Can LLMs Correct Themselves? A Benchmark of Self-Correction in LLMs
作者: Guiyao Tie, Zenghui Yuan, Zeli Zhao, Chaoran Hu, Tianhe Gu, Ruihang Zhang, Sizhe Zhang, Junran Wu, Xiaoyue Tu, Ming Jin, Qingsong Wen, Lixing Chen, Pan Zhou, Lichao Sun
分类: cs.CL, cs.AI
发布日期: 2025-10-17 (更新: 2025-10-22)
备注: 47 pages, 25 figures, 10 tables
💡 一句话要点
CorrectBench:评估大语言模型自纠错能力的综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自纠错 基准测试 常识推理 数学推理 代码生成 思维链 效率优化
📋 核心要点
- 现有自纠错方法缺乏全面评估,难以判断LLM是否真正具备自纠错能力。
- 提出CorrectBench基准,系统评估内在、外在和微调三种自纠错策略的有效性。
- 实验表明自纠错能提升复杂推理任务准确性,但混合策略会降低效率,CoT基线表现出色。
📝 摘要(中文)
大型语言模型(LLM)的自纠错能力已成为提高其推理性能的关键组成部分。尽管已经提出了各种自纠错方法,但对这些方法的全面评估在很大程度上仍未被探索,并且LLM是否能够真正纠正自身错误是一个备受关注的问题。本研究推出了CorrectBench,这是一个旨在评估自纠错策略有效性的基准,包括内在方法、外在方法和微调方法,涵盖常识推理、数学推理和代码生成三个任务。研究结果表明:1)自纠错方法可以提高准确性,尤其是在复杂的推理任务中;2)混合不同的自纠错策略可以带来进一步的改进,尽管会降低效率;3)推理型LLM(例如DeepSeek-R1)在额外的自纠错方法下优化空间有限,并且时间成本很高。有趣的是,一个相对简单的思维链(CoT)基线表现出具有竞争力的准确性和效率。这些结果强调了自纠错在增强LLM推理性能方面的潜力,同时也突出了提高其效率的持续挑战。因此,我们提倡进一步研究,重点关注优化推理能力和运营效率之间的平衡。
🔬 方法详解
问题定义:论文旨在解决如何全面评估大型语言模型(LLM)的自纠错能力的问题。现有自纠错方法缺乏统一的评估标准和全面的测试,难以有效衡量其性能,并且效率问题也未得到充分关注。
核心思路:论文的核心思路是构建一个名为CorrectBench的基准测试,该基准包含多种自纠错策略(内在、外在和微调)和多个任务(常识推理、数学推理和代码生成),从而对LLM的自纠错能力进行多维度、系统性的评估。
技术框架:CorrectBench基准测试主要包含以下几个部分:1)任务数据集:涵盖常识推理、数学推理和代码生成三个任务,每个任务包含多个测试用例。2)自纠错策略:包括内在方法(例如,使用不同的解码策略)、外在方法(例如,利用外部知识库)和微调方法(例如,使用自纠错数据进行微调)。3)评估指标:包括准确率、效率(例如,推理时间)等指标,用于全面评估自纠错策略的性能。
关键创新:该论文的关键创新在于构建了一个综合性的自纠错基准测试CorrectBench,它不仅涵盖了多种自纠错策略和任务,还考虑了效率因素,从而能够更全面、客观地评估LLM的自纠错能力。与以往的研究相比,CorrectBench提供了一个统一的平台,方便研究人员比较不同自纠错方法的性能。
关键设计:CorrectBench的关键设计包括:1)任务选择:选择常识推理、数学推理和代码生成三个任务,以覆盖LLM的不同推理能力。2)自纠错策略选择:选择内在、外在和微调三种自纠错策略,以涵盖不同的自纠错机制。3)评估指标设计:除了准确率之外,还考虑了效率指标,以全面评估自纠错策略的性能。具体的参数设置和损失函数取决于所使用的自纠错方法。
🖼️ 关键图片
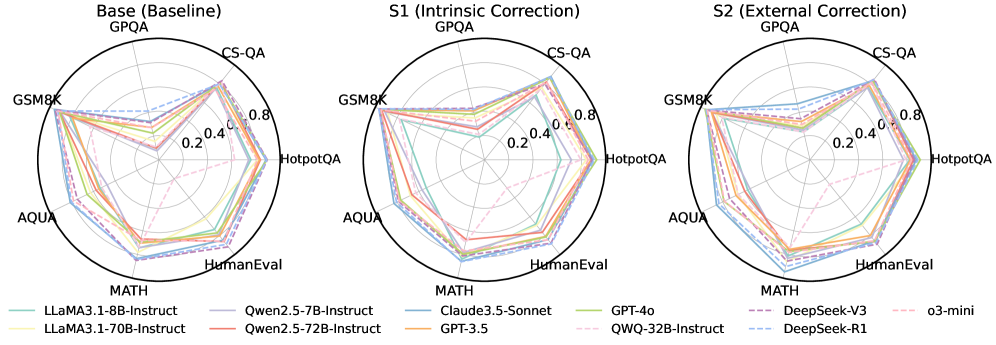
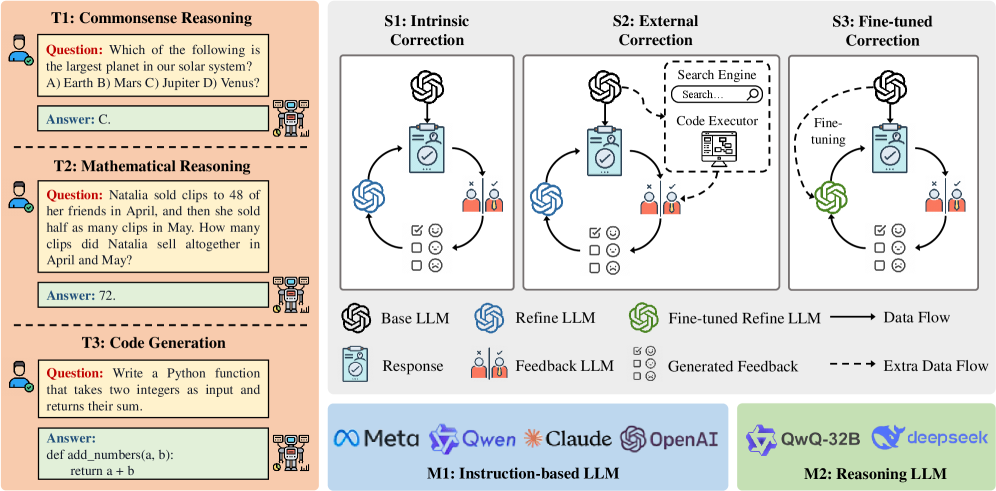
