SpeechLLMs for Large-scale Contextualized Zero-shot Slot Filling
作者: Kadri Hacioglu, Manjunath K E, Andreas Stolcke
分类: cs.CL, cs.LG
发布日期: 2025-10-17
备注: 13 pages, EMNLP 2025
💡 一句话要点
利用语音大语言模型进行大规模上下文零样本槽填充
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 槽填充 零样本学习 口语理解 指令微调
📋 核心要点
- 传统槽填充方法依赖语音识别和自然语言理解模块的级联,存在误差传递和模块间优化困难的问题。
- 论文探索利用语音大语言模型(speechLLMs)直接进行端到端槽填充,实现零样本泛化能力。
- 通过改进训练数据、模型架构和训练策略,显著提升了speechLLMs在槽填充任务上的性能。
📝 摘要(中文)
槽填充是口语理解(SLU)中的一个关键子任务,传统上通过语音识别以及一个或多个自然语言理解(NLU)组件的级联来实现。最近,基于语音的大型语言模型(speechLLMs)的出现,整合了语音和文本基础模型,为以更统一、生成式和指令跟随的方式实现语音理解任务开辟了新途径,同时有望通过零样本能力提高数据和计算效率,并泛化到未见过的槽标签。我们通过为该任务创建一个经验上限,识别性能、鲁棒性和泛化差距,并提出对训练数据、架构和训练策略的改进,以缩小与上限结果的差距来解决槽填充任务。我们表明,这些措施中的每一项都大大提高了性能,同时强调了实际挑战,并为利用这些新兴模型提供了经验指导和见解。
🔬 方法详解
问题定义:论文旨在解决口语理解中的槽填充问题。传统方法通常依赖于语音识别(ASR)和自然语言理解(NLU)模块的串联,这种方式存在误差累积,且各个模块需要单独优化,难以实现端到端的优化。此外,传统方法在面对未见过的槽标签时,泛化能力较弱。
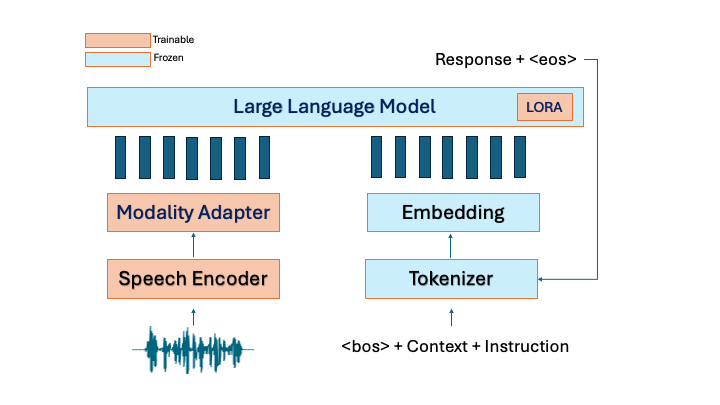
核心思路:论文的核心思路是利用近年来兴起的语音大语言模型(speechLLMs),直接从语音输入生成槽填充结果。SpeechLLMs集成了语音和文本基础模型,具备强大的生成能力和指令跟随能力,可以通过零样本学习的方式泛化到未见过的槽标签。通过优化训练数据、模型架构和训练策略,可以进一步提升speechLLMs在槽填充任务上的性能。
