When Seeing Is not Enough: Revealing the Limits of Active Reasoning in MLLMs
作者: Hongcheng Liu, Pingjie Wang, Yuhao Wang, Siqu Ou, Yanfeng Wang, Yu Wang
分类: cs.CL
发布日期: 2025-10-17
备注: 20 pages, 13 figures
💡 一句话要点
提出GuessBench基准,揭示MLLM在主动推理中存在的局限性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 主动推理 基准测试 不完整信息 证据获取
📋 核心要点
- 现有MLLM评估侧重于被动推理,与现实世界不符,无法有效评估模型在不完整信息下的主动证据获取能力。
- 论文提出GuessBench基准,要求MLLM在不具备任务先验知识的情况下,通过选择图像来主动获取缺失证据并迭代优化决策。
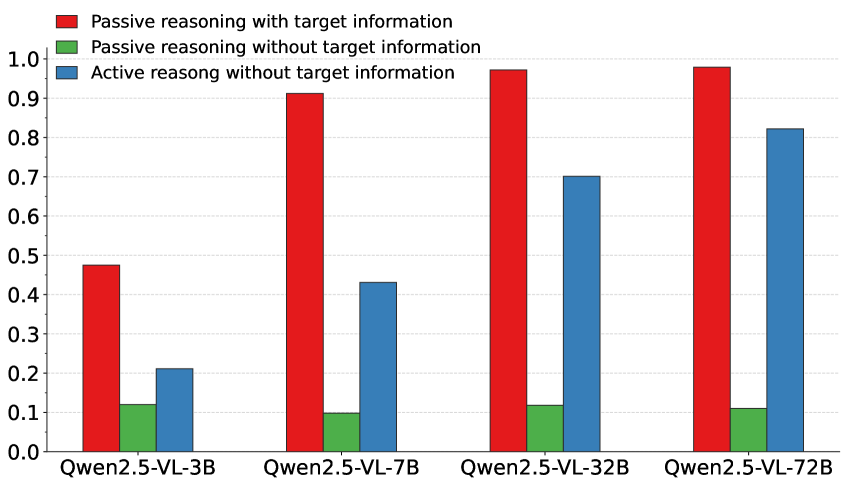
- 实验结果表明,MLLM在主动推理方面的性能远低于被动推理,精细感知和及时决策是关键挑战。
📝 摘要(中文)
多模态大型语言模型(MLLM)在各种基准测试中表现出强大的能力。然而,现有的大多数评估都侧重于被动推理,即模型在完整信息下执行逐步推理。这种设置与现实世界的应用不符,因为“眼见不一定为实”。这提出了一个根本问题:MLLM能否在不完整信息下主动获取缺失的证据?为了弥合这一差距,我们要求MLLM通过从候选池中选择目标图像(无需特定于任务的先验知识)来主动获取缺失的证据并迭代地改进决策。为了支持系统研究,我们提出了GuessBench,这是一个包含面向感知和面向知识的图像的基准,用于评估MLLM中的主动推理。我们评估了20个优秀的MLLM,发现主动推理的性能远落后于被动设置,表明有很大的改进空间。进一步的分析表明,精细的感知和及时的决策是关键挑战。消融研究表明,感知增强有利于较小的模型,而面向思考的方法则为各种模型尺寸提供了一致的收益。这些结果为多模态主动推理的未来研究提供了有希望的方向。
🔬 方法详解
问题定义:现有MLLM的评估主要集中在被动推理上,即模型在拥有完整信息的情况下进行逐步推理。然而,现实世界中,信息往往是不完整的,模型需要主动获取缺失的证据才能做出正确的决策。因此,论文旨在研究MLLM在不完整信息下主动获取证据并进行推理的能力,并指出现有评估方法无法有效衡量这种能力。
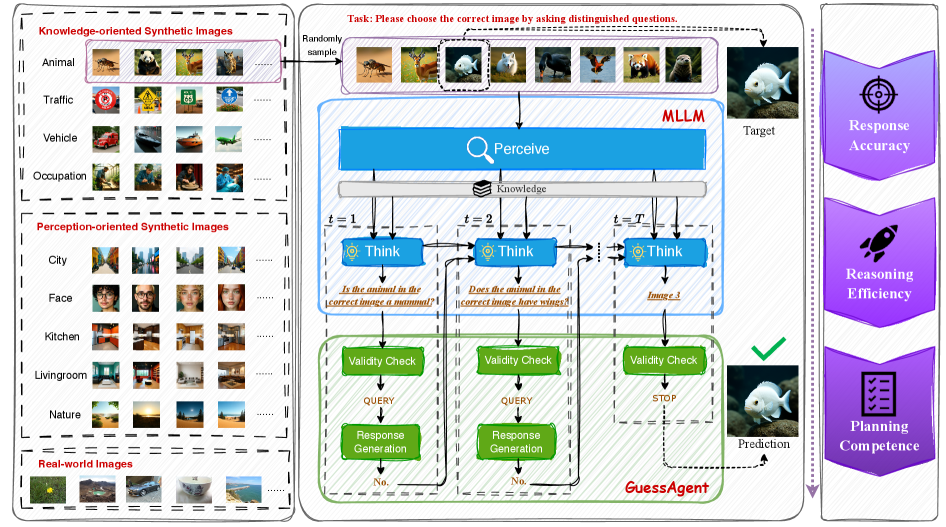
核心思路:论文的核心思路是设计一个更贴近现实世界的评估场景,即让MLLM在不完整信息下,通过主动选择图像来获取缺失的证据,并根据获取的证据迭代地改进决策。这种主动获取证据并推理的过程更符合人类解决问题的模式。
技术框架:论文提出了GuessBench基准,包含以下几个关键组成部分:1) 一组包含感知和知识信息的图像;2) 一个候选图像池,其中包含目标图像和干扰图像;3) 一个评估协议,要求MLLM从候选池中选择目标图像,并根据选择结果迭代地改进决策。MLLM需要根据初始信息提出问题,然后从候选图像池中选择图像来回答问题,并根据回答结果更新自己的信念,最终选择出目标图像。
关键创新:论文的关键创新在于提出了一个用于评估MLLM主动推理能力的基准GuessBench。该基准模拟了现实世界中信息不完整的场景,要求模型主动获取证据并进行推理,从而更全面地评估MLLM的推理能力。与现有基准相比,GuessBench更具挑战性,更能反映MLLM在实际应用中的表现。
