InfiMed-ORBIT: Aligning LLMs on Open-Ended Complex Tasks via Rubric-Based Incremental Training
作者: Pengkai Wang, Linus, Pengwei Liu, Zhijie Sang, Congkai Xie, Hongxia Yang
分类: cs.CL, cs.AI
发布日期: 2025-10-17 (更新: 2025-11-28)
💡 一句话要点
InfiMed-ORBIT:通过基于规则的增量训练对齐LLM,解决开放式复杂医疗任务
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 医疗对话 规则驱动 增量训练
📋 核心要点
- 现有强化学习方法在开放式医疗咨询等领域表现不佳,因为反馈模糊且难以转化为可靠的标量信号。
- ORBIT框架通过动态构建的规则,为增量强化学习提供自适应指导,无需外部知识库或手工规则。
- 实验表明,ORBIT在HealthBench-Hard上显著提升了模型性能,并展示了其在InfoBench上的通用性。
📝 摘要(中文)
本文提出ORBIT,一个面向高风险医疗对话的开放式、基于规则的增量训练框架。ORBIT集成了合成对话生成和动态构建的规则,这些规则作为增量强化学习的自适应指导。ORBIT不依赖于外部医学知识库或手工规则集,而是使用规则驱动的反馈来引导学习过程。其判断组件可以使用通用指令遵循LLM实例化,无需任何特定于任务的微调。应用于Qwen3-4B-Instruct模型,ORBIT仅使用2k训练样本就将HealthBench-Hard评分从7.0提高到27.5,实现了该规模模型的SOTA性能。通过更大的规则数据集,ORBIT训练的模型在HealthBench-Hard上进一步与最强的开源基线竞争。分析表明,规则引导的RL始终提高各种医疗场景下的咨询质量。还将这种规则生成和训练管道应用于InfoBench,ORBIT增强了指令遵循性能,突出了基于规则的反馈的通用性。
🔬 方法详解
问题定义:现有强化学习方法在开放式医疗咨询等复杂任务中面临挑战。由于医疗咨询的反馈具有内在的模糊性、高度依赖上下文,且难以简化为可靠的标量奖励信号,传统的强化学习方法要么依赖于需要大量监督且泛化能力差的奖励模型,要么容易陷入奖励操纵等病态行为,这在高风险的医疗对话场景中尤其危险。
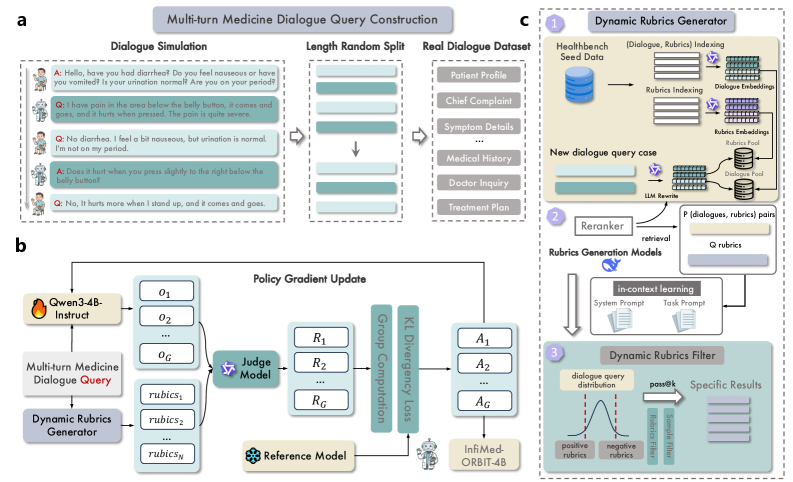
核心思路:ORBIT的核心思路是利用动态构建的规则(rubrics)作为自适应的指导,来引导强化学习过程。这些规则不是预先定义好的,而是随着训练的进行动态生成的,从而能够更好地适应任务的复杂性和变化。通过规则驱动的反馈,模型可以学习到更细粒度、更准确的策略,避免了对外部知识库或手工规则的依赖。
技术框架:ORBIT框架包含三个主要组件:合成对话生成器、动态规则生成器和强化学习训练器。首先,合成对话生成器生成模拟的医疗咨询对话。然后,动态规则生成器根据对话内容和预定义的评估标准,生成相应的规则。最后,强化学习训练器使用这些规则作为奖励信号,对语言模型进行增量训练。整个过程迭代进行,规则不断更新,模型性能逐步提升。
关键创新:ORBIT的关键创新在于使用动态生成的规则来指导强化学习,而不是依赖于静态的奖励模型或手工规则。这种方法能够更好地适应开放式任务的复杂性和变化,避免了奖励操纵等问题。此外,ORBIT的判断组件可以使用通用的指令遵循LLM实例化,无需针对特定任务进行微调,降低了开发成本。
关键设计:ORBIT使用Qwen3-4B-Instruct模型作为基础模型,并采用增量强化学习的方式进行训练。规则生成器使用LLM根据对话内容和预定义的评估标准生成规则。强化学习训练器使用生成的规则作为奖励信号,优化模型的策略。训练过程中,规则数据集不断扩大,模型性能逐步提升。具体参数设置和损失函数等细节未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ORBIT框架在HealthBench-Hard数据集上取得了显著的性能提升。仅使用2k训练样本,ORBIT就将Qwen3-4B-Instruct模型的评分从7.0提高到27.5,达到了同等规模模型的SOTA水平。通过使用更大的规则数据集,ORBIT训练的模型甚至可以与更强大的开源基线模型相媲美。此外,ORBIT在InfoBench数据集上也表现出良好的泛化能力,证明了其在不同任务上的有效性。
🎯 应用场景
ORBIT框架可应用于各种开放式、高风险的对话场景,例如医疗咨询、法律咨询、心理咨询等。通过提供更准确、更可靠的反馈信号,ORBIT可以帮助语言模型更好地理解用户需求,生成更符合要求的回复,从而提高咨询质量和用户满意度。该研究的成果有助于推动人工智能在专业领域的应用,并为构建更安全、更可靠的智能对话系统奠定基础。
📄 摘要(原文)
Reinforcement learning has powered many of the recent breakthroughs in large language models, especially for tasks where rewards can be computed automatically, such as code generation. However, these methods deteriorate in open-ended domains like medical consultation, where feedback is inherently ambiguous, highly context-dependent, and cannot be reduced to a reliable scalar signal. In such settings, RL must either rely on supervision-intensive reward models that often fail to generalize, or it falls into pathological behaviors such as reward hacking - an especially troubling risk for high-stakes medical dialogue. To address these limitations, we introduce ORBIT, an open-ended rubric-based incremental training framework for high-stakes medical dialogue. ORBIT integrates synthetic dialogue generation with dynamically constructed rubrics that serve as adaptive guides for incremental RL. Instead of relying on external medical knowledge bases or handcrafted rule sets, ORBIT uses rubric-driven feedback to steer the learning process. Its judge component can be instantiated with general-purpose instruction-following LLMs, removing the need for any task-specific fine-tuning. Applied to the Qwen3-4B-Instruct model, ORBIT raises the HealthBench-Hard score from 7.0 to 27.5 using only 2k training samples, achieving SOTA performance for models at this scale. With larger rubric datasets, ORBIT-trained models further compete with the strongest open-source baselines on HealthBench-Hard. Our analysis shows that rubric-guided RL consistently improves consultation quality across diverse medical scenarios. We also apply such rubric generation and training pipeline to InfoBench, where ORBIT enhances instruction-following performance, highlighting the generality of rubric-based feedback.