Emergence of Linear Truth Encodings in Language Models
作者: Shauli Ravfogel, Gilad Yehudai, Tal Linzen, Joan Bruna, Alberto Bietti
分类: cs.CL
发布日期: 2025-10-17
备注: Accepted in Neurips 2025
💡 一句话要点
提出透明Transformer玩具模型,揭示语言模型中线性真值编码涌现机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 真值编码 Transformer 可解释性 线性探针
📋 核心要点
- 现有研究表明语言模型能区分真假,但其内在机制尚不清晰,面临挑战。
- 论文构建了一个透明的单层Transformer玩具模型,模拟真值子空间的涌现过程。
- 实验表明,模型先记忆事实关联,再学习线性分离真假,降低语言模型损失。
📝 摘要(中文)
近期的研究表明,大型语言模型存在线性子空间,可以将真假陈述区分开来,但其涌现机制尚不明确。本文提出了一个透明的单层Transformer玩具模型,可以端到端地重现这种真值子空间,并揭示了其产生的一种具体途径。研究了一种简单的场景,其中事实陈述与其他事实陈述共同出现(反之亦然),从而鼓励模型学习这种区分,以降低未来token的语言模型损失。通过在预训练语言模型中进行的实验证实了这种模式。最后,在玩具模型中观察到两阶段学习动态:网络首先在几个步骤中记忆单个事实关联,然后在更长的时间范围内学习线性地分离真假,这反过来又降低了语言建模损失。总之,这些结果为线性真值表示如何在语言模型中涌现提供了机制演示和经验动机。
🔬 方法详解
问题定义:论文旨在理解大型语言模型中线性真值编码(linear truth encodings)涌现的机制。现有方法缺乏透明性和可解释性,难以揭示真值编码是如何在模型中形成的。因此,需要一个可控的环境来研究这一现象。
核心思路:论文的核心思路是构建一个简化的、透明的Transformer模型(即玩具模型),并设计特定的数据分布,使得模型在训练过程中能够自发地学习到区分真假陈述的能力。通过分析这个玩具模型的内部表示,可以揭示真值编码涌现的具体机制。
技术框架:该研究的技术框架主要包含以下几个部分:1) 构建一个单层Transformer玩具模型;2) 设计一个数据分布,其中事实陈述与其他事实陈述共同出现,而非事实陈述与其他非事实陈述共同出现;3) 使用该数据分布训练玩具模型;4) 分析模型学习到的表示,特别是是否存在线性子空间可以将真假陈述区分开来;5) 在预训练语言模型上进行实验,验证玩具模型中的发现。
关键创新:论文的关键创新在于:1) 提出了一个透明的、可解释的玩具模型,用于研究真值编码的涌现;2) 揭示了一种具体的机制,即通过事实陈述之间的共现关系,模型可以学习到区分真假的能力;3) 观察到两阶段学习动态,即模型先记忆事实关联,再学习线性分离真假。
关键设计:玩具模型是一个单层Transformer,使用标准的多头注意力机制和前馈网络。数据分布的设计至关重要,它需要保证事实陈述之间存在一定的关联性,而非事实陈述之间也存在一定的关联性。损失函数采用标准的语言模型损失,即预测下一个token的交叉熵损失。实验中还使用了线性探针(linear probe)来分析模型学习到的表示,即训练一个线性分类器来区分真假陈述。
