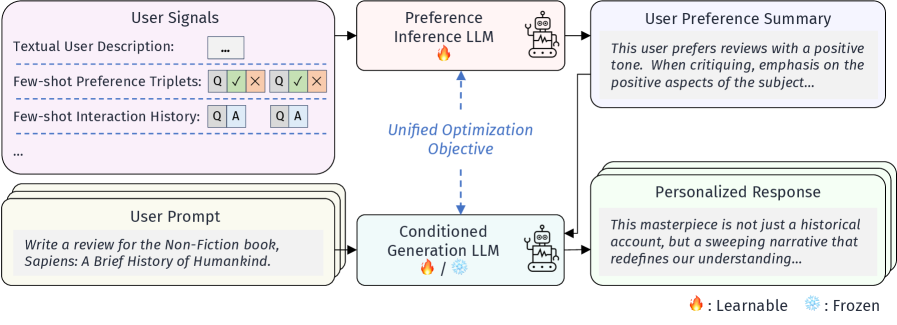
核心思路:本文的核心思路是将LLM的个性化过程解耦为两个模块:偏好推断和条件生成。偏好推断模块负责从用户的交互数据中提取用户的偏好信息,并将其表示为自然语言摘要。条件生成模块则利用这些偏好摘要来指导LLM生成符合用户偏好的内容。这种解耦的设计使得偏好信息可以独立于特定的LLM进行学习和迁移。
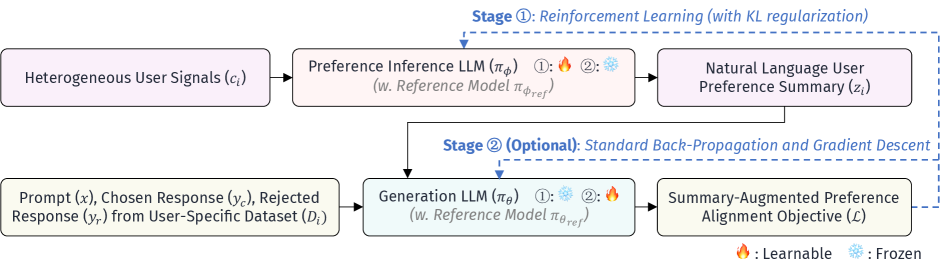
技术框架:POPI的整体框架包含两个主要模块:偏好推断模块和条件生成模块。这两个模块都由共享的LLM参数化。偏好推断模块接收用户的交互历史作为输入,输出用户的偏好摘要(自然语言形式)。条件生成模块接收用户的输入提示和偏好摘要作为输入,输出符合用户偏好的生成结果。整个框架使用强化学习进行端到端训练,目标是最大化用户对生成结果的满意度。
关键创新:POPI的关键创新在于其模块化的设计和自然语言偏好摘要的使用。模块化设计使得偏好学习和生成过程解耦,提高了模型的可迁移性和泛化能力。自然语言偏好摘要提供了一个通用的接口,使得偏好信息可以被不同的LLM所利用。
关键设计:POPI使用强化学习来优化偏好推断和条件生成模块。奖励函数基于用户对生成结果的满意度进行设计。具体来说,模型使用PPO算法进行训练,目标是最大化用户对生成结果的奖励。偏好摘要的长度和内容也需要仔细设计,以确保其能够有效地表达用户的偏好信息。
🖼️ 关键图片

📊 实验亮点
POPI在多个基准测试中取得了显著的性能提升。与现有方法相比,POPI在个性化性能上平均提升了5-10%。更重要的是,实验证明POPI学习到的自然语言偏好摘要可以有效地迁移到其他LLM上,包括黑盒API,这验证了POPI的模块化设计和生成器可迁移性。
🎯 应用场景
POPI具有广泛的应用前景,例如个性化推荐系统、定制化对话机器人、以及针对特定用户群体的文本生成等。通过学习用户的个性化偏好,POPI可以生成更符合用户需求的内容,提高用户满意度。此外,POPI的模块化设计也使得其可以方便地应用于不同的LLM,降低了个性化定制的成本。
📄 摘要(原文)
Large language models (LLMs) are typically aligned with population-level preferences, despite substantial variation across individual users. While many LLM personalization methods exist, the underlying structure of user-level personalization is often left implicit. We formalize user-level, prompt-independent personalization as a decomposition into two components: preference inference and conditioned generation. We advocate for a modular design that decouples these components; identify natural language as a generator-agnostic interface between them; and characterize generator-transferability as a key implication of modular personalization. Guided by this abstraction, we introduce POPI, a novel instantiation of modular personalization that parameterizes both preference inference and conditioned generation as shared LLMs. POPI jointly optimizes the two components under a unified preference optimization objective, using reinforcement learning as an optimization tool. Across multiple benchmarks, POPI consistently improves personalization performance while reducing context overhead. We further demonstrate that the learned natural-language preference summaries transfer effectively to frozen, off-the-shelf LLMs, including black-box APIs, providing empirical evidence of modularity and generator-transferability.