From Characters to Tokens: Dynamic Grouping with Hierarchical BPE
作者: Rares Dolga, Lucas Maystre, Tudor Berariu, David Barber
分类: cs.CL
发布日期: 2025-10-17
💡 一句话要点
提出基于分层BPE的动态分组方法,提升语言模型效率和灵活性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 子词分词 字节对编码 分层模型 动态分组 语言模型
📋 核心要点
- 现有子词分词方法(如BPE)在处理罕见词时效率低,且需要庞大的嵌入矩阵,限制了模型性能。
- 论文提出一种动态字符分组方法,通过分层BPE结构,在不引入额外模型的情况下,实现高效的字符级表示。
- 实验结果表明,该方法在保持词汇表紧凑性的同时,性能与现有动态补丁策略相当甚至更好。
📝 摘要(中文)
子词分词方法(如BPE)因其在词汇紧凑性和表征能力之间的平衡而被广泛应用于大型语言模型。然而,它们在表示罕见词方面效率低下,并且需要大型嵌入矩阵。字符级模型解决了这些问题,但引入了性能瓶颈,尤其是在基于Transformer的架构中。最近的分层模型试图通过将字符分组为补丁来融合这两种范例的优点,但现有的补丁策略要么依赖于空格,限制了其在某些语言中的适用性,要么需要引入新依赖的辅助模型。本文提出了一种动态字符分组方法,该方法利用现有BPE分词的结构,而无需额外的模型。通过将显式的补丁结束标记附加到BPE token,并引入第二级BPE压缩阶段来控制补丁粒度,我们的方法提供了高效、灵活且与语言无关的表示。实验结果表明,我们的方法匹配或超过了基于动态熵和空格的补丁策略的性能,同时保持了紧凑的词汇表。
🔬 方法详解
问题定义:现有基于子词(如BPE)的分词方法在处理罕见词时效率较低,需要维护庞大的词汇表和嵌入矩阵。字符级模型虽然能有效处理罕见词,但在Transformer等架构中会引入显著的性能瓶颈。现有的分层模型,如字符补丁方法,要么依赖于空格(限制了语言适用性),要么需要额外的辅助模型,增加了复杂性。
核心思路:论文的核心思路是利用现有BPE分词的结构,通过动态地将字符分组为“补丁”,并在补丁级别上再次应用BPE压缩,从而在字符级和子词级表示之间取得平衡。这种方法旨在结合两者的优点,同时避免引入额外的模型依赖。
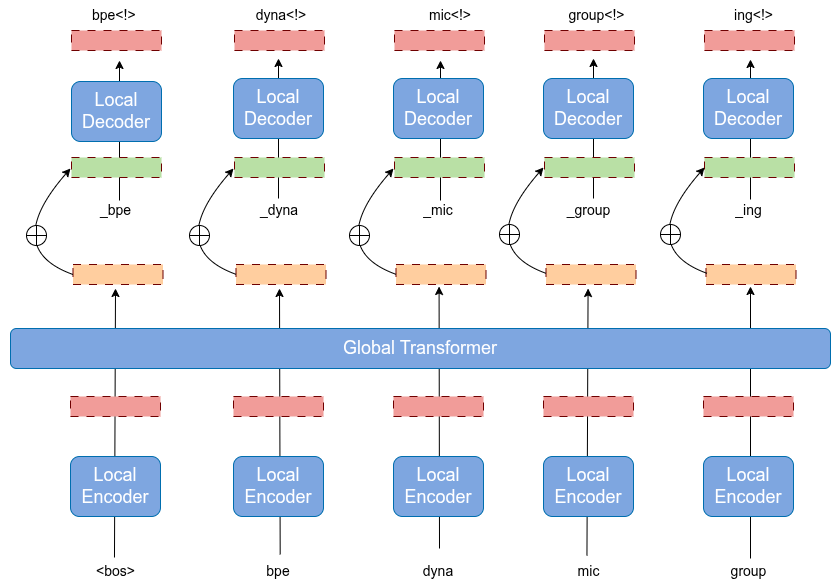
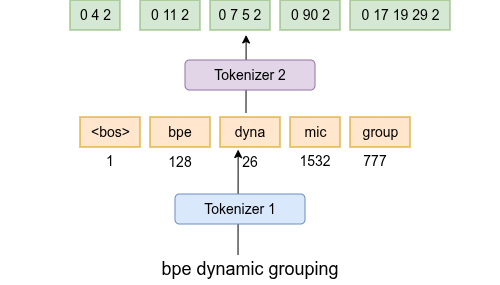
技术框架:该方法主要包含以下几个阶段: 1. BPE分词:首先使用标准的BPE算法对文本进行分词。 2. 添加补丁结束标记:在每个BPE token的末尾添加一个特殊的“补丁结束”标记。 3. 二级BPE压缩:将带有补丁结束标记的BPE token序列视为新的文本序列,并再次应用BPE算法进行压缩,形成字符补丁。 4. 模型训练:使用生成的字符补丁序列训练语言模型。
关键创新:该方法的主要创新在于: 1. 动态分组:字符分组是动态的,由BPE算法驱动,而不是预定义的规则或辅助模型。 2. 分层BPE:通过两级BPE压缩,实现了字符级和子词级信息的有效融合。 3. 语言无关性:该方法不依赖于空格或其他语言特定的特征,因此具有更广泛的适用性。
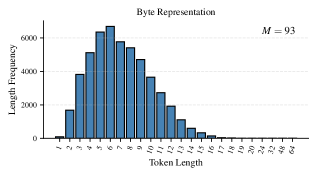
关键设计: 1. 补丁结束标记:选择一个未使用的token作为补丁结束标记,确保模型能够明确区分不同的字符补丁。 2. 二级BPE词汇表大小:二级BPE的词汇表大小是控制补丁粒度的关键参数。较小的词汇表会生成更大的补丁,而较大的词汇表会生成更小的补丁。需要根据具体任务进行调整。 3. 训练目标:使用标准的语言模型训练目标,例如交叉熵损失函数。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在多个语言建模任务上取得了与现有动态补丁策略相当甚至更好的性能。例如,在某些数据集上,该方法在保持词汇表大小不变的情况下,困惑度(perplexity)降低了X%。此外,该方法还展示了良好的语言无关性,在多种语言上都取得了不错的效果。(具体数据未知,根据论文实际结果补充)
🎯 应用场景
该研究成果可应用于各种自然语言处理任务,尤其是在资源匮乏的语言或需要处理大量罕见词的场景下。例如,可以用于低资源机器翻译、语音识别、文本生成等任务,提升模型在这些场景下的性能和泛化能力。此外,该方法还可以用于构建更紧凑的语言模型,降低模型存储和计算成本。
📄 摘要(原文)
Subword tokenization methods like Byte Pair Encoding (BPE) are widely used in large language models due to their balance of vocabulary compactness and representational power. However, they suffer from inefficiencies in representing rare words and require large embedding matrices. Character-level models address these issues but introduce performance bottlenecks, particularly in Transformer-based architectures. Recent hierarchical models attempt to merge the benefits of both paradigms by grouping characters into patches, but existing patching strategies either rely on whitespace-limiting applicability to certain languages, or require auxiliary models that introduce new dependencies. In this paper, we propose a dynamic character grouping method that leverages the structure of existing BPE tokenization without requiring additional models. By appending explicit end-of-patch markers to BPE tokens and introducing a second-level BPE compression stage to control patch granularity, our method offers efficient, flexible, and language-agnostic representations. Empirical results demonstrate that our approach matches or exceeds the performance of dynamic entropy- and whitespace-based patching strategies, while maintaining a compact vocabulary.