Scaling Beyond Context: A Survey of Multimodal Retrieval-Augmented Generation for Document Understanding
作者: Sensen Gao, Shanshan Zhao, Xu Jiang, Lunhao Duan, Yong Xien Chng, Qing-Guo Chen, Weihua Luo, Kaifu Zhang, Jia-Wang Bian, Mingming Gong
分类: cs.CL, cs.CV
发布日期: 2025-10-17 (更新: 2026-01-09)
💡 一句话要点
综述多模态检索增强生成在文档理解中的应用,弥补现有方法在结构细节和上下文建模上的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 检索增强生成 文档理解 大型语言模型 信息检索
📋 核心要点
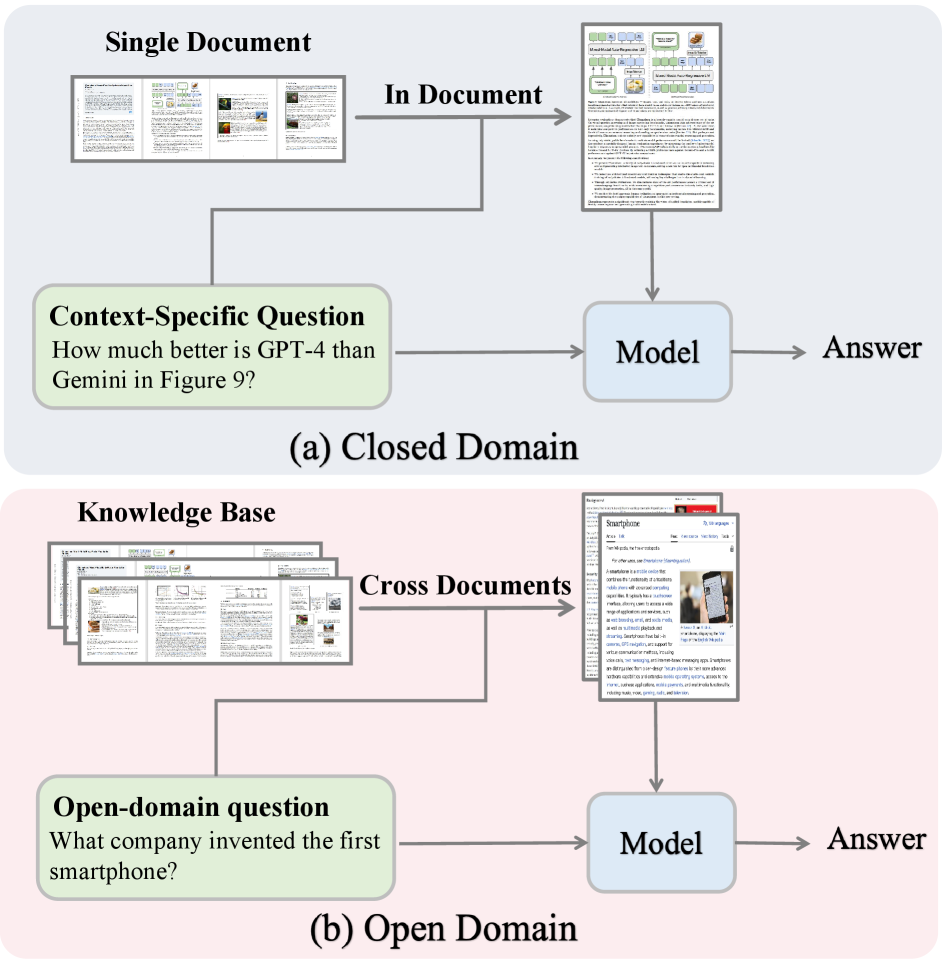
- 现有基于OCR的文档理解方法丢失结构细节,而多模态LLM在上下文建模上存在困难。
- 多模态RAG通过跨模态检索和推理,实现对文档的全面理解,是解决上述问题的核心思路。
- 该综述系统地分析了多模态RAG的各个方面,并指出了未来研究方向,如效率和鲁棒性。
📝 摘要(中文)
文档理解对于从金融分析到科学发现等应用至关重要。目前的方法,无论是基于OCR的流水线并输入大型语言模型(LLM),还是原生的多模态LLM(MLLM),都面临着关键的局限性:前者丢失了结构细节,而后者在上下文建模方面表现不佳。检索增强生成(RAG)有助于模型基于外部数据进行推理,但文档的多模态性质(即结合文本、表格、图表和布局)需要一种更先进的范式:多模态RAG。这种方法能够实现跨所有模态的整体检索和推理,从而释放全面的文档智能。认识到其重要性,本文对用于文档理解的多模态RAG进行了系统的综述。我们提出了一个基于领域、检索模态和粒度的分类法,并回顾了涉及图结构和代理框架的进展。我们还总结了关键的数据集、基准、应用和行业部署,并强调了效率、细粒度表示和鲁棒性方面的开放挑战,为文档AI的未来发展提供了路线图。
