Evaluating Prompting Strategies and Large Language Models in Systematic Literature Review Screening: Relevance and Task-Stage Classification
作者: Binglan Han, Anuradha Mathrani, Teo Susnjak
分类: cs.CL, cs.AI
发布日期: 2025-10-17
💡 一句话要点
系统性文献综述筛选自动化:评估提示策略与大语言模型交互作用
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 系统性文献综述 提示工程 自动化筛选 成本效益分析
📋 核心要点
- 系统性文献综述筛选耗时费力,现有方法难以兼顾效率与准确性,尤其是在处理大量文献时。
- 论文探索不同提示策略与大型语言模型的组合,旨在优化文献筛选流程,提高效率并降低成本。
- 实验表明,CoT-少样本提示在精确率和召回率之间取得较好平衡,GPT-4o-mini在成本效益方面表现突出。
📝 摘要(中文)
本研究量化了提示策略与大型语言模型(LLMs)在系统性文献综述(SLRs)筛选阶段自动化的交互作用。我们评估了六个LLM(GPT-4o, GPT-4o-mini, DeepSeek-Chat-V3, Gemini-2.5-Flash, Claude-3.5-Haiku, Llama-4-Maverick)在五种提示类型(零样本、少样本、思维链(CoT)、CoT-少样本、自我反思)下的相关性分类和六个二级任务,使用准确率、精确率、召回率和F1值作为评估指标。结果表明,模型与提示之间存在显著的交互效应:CoT-少样本产生最可靠的精确率-召回率平衡;零样本最大化高敏感性传递的召回率;自我反思由于过度包含和模型间的不稳定性而表现不佳。GPT-4o和DeepSeek提供了强大的整体性能,而GPT-4o-mini以显著更低的成本提供了具有竞争力的性能。对相关性分类的成本-性能分析(每1000篇摘要)揭示了模型-提示配对之间存在巨大的绝对差异;GPT-4o-mini在各种提示下仍然是低成本的,而GPT-4o-mini上的结构化提示(CoT/CoT-少样本)以较小的增量成本提供了有吸引力的F1值。我们推荐一个分阶段的工作流程,该流程(1)部署具有结构化提示的低成本模型进行第一遍筛选,并且(2)仅将边缘案例升级到更高容量的模型。这些发现突出了LLM在自动化文献筛选方面不均衡但充满希望的潜力。通过系统地分析提示-模型交互,我们为任务自适应LLM部署提供了一个比较基准和实践指导。
🔬 方法详解
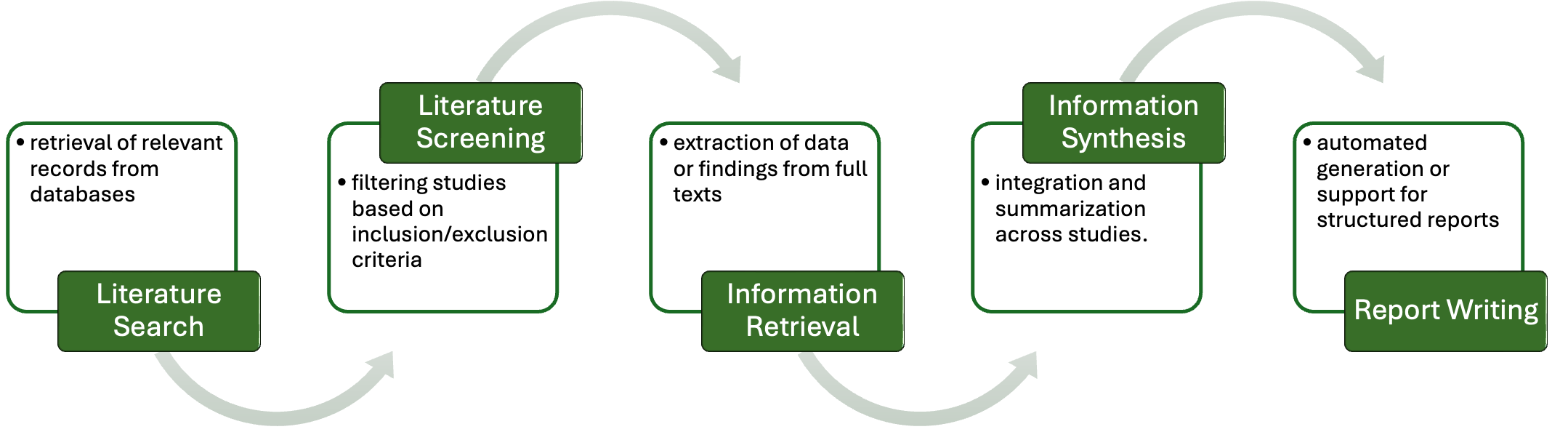
问题定义:系统性文献综述(SLR)的筛选阶段需要人工阅读大量文献摘要,判断其是否与研究主题相关。这个过程耗时且容易出错。现有的自动化方法,如传统的机器学习模型,可能无法充分理解文献的语义信息,导致筛选结果的准确性不高。此外,不同文献的表达方式各异,使得模型难以泛化到新的文献集上。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的语义理解和生成能力,结合不同的提示策略,来自动化SLR的筛选过程。通过精心设计的提示,引导LLM理解文献摘要并做出准确的判断。同时,通过比较不同LLM和提示策略的组合,找到最佳的解决方案。
