Rethinking Cross-lingual Gaps from a Statistical Viewpoint
作者: Vihari Piratla, Purvam Jain, Darshan Singh, Partha Talukdar, Trevor Cohn
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-17
备注: 22 pages
💡 一句话要点
从统计视角重新审视跨语言差距,并提出方差控制方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 跨语言学习 大型语言模型 偏差-方差分解 方差控制 推理时干预
📋 核心要点
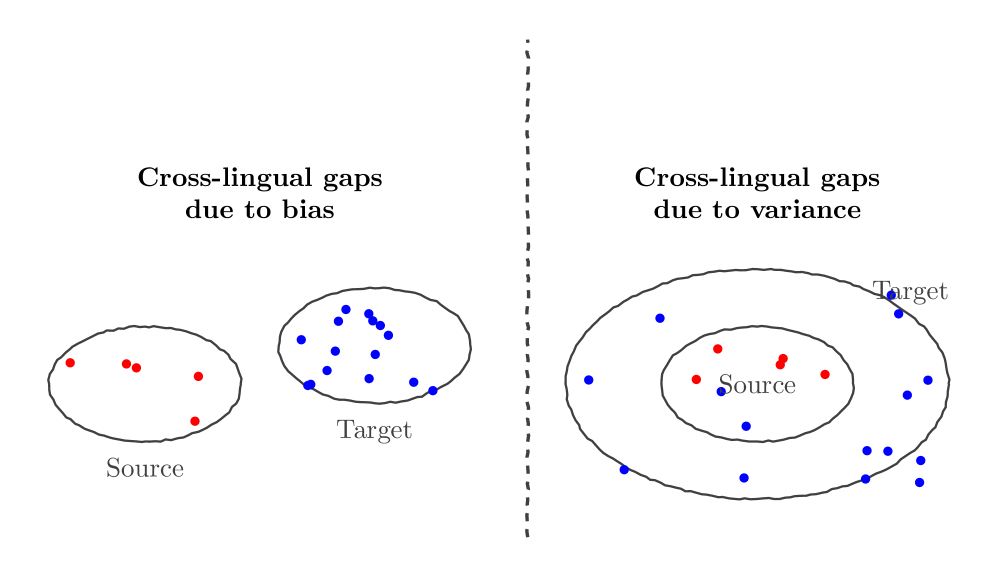
- 现有研究认为跨语言差距源于源语言和目标语言的潜在表示差异,但缺乏直接证据。
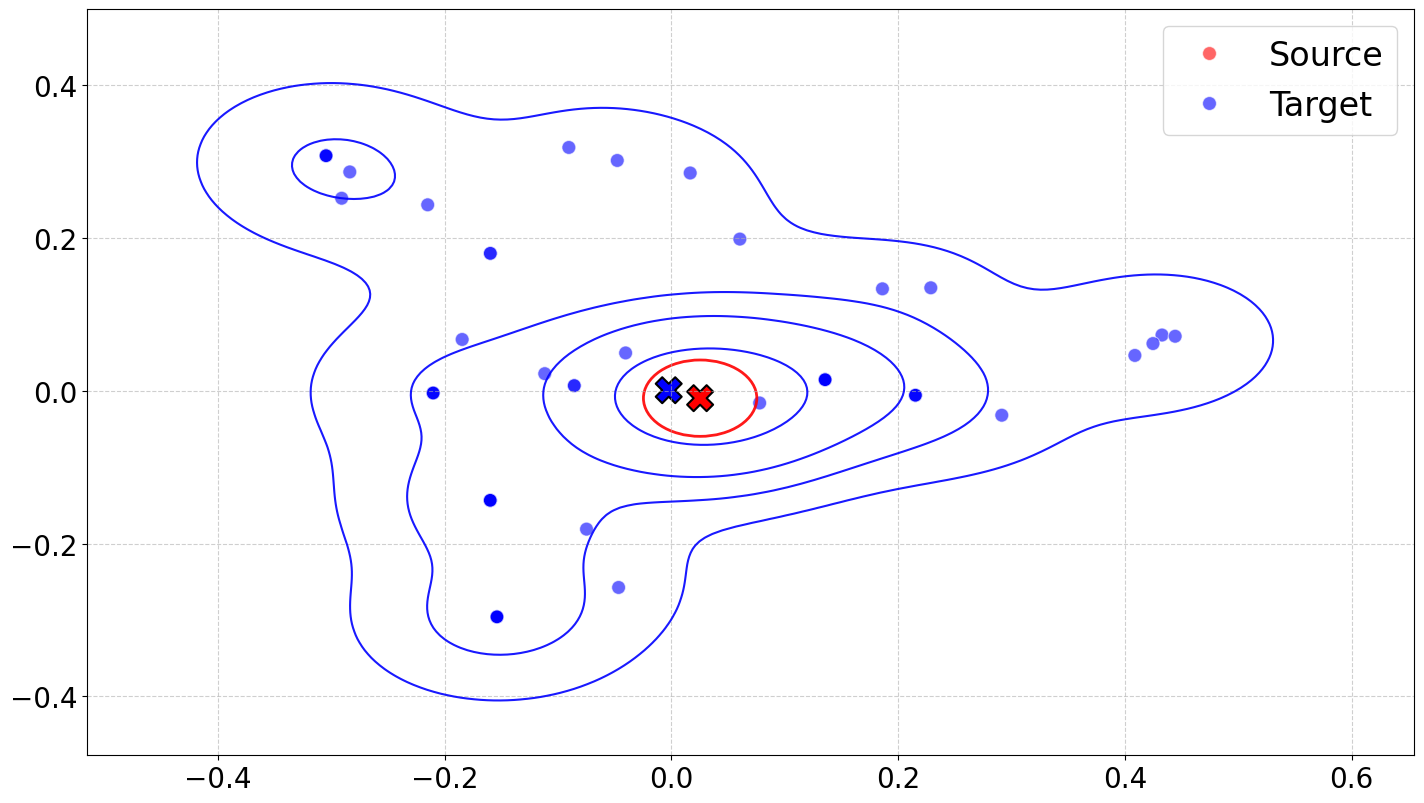
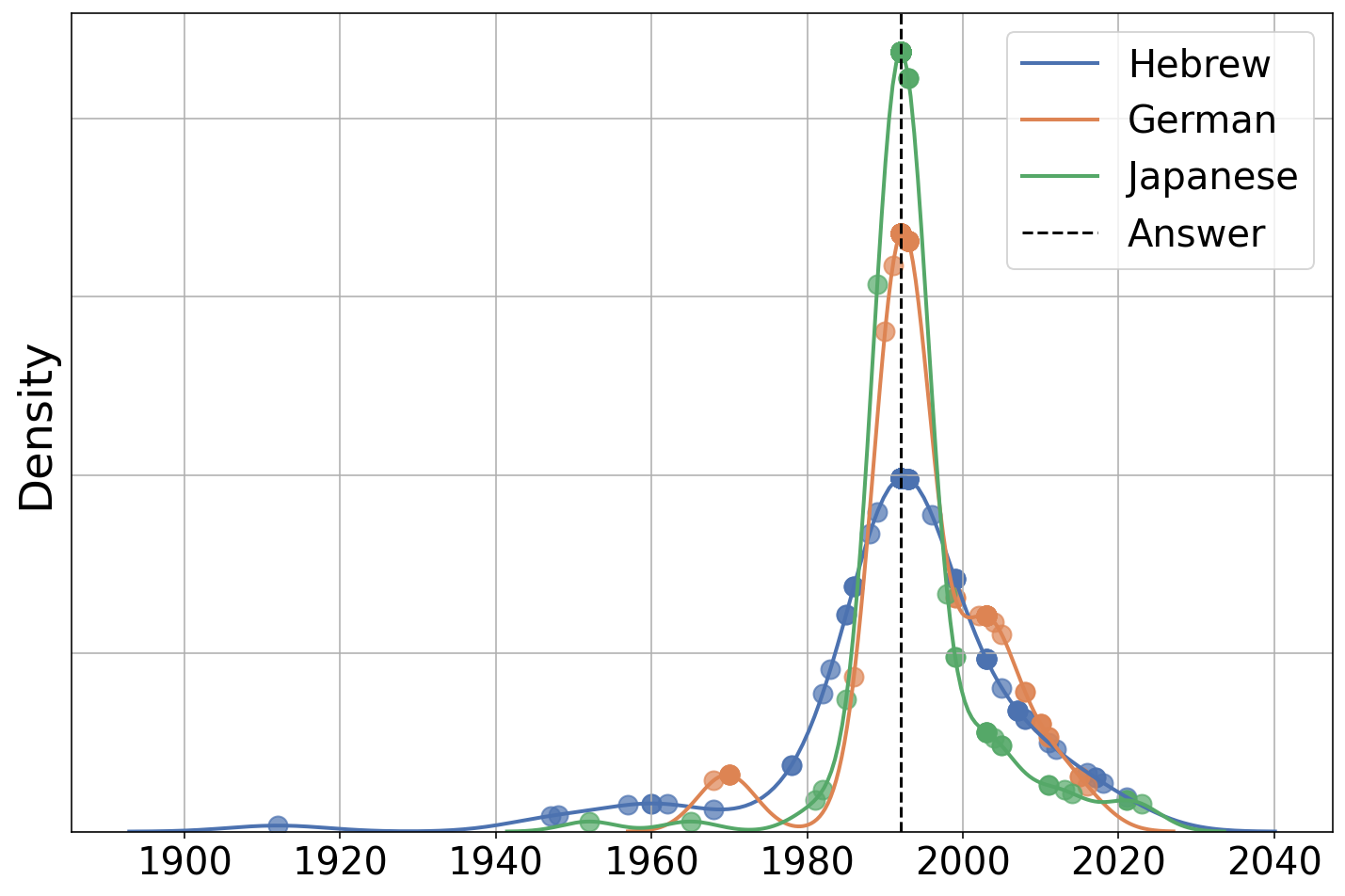
- 该论文假设目标语言响应的方差是跨语言差距的主要原因,并用偏差-方差分解进行形式化。
- 实验表明,控制响应方差能有效减小跨语言差距,简单的prompt指令即可提升目标语言准确率。
📝 摘要(中文)
大型语言模型(LLM)能够从源语言获取知识,并在目标语言查询时提供服务,从而充当桥梁。然而,现有研究表明存在跨语言差距,即使用目标语言查询知识时,准确率会低于使用源语言查询。以往研究将源语言和目标语言潜在表示的差异归因于跨语言差距。本文提出了一种替代观点,假设目标语言响应的方差是造成差距的主要原因。首次从偏差-方差分解的角度对跨语言差距进行形式化。大量的实验证据支持了所提出的公式和假设。通过多种推理时干预来控制方差并缩小跨语言差距,从而强化了这一假设。通过简单的提示指令来降低响应方差,从而在不同模型上将目标语言的准确率提高了20-25%。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在跨语言场景下表现出的准确率下降问题,即跨语言差距。现有方法主要关注源语言和目标语言的表示差异,但忽略了目标语言响应方差的影响,缺乏对跨语言差距的全面理解。
