In Generative AI We (Dis)Trust? Computational Analysis of Trust and Distrust in Reddit Discussions
作者: Aria Pessianzadeh, Naima Sultana, Hildegarde Van den Bulck, David Gefen, Shahin Jabari, Rezvaneh Rezapour
分类: cs.CL
发布日期: 2025-10-17
💡 一句话要点
提出基于Reddit数据的计算框架,分析公众对生成式AI的信任与不信任。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 生成式AI 信任分析 Reddit 计算社会科学 情感分析
📋 核心要点
- 现有AI信任研究缺乏大规模、计算驱动的纵向分析方法,难以追踪公众对生成式AI信任的动态变化。
- 本研究利用Reddit数据,结合众包标注和分类模型,构建了一个计算框架,用于大规模分析公众对生成式AI的信任与不信任。
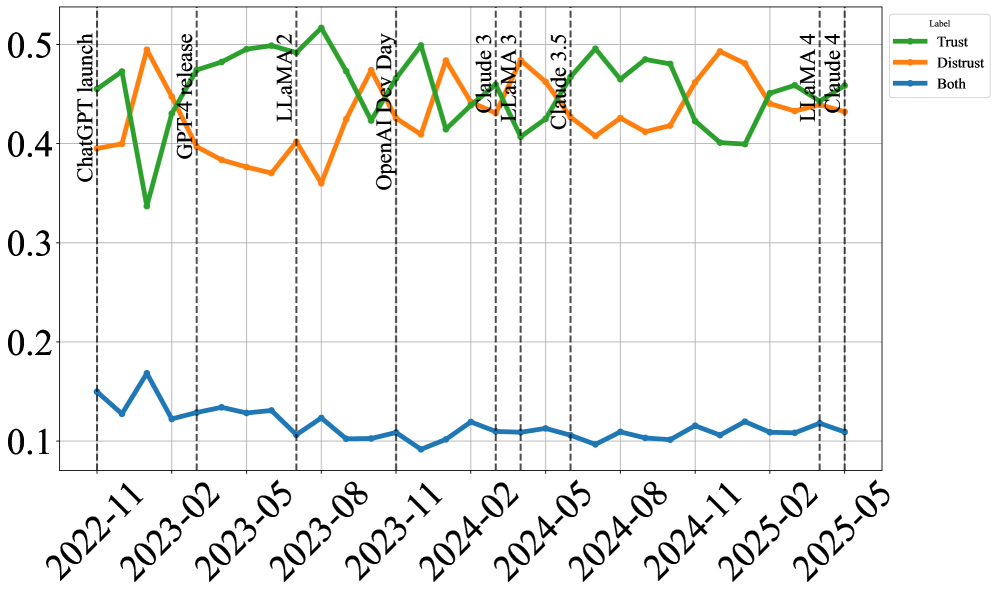
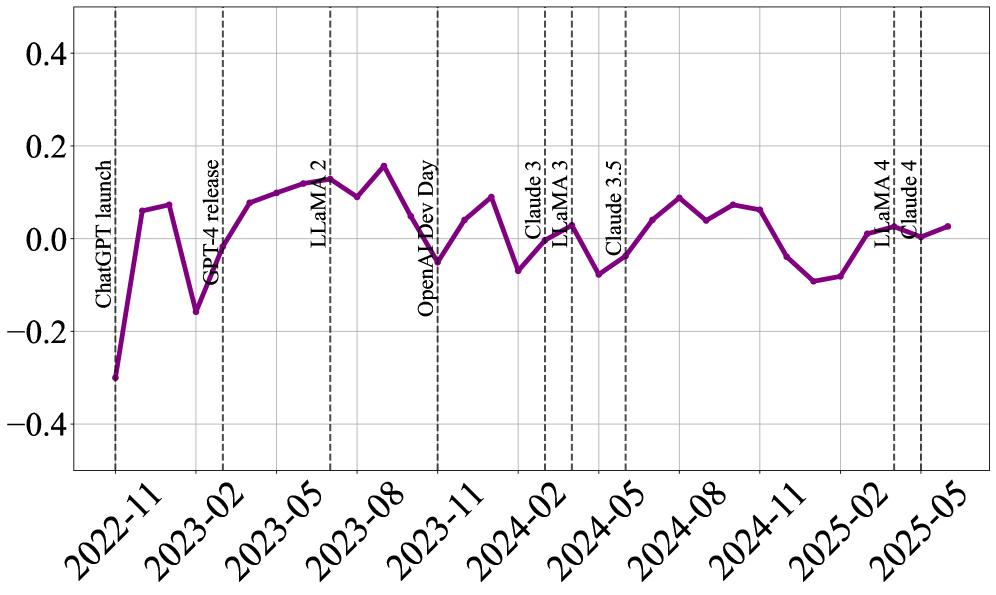
- 研究发现信任与不信任随时间推移基本平衡,技术性能和可用性是主要影响因素,且不同用户群体态度存在差异。
📝 摘要(中文)
生成式人工智能(GenAI)的兴起影响了人类生活的诸多方面。随着这些系统日益融入日常实践,理解公众对它们的信任对于负责任的采纳和治理至关重要。以往关于人工智能信任的研究主要借鉴心理学和人机交互,但缺乏对GenAI和大型语言模型(LLM)中信任和不信任进行计算、大规模和纵向测量的方法。本文首次对GenAI中的信任和不信任进行了计算研究,使用了跨越39个subreddit和197,618个帖子的多年Reddit数据集(2022-2025)。众包的代表性样本标注与分类模型相结合,以扩展分析。研究发现,信任和不信任随着时间的推移几乎是平衡的,并在主要模型发布前后发生变化。技术性能和可用性是主要维度,而个人经验是塑造态度的最常见原因。信任者(例如,专家、伦理学家、普通用户)之间也出现了不同的模式。研究结果为大规模信任分析提供了一个方法框架,并深入了解了公众对GenAI不断演变的看法。
🔬 方法详解
问题定义:现有研究缺乏对生成式AI信任的计算性、大规模和纵向分析。以往研究主要依赖心理学和人机交互方法,难以捕捉公众对GenAI信任的动态变化和潜在影响因素。因此,需要一种能够大规模分析公众对GenAI信任和不信任的方法,以便更好地理解和管理GenAI的社会影响。
核心思路:本研究的核心思路是利用Reddit等社交媒体平台上的用户讨论数据,结合自然语言处理和机器学习技术,构建一个计算框架,用于大规模分析公众对GenAI的信任和不信任。通过分析用户在Reddit上的帖子和评论,可以了解他们对GenAI的看法、态度和情感,并识别影响信任和不信任的关键因素。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:从Reddit上收集与GenAI相关的帖子和评论数据,涵盖多个subreddit和时间段(2022-2025)。2) 数据标注:对收集到的数据进行众包标注,标注用户对GenAI的信任和不信任程度,以及相关的原因和维度。3) 模型训练:使用标注数据训练分类模型,用于自动识别帖子和评论中的信任和不信任情感。4) 分析与可视化:利用训练好的模型对大规模数据进行分析,识别信任和不信任的趋势、模式和影响因素,并通过可视化工具展示分析结果。
关键创新:本研究的关键创新在于:1) 首次将计算方法应用于大规模分析公众对GenAI的信任和不信任。2) 利用Reddit等社交媒体数据,构建了一个动态、实时的信任分析框架。3) 结合众包标注和机器学习技术,提高了分析的准确性和效率。