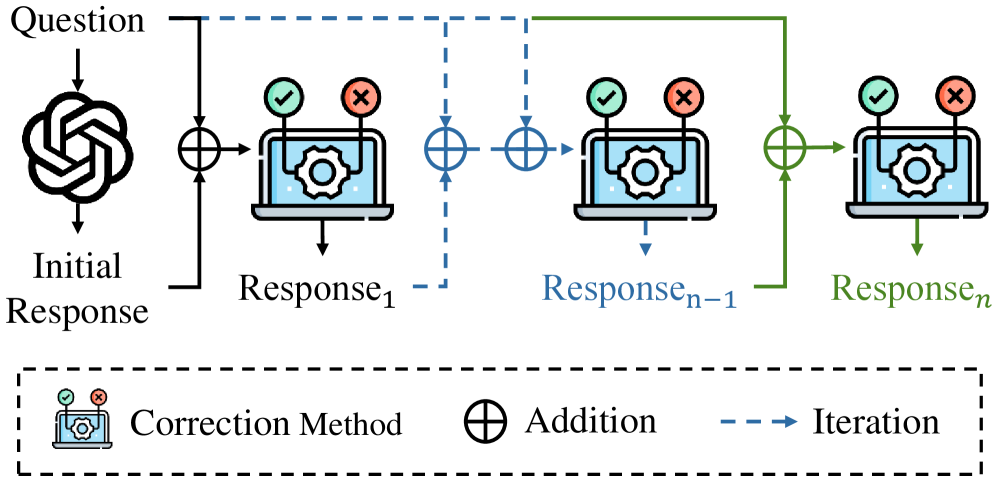
📊 实验亮点
CorrectBench的实验结果表明,自纠错方法可以提高LLM在复杂推理任务中的准确性。混合不同的自纠错策略可以进一步提升性能,但会降低效率。令人惊讶的是,简单的思维链(CoT)基线在准确性和效率方面表现出色。DeepSeek-R1等推理型LLM在额外的自纠错方法下优化空间有限,且时间成本较高。
🎯 应用场景
该研究成果可应用于提升大语言模型在各种推理任务中的性能,例如智能问答、数学问题求解和代码生成。通过使用有效的自纠错策略,可以提高LLM的可靠性和准确性,从而使其在实际应用中更具价值。未来的研究可以进一步探索如何优化自纠错策略的效率,使其能够在资源受限的环境中部署。
📄 摘要(原文)
Self-correction of large language models (LLMs) emerges as a critical component for enhancing their reasoning performance. Although various self-correction methods have been proposed, a comprehensive evaluation of these methods remains largely unexplored, and the question of whether LLMs can truly correct themselves is a matter of significant interest and concern. In this study, we introduce CorrectBench, a benchmark developed to evaluate the effectiveness of self-correction strategies, including intrinsic, external, and fine-tuned approaches, across three tasks: commonsense reasoning, mathematical reasoning, and code generation. Our findings reveal that: 1) Self-correction methods can improve accuracy, especially for complex reasoning tasks; 2) Mixing different self-correction strategies yields further improvements, though it reduces efficiency; 3) Reasoning LLMs (e.g., DeepSeek-R1) have limited optimization under additional self-correction methods and have high time costs. Interestingly, a comparatively simple chain-of-thought (CoT) baseline demonstrates competitive accuracy and efficiency. These results underscore the potential of self-correction to enhance LLM's reasoning performance while highlighting the ongoing challenge of improving their efficiency. Consequently, we advocate for further research focused on optimizing the balance between reasoning capabilities and operational efficiency. Project Page: https://correctbench.github.io/