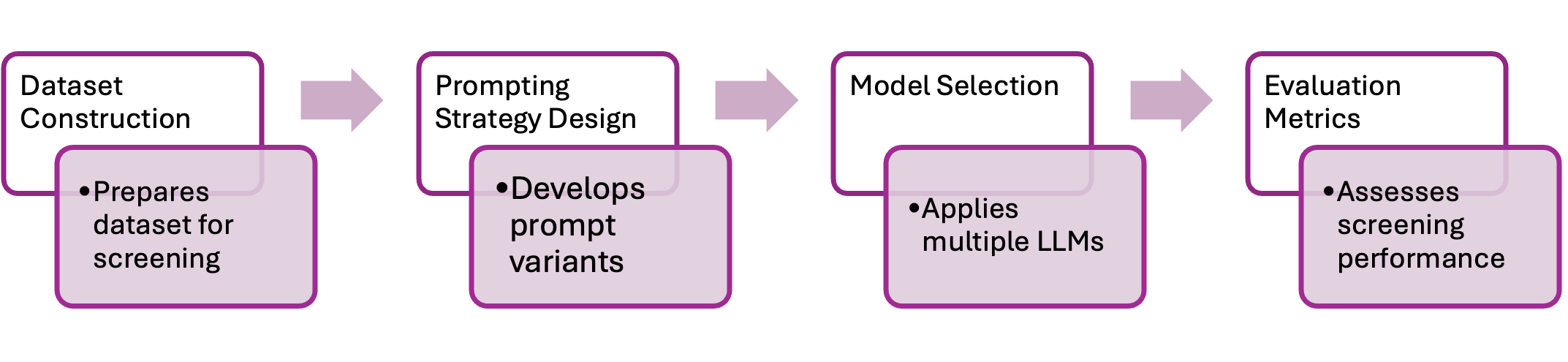
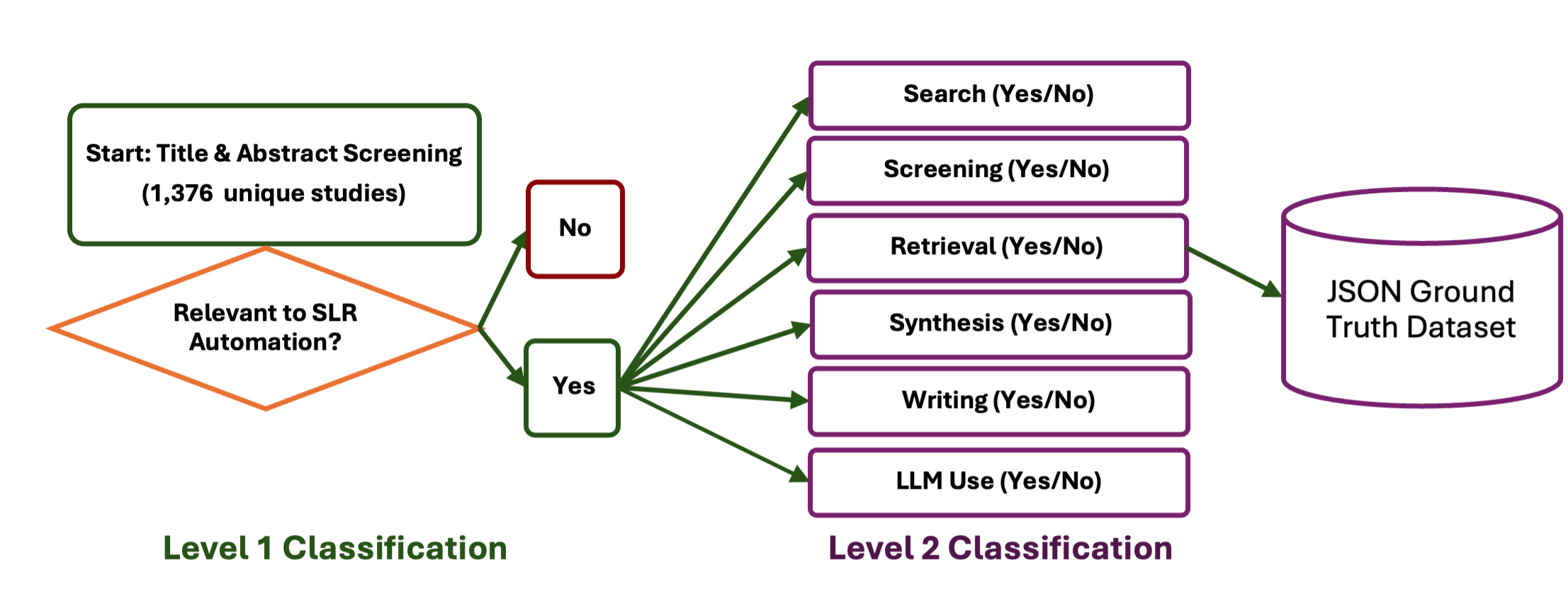
技术框架:该研究的技术框架主要包括以下几个部分:1) 选择六个具有代表性的LLM,包括GPT-4o, GPT-4o-mini, DeepSeek-Chat-V3, Gemini-2.5-Flash, Claude-3.5-Haiku, Llama-4-Maverick;2) 设计五种不同的提示策略,包括零样本、少样本、思维链(CoT)、CoT-少样本和自我反思;3) 使用标准的SLR数据集,对LLM和提示策略的组合进行评估;4) 使用准确率、精确率、召回率和F1值等指标,对筛选结果进行量化分析;5) 进行成本-性能分析,评估不同方案的经济效益。
关键创新:该研究的关键创新在于系统地评估了不同LLM和提示策略在SLR筛选任务中的表现,并揭示了它们之间的交互效应。通过比较不同方案的性能和成本,为实际应用提供了有价值的指导。此外,该研究还提出了一个分阶段的工作流程,可以根据不同的需求选择合适的LLM和提示策略。
关键设计:提示策略的设计是该研究的关键。例如,思维链(CoT)提示通过引导LLM逐步推理,可以提高筛选结果的准确性。少样本提示通过提供一些示例,可以帮助LLM更好地理解任务。自我反思提示则试图让LLM评估自己的判断,并进行修正。此外,成本-性能分析也考虑了不同LLM的API调用费用,从而为实际应用提供了更全面的参考。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GPT-4o和DeepSeek在整体性能上表现出色,GPT-4o-mini在成本效益方面具有优势。CoT-少样本提示策略在精确率和召回率之间取得了较好的平衡。对于高敏感性筛选,零样本提示可以最大化召回率。成本分析显示,GPT-4o-mini结合结构化提示(CoT/CoT-少样本)可在较低成本下实现较好的F1值。
🎯 应用场景
该研究成果可应用于医学、工程、社会科学等多个领域的系统性文献综述,加速文献筛选过程,降低人工成本,并提高综述质量。未来,该方法可扩展到其他文本分类任务,如专利分析、新闻过滤等。
📄 摘要(原文)
This study quantifies how prompting strategies interact with large language models (LLMs) to automate the screening stage of systematic literature reviews (SLRs). We evaluate six LLMs (GPT-4o, GPT-4o-mini, DeepSeek-Chat-V3, Gemini-2.5-Flash, Claude-3.5-Haiku, Llama-4-Maverick) under five prompt types (zero-shot, few-shot, chain-of-thought (CoT), CoT-few-shot, self-reflection) across relevance classification and six Level-2 tasks, using accuracy, precision, recall, and F1. Results show pronounced model-prompt interaction effects: CoT-few-shot yields the most reliable precision-recall balance; zero-shot maximizes recall for high-sensitivity passes; and self-reflection underperforms due to over-inclusivity and instability across models. GPT-4o and DeepSeek provide robust overall performance, while GPT-4o-mini performs competitively at a substantially lower dollar cost. A cost-performance analysis for relevance classification (per 1,000 abstracts) reveals large absolute differences among model-prompt pairings; GPT-4o-mini remains low-cost across prompts, and structured prompts (CoT/CoT-few-shot) on GPT-4o-mini offer attractive F1 at a small incremental cost. We recommend a staged workflow that (1) deploys low-cost models with structured prompts for first-pass screening and (2) escalates only borderline cases to higher-capacity models. These findings highlight LLMs' uneven but promising potential to automate literature screening. By systematically analyzing prompt-model interactions, we provide a comparative benchmark and practical guidance for task-adaptive LLM deployment.