关键设计:该研究的关键设计包括:1) 选择Reddit作为数据来源,因为它包含了大量的用户讨论数据,涵盖了各种观点和情感。2) 采用众包标注方法,以获取高质量的标注数据。3) 使用多种分类模型(具体模型未知)进行训练,并选择性能最佳的模型进行分析。4) 分析信任和不信任的原因和维度,例如技术性能、可用性、伦理和社会影响等。(具体参数设置、损失函数、网络结构等技术细节未知)
🖼️ 关键图片

📊 实验亮点
研究发现,公众对GenAI的信任和不信任随着时间的推移几乎是平衡的,并在主要模型发布前后发生变化。技术性能和可用性是影响信任的关键维度,而个人经验是塑造态度的最常见原因。不同用户群体(如专家、伦理学家、普通用户)对GenAI的信任态度存在显著差异。(具体性能数据和提升幅度未知)
🎯 应用场景
该研究成果可应用于多个领域,包括:1) 监测和评估公众对GenAI的信任度,为政策制定者和企业提供决策支持。2) 识别影响信任的关键因素,帮助开发者改进GenAI系统的设计和性能。3) 促进公众对GenAI的理解和认知,减少不必要的恐慌和误解。4) 为AI伦理研究提供数据支持,促进负责任的AI发展。
📄 摘要(原文)
The rise of generative AI (GenAI) has impacted many aspects of human life. As these systems become embedded in everyday practices, understanding public trust in them also becomes essential for responsible adoption and governance. Prior work on trust in AI has largely drawn from psychology and human-computer interaction, but there is a lack of computational, large-scale, and longitudinal approaches to measuring trust and distrust in GenAI and large language models (LLMs). This paper presents the first computational study of Trust and Distrust in GenAI, using a multi-year Reddit dataset (2022--2025) spanning 39 subreddits and 197,618 posts. Crowd-sourced annotations of a representative sample were combined with classification models to scale analysis. We find that Trust and Distrust are nearly balanced over time, with shifts around major model releases. Technical performance and usability dominate as dimensions, while personal experience is the most frequent reason shaping attitudes. Distinct patterns also emerge across trustors (e.g., experts, ethicists, general users). Our results provide a methodological framework for large-scale Trust analysis and insights into evolving public perceptions of GenAI.