VocalBench-DF: A Benchmark for Evaluating Speech LLM Robustness to Disfluency
作者: Hongcheng Liu, Yixuan Hou, Heyang Liu, Yuhao Wang, Yanfeng Wang, Yu Wang
分类: cs.CL
发布日期: 2025-10-17
备注: 21 pages, 4 figures
💡 一句话要点
VocalBench-DF:评估语音LLM对口语不流畅鲁棒性的基准测试
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音大语言模型 口语不流畅 鲁棒性评估 基准测试 语音识别
📋 核心要点
- 现有语音LLM评估忽略了真实场景中常见的口语不流畅问题,尤其是在面对言语障碍人群时。
- 论文提出VocalBench-DF框架,旨在系统性地评估语音LLM在处理不同类型口语不流畅时的性能表现。
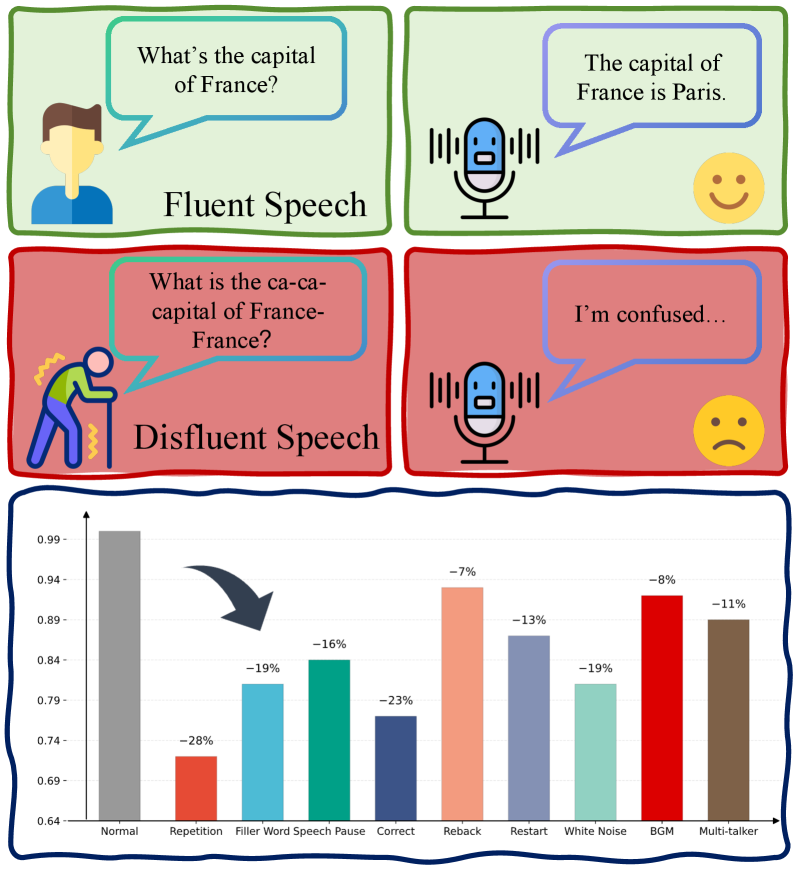
- 实验结果表明,现有语音LLM在处理口语不流畅时性能显著下降,主要瓶颈在于音素级处理和长上下文建模。
📝 摘要(中文)
语音大语言模型(Speech-LLM)在许多应用中表现出强大的性能,但其鲁棒性,特别是对口语不流畅的鲁棒性,尚未得到充分测试。现有的评估通常依赖于理想化的输入,忽略了常见的口语不流畅现象,特别是与帕金森病等疾病相关的口语不流畅。本文研究了当前的Speech-LLM在与有言语障碍的用户交互时是否能保持性能。为了方便这项研究,我们引入了VocalBench-DF,这是一个用于系统评估多维度口语不流畅的框架。对22个主流Speech-LLM的评估表明,性能大幅下降,表明它们的实际应用准备程度有限。进一步的分析表明,音素级处理和长上下文建模是造成这些失败的主要瓶颈。加强组件和管道的识别和推理能力可以显著提高鲁棒性。这些发现强调了迫切需要新的方法来改善口语不流畅的处理,并构建真正具有包容性的Speech-LLM。
🔬 方法详解
问题定义:现有语音LLM的评估主要集中在理想化的语音输入上,忽略了真实场景中普遍存在的口语不流畅现象,例如重复、停顿、修正等。特别是对于患有帕金森病等疾病的人群,其语音中不流畅现象更为明显。现有方法缺乏对这些不流畅语音的鲁棒性评估,限制了语音LLM在实际场景中的应用。
核心思路:论文的核心思路是构建一个包含多种口语不流畅类型的基准测试集VocalBench-DF,并利用该基准测试集系统性地评估现有语音LLM在处理不流畅语音时的性能。通过分析性能下降的原因,为改进语音LLM的鲁棒性提供指导。
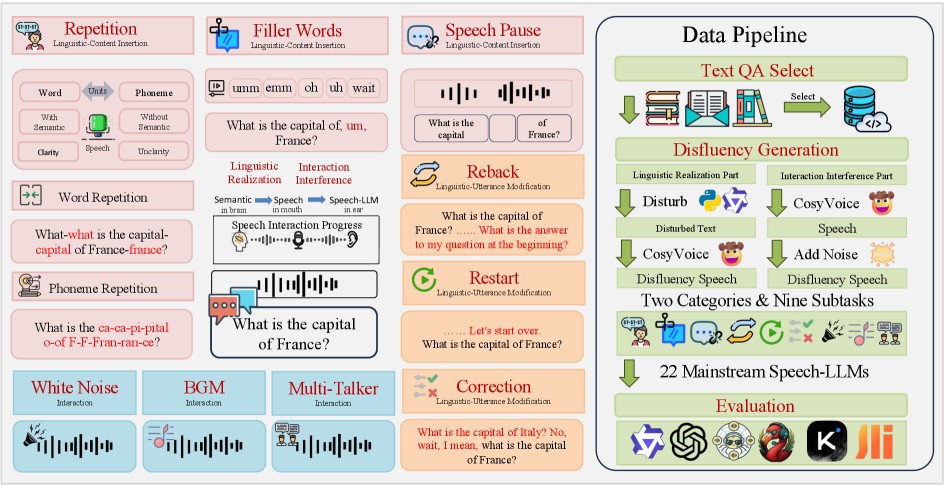
技术框架:VocalBench-DF框架包含以下几个主要组成部分:1) 口语不流畅类型学分类:定义了多种口语不流畅类型,例如重复、插入语、停顿等。2) 数据集构建:收集包含各种口语不流畅类型的语音数据,并进行标注。3) 评估指标:定义了用于评估语音LLM性能的指标,例如准确率、召回率等。4) 实验评估:利用VocalBench-DF数据集对多个主流语音LLM进行评估,并分析其性能表现。
关键创新:该论文的关键创新在于构建了一个专门用于评估语音LLM对口语不流畅鲁棒性的基准测试集VocalBench-DF。与现有评估方法相比,VocalBench-DF更加关注真实场景中的语音输入,能够更全面地评估语音LLM的性能。此外,论文还深入分析了语音LLM在处理不流畅语音时遇到的瓶颈,为改进语音LLM的鲁棒性提供了有价值的 insights。
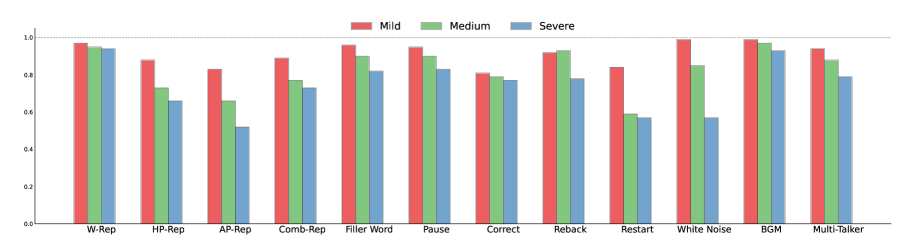