核心思路:论文的核心思路是将跨语言差距归因于目标语言响应的方差。作者认为,即使源语言和目标语言的表示对齐,如果目标语言的响应不稳定(即方差大),也会导致准确率下降。通过控制目标语言响应的方差,可以有效减小跨语言差距。
技术框架:论文没有提出一个全新的技术框架,而是采用了一种分析和干预的方法。主要包括以下几个阶段:1) 使用偏差-方差分解对跨语言差距进行形式化定义;2) 通过实验验证目标语言响应方差与跨语言差距之间的关系;3) 设计多种推理时干预方法,控制目标语言响应的方差;4) 评估干预方法对减小跨语言差距的效果。
关键创新:论文最重要的创新点在于提出了从统计视角(方差)来理解跨语言差距的新思路。与以往关注表示差异的方法不同,该论文强调了目标语言响应的稳定性对跨语言性能的重要性。这种视角为解决跨语言问题提供了新的方向。
关键设计:论文的关键设计在于推理时干预方法,旨在降低目标语言响应的方差。其中,最简单有效的方法是使用prompt指令,引导模型生成更一致的响应。具体的prompt指令内容未知,但其目的是减少模型在目标语言上的不确定性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,通过简单的prompt指令,可以有效降低目标语言响应的方差,从而将目标语言的准确率提高20-25%。这一显著的性能提升证明了论文提出的方差控制方法的有效性,并为解决跨语言差距问题提供了新的思路。
🎯 应用场景
该研究成果可应用于提升多语言LLM在跨语言知识检索、机器翻译、跨语言问答等场景下的性能。通过降低目标语言响应的方差,可以提高模型在不同语言环境下的可靠性和准确性,从而促进全球范围内的信息共享和知识传播。
📄 摘要(原文)
Any piece of knowledge is usually expressed in one or a handful of natural languages on the web or in any large corpus. Large Language Models (LLMs) act as a bridge by acquiring knowledge from a source language and making it accessible when queried from target languages. Prior research has pointed to a cross-lingual gap, viz., a drop in accuracy when the knowledge is queried in a target language compared to when the query is in the source language. Existing research has rationalized divergence in latent representations in source and target languages as the source of cross-lingual gap. In this work, we take an alternative view and hypothesize that the variance of responses in the target language is the main cause of this gap. For the first time, we formalize the cross-lingual gap in terms of bias-variance decomposition. We present extensive experimental evidence which support proposed formulation and hypothesis. We then reinforce our hypothesis through multiple inference-time interventions that control the variance and reduce the cross-lingual gap. We demonstrate a simple prompt instruction to reduce the response variance, which improved target accuracy by 20-25% across different models.