🖼️ 关键图片
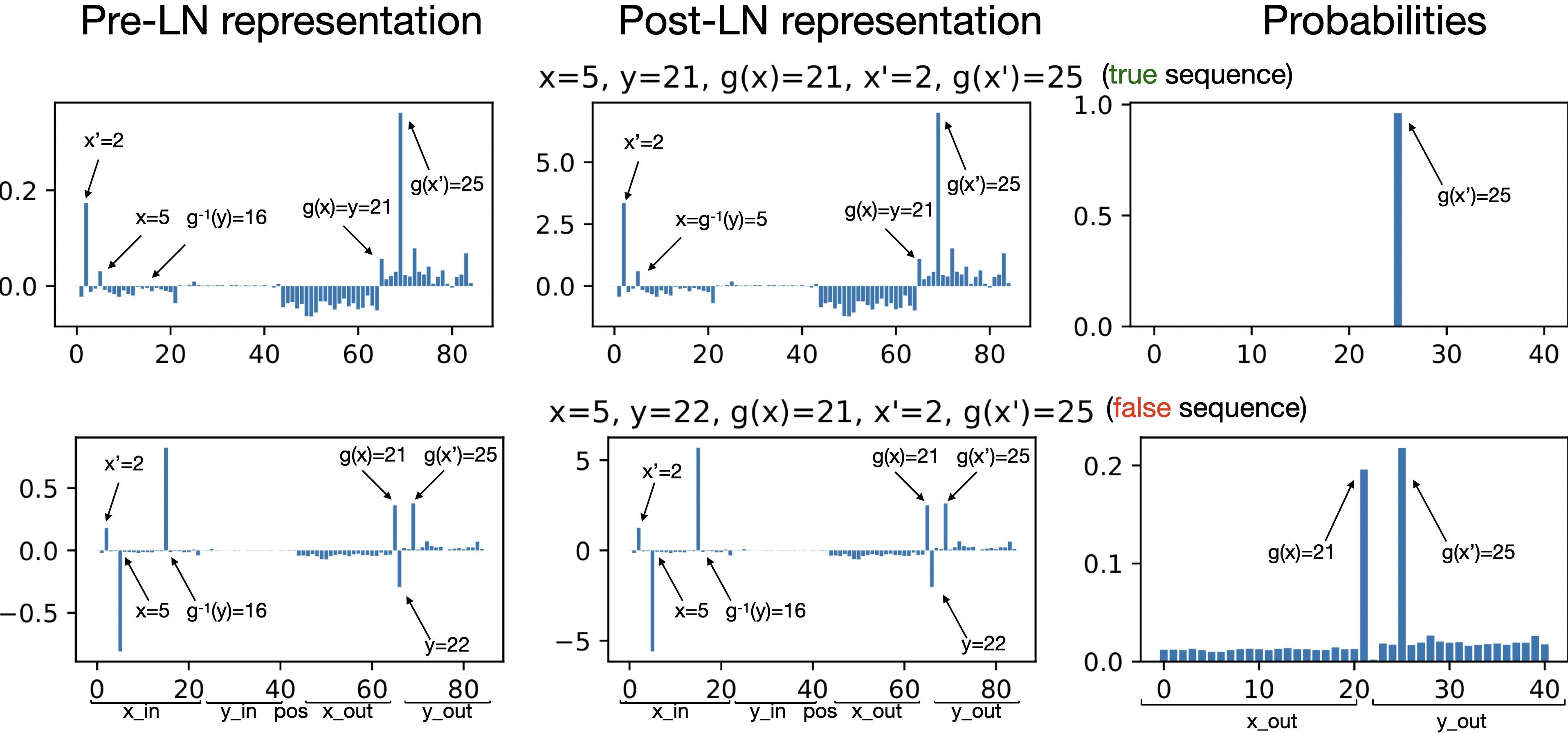

📊 实验亮点
实验结果表明,玩具模型能够成功学习到线性真值编码,并且这种编码的涌现与事实陈述之间的共现关系密切相关。在预训练语言模型上的实验也验证了这一发现。此外,研究还观察到两阶段学习动态,即模型先记忆事实关联,再学习线性分离真假,这为理解语言模型的学习过程提供了新的视角。
🎯 应用场景
该研究成果有助于提升语言模型的可解释性和可控性,并为开发更可靠、更值得信任的AI系统奠定基础。理解真值编码的涌现机制,可以帮助我们设计更好的训练方法,避免模型学习到错误的知识或产生有害的偏见。此外,该研究还可以应用于知识图谱构建、事实核查等领域。
📄 摘要(原文)
Recent probing studies reveal that large language models exhibit linear subspaces that separate true from false statements, yet the mechanism behind their emergence is unclear. We introduce a transparent, one-layer transformer toy model that reproduces such truth subspaces end-to-end and exposes one concrete route by which they can arise. We study one simple setting in which truth encoding can emerge: a data distribution where factual statements co-occur with other factual statements (and vice-versa), encouraging the model to learn this distinction in order to lower the LM loss on future tokens. We corroborate this pattern with experiments in pretrained language models. Finally, in the toy setting we observe a two-phase learning dynamic: networks first memorize individual factual associations in a few steps, then -- over a longer horizon -- learn to linearly separate true from false, which in turn lowers language-modeling loss. Together, these results provide both a mechanistic demonstration and an empirical motivation for how and why linear truth representations can emerge in language models.