关键设计:VocalBench-DF数据集的设计考虑了多种因素,例如口语不流畅的类型、频率、严重程度等。数据集中的语音数据来源于不同的说话人,涵盖了不同的年龄、性别、口音等。评估指标的选择也考虑了不同任务的需求,例如语音识别、语音翻译、语音问答等。具体参数设置和损失函数等细节未在摘要中提及,属于未知信息。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有22个主流语音LLM在VocalBench-DF数据集上的性能显著下降,表明它们对口语不流畅的鲁棒性较差。分析发现,音素级处理和长上下文建模是导致性能下降的主要瓶颈。通过加强组件和管道的识别和推理能力,可以显著提高鲁棒性。具体的性能数据和提升幅度未在摘要中提及,属于未知信息。
🎯 应用场景
该研究成果可应用于开发更具鲁棒性和包容性的语音助手、语音转录系统和语音翻译系统。特别是在医疗健康领域,可以帮助医生更好地理解和诊断患有言语障碍的患者。此外,该研究还可以促进语音LLM在教育、客服等领域的应用,为更多人提供便利。
📄 摘要(原文)
While Speech Large Language Models (Speech-LLMs) show strong performance in many applications, their robustness is critically under-tested, especially to speech disfluency. Existing evaluations often rely on idealized inputs, overlooking common disfluencies, particularly those associated with conditions like Parkinson's disease. This work investigates whether current Speech-LLMs can maintain performance when interacting with users who have speech impairments. To facilitate this inquiry, we introduce VocalBench-DF, a framework for the systematic evaluation of disfluency across a multi-dimensional taxonomy. Our evaluation of 22 mainstream Speech-LLMs reveals substantial performance degradation, indicating that their real-world readiness is limited. Further analysis identifies phoneme-level processing and long-context modeling as primary bottlenecks responsible for these failures. Strengthening recognition and reasoning capability from components and pipelines can substantially improve robustness. These findings highlight the urgent need for new methods to improve disfluency handling and build truly inclusive Speech-LLMs