技术框架:论文提出的方法主要包含以下几个部分:1) 数据准备:构建或选择合适的语音-文本数据对,用于训练speechLLMs。2) 模型选择:选择合适的speechLLM作为基础模型,例如基于Transformer的架构。3) 训练策略:设计合适的训练目标和优化算法,例如使用指令微调(instruction tuning)的方式,让模型学习如何根据指令进行槽填充。4) 评估:使用标准的槽填充评估指标,例如F1值,评估模型在测试集上的性能。
关键创新:论文的关键创新在于探索了speechLLMs在零样本槽填充任务上的潜力,并提出了改进训练数据、模型架构和训练策略的方法,以提升speechLLMs的性能。与传统方法相比,该方法无需单独训练ASR和NLU模块,可以实现端到端的优化,并具备更强的泛化能力。
关键设计:论文的关键设计可能包括:1) 训练数据的选择和增强,例如使用数据增强技术生成更多的语音-文本数据对。2) 模型架构的调整,例如在speechLLM中引入额外的注意力机制,以更好地捕捉语音和文本之间的关系。3) 训练目标的优化,例如使用对比学习的方式,让模型学习区分不同的槽标签。4) 指令的设计,例如使用清晰明确的指令,引导模型进行槽填充。
🖼️ 关键图片
📊 实验亮点
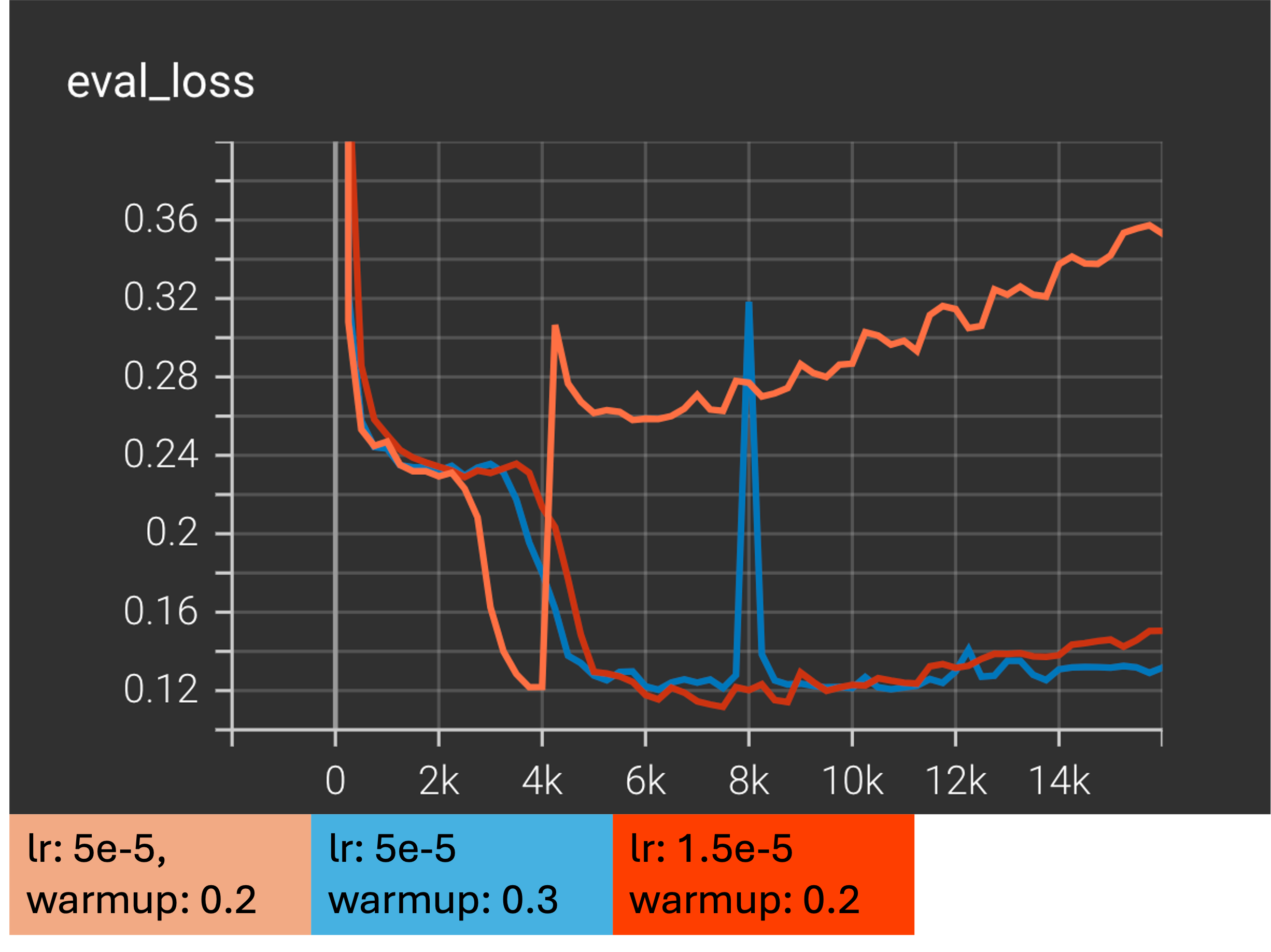
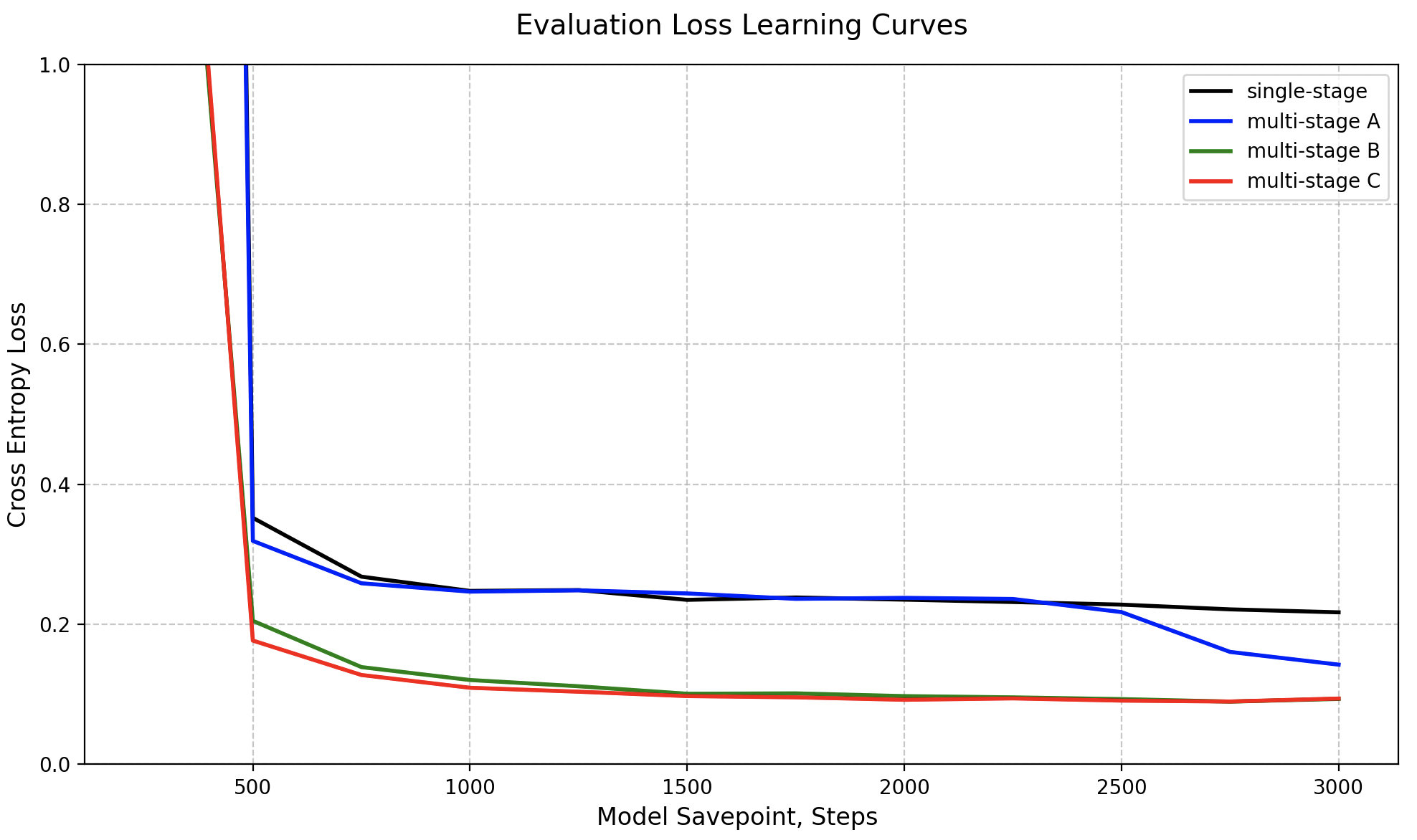
论文通过实验验证了改进训练数据、模型架构和训练策略对speechLLMs在槽填充任务上的性能提升。具体性能数据未知,但摘要中提到每项改进措施都显著提高了性能,并缩小了与经验上限结果的差距。这表明speechLLMs在零样本槽填充任务上具有很大的潜力。
🎯 应用场景
该研究成果可应用于智能助手、语音搜索、自动客服等领域。通过利用语音大语言模型,可以实现更自然、更智能的语音交互体验。未来,该技术有望在智能家居、车载系统等领域得到广泛应用,提升人机交互的效率和便捷性。
📄 摘要(原文)
Slot filling is a crucial subtask in spoken language understanding (SLU), traditionally implemented as a cascade of speech recognition followed by one or more natural language understanding (NLU) components. The recent advent of speech-based large language models (speechLLMs), which integrate speech and textual foundation models, has opened new avenues for achieving speech understanding tasks in a more unified, generative, and instruction-following manner while promising data and compute efficiency with zero-shot abilities, generalizing to unseen slot labels. We address the slot-filling task by creating an empirical upper bound for the task, identifying performance, robustness, and generalization gaps, and proposing improvements to the training data, architecture, and training strategies to narrow the gap with the upper bound result. We show that each of these measures improve performance substantially, while highlighting practical challenges and providing empirical guidance and insights for harnessing these emerging models.