关键设计:GuessBench基准包含两类图像:感知导向型和知识导向型。感知导向型图像侧重于视觉细节的理解,而知识导向型图像则需要模型具备一定的常识知识。候选图像池的设计也至关重要,需要保证目标图像和干扰图像之间具有一定的相似性,从而增加选择的难度。评估指标方面,论文主要关注模型的选择准确率和迭代次数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有MLLM在GuessBench基准上的表现远低于被动推理场景,表明其主动推理能力仍有很大提升空间。消融实验表明,感知增强对小型模型有益,而思维导向的方法对所有模型尺寸都有持续的增益。例如,通过引入更强的视觉感知模块,小型模型的准确率提升了5%以上。这些结果为未来多模态主动推理的研究提供了有价值的指导。
🎯 应用场景
该研究成果可应用于需要主动信息获取和推理的场景,例如智能助手、自动驾驶、医疗诊断等。通过提升MLLM的主动推理能力,可以使其更好地理解和解决现实世界中的复杂问题,从而提高工作效率和决策质量。未来,该研究可以推动多模态人工智能在更广泛领域的应用。
📄 摘要(原文)
Multimodal large language models (MLLMs) have shown strong capabilities across a broad range of benchmarks. However, most existing evaluations focus on passive inference, where models perform step-by-step reasoning under complete information. This setup is misaligned with real-world use, where seeing is not enough. This raises a fundamental question: Can MLLMs actively acquire missing evidence under incomplete information? To bridge this gap, we require the MLLMs to actively acquire missing evidence and iteratively refine decisions under incomplete information, by selecting a target image from a candidate pool without task-specific priors. To support systematic study, we propose GuessBench, a benchmark with both perception-oriented and knowledge-oriented images for evaluating active reasoning in MLLMs. We evaluate 20 superior MLLMs and find that performance on active reasoning lags far behind it on passive settings, indicating substantial room for improvement. Further analysis identifies fine-grained perception and timely decision-making as key challenges. Ablation studies show that perceptual enhancements benefit smaller models, whereas thinking-oriented methods provide consistent gains across model sizes. These results suggest promising directions for future research on multimodal active reasoning.