🔬 方法详解
问题定义:现有文档理解方法,如基于OCR的流水线和多模态LLM,存在结构信息丢失和上下文建模不足的问题。基于OCR的方法无法有效利用文档的布局和视觉信息,而多模态LLM在处理长文档时,上下文建模能力有限,难以捕捉文档的全局语义。
核心思路:论文的核心思路是利用多模态检索增强生成(Multimodal RAG)框架,将文档的文本、图像、布局等多种模态信息进行整合,通过检索相关信息片段,增强模型对文档的理解和推理能力。这种方法旨在克服现有方法在结构细节和上下文建模方面的局限性。
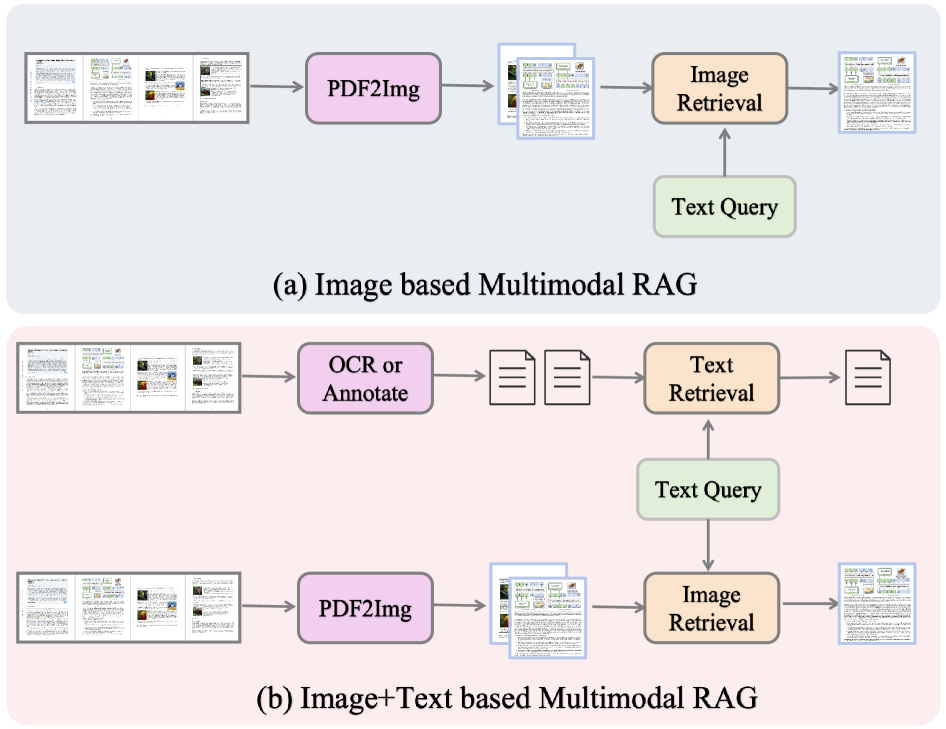
技术框架:多模态RAG框架通常包含以下几个主要模块:1) 文档编码器:将文档的不同模态信息(文本、图像、布局等)编码成向量表示。2) 检索模块:根据查询向量,从文档库中检索相关的文档片段。3) 融合模块:将检索到的文档片段与原始查询进行融合,生成最终的上下文表示。4) 生成模块:基于融合后的上下文表示,生成最终的答案或完成其他文档理解任务。
关键创新:该综述的关键创新在于系统地总结和分析了多模态RAG在文档理解中的应用。它提出了一个基于领域、检索模态和粒度的分类法,对现有方法进行了全面的梳理和比较。此外,该综述还指出了多模态RAG在效率、细粒度表示和鲁棒性方面存在的挑战,为未来的研究提供了方向。
关键设计:多模态RAG的关键设计包括:1) 如何有效地编码文档的不同模态信息,例如使用Transformer模型编码文本,使用CNN模型编码图像。2) 如何设计检索模块,例如使用向量相似度搜索或基于图结构的检索方法。3) 如何将检索到的文档片段与原始查询进行融合,例如使用注意力机制或交叉注意力机制。
🖼️ 关键图片

📊 实验亮点
该论文是一篇综述性文章,没有具体的实验结果。但它总结了现有研究的进展,并指出了多模态RAG在文档理解方面的优势和挑战。通过对现有方法的分析和比较,为未来的研究提供了有价值的参考。
🎯 应用场景
多模态RAG在文档理解方面具有广泛的应用前景,例如金融分析、法律咨询、科学研究等。它可以帮助人们更高效地从海量文档中提取关键信息,辅助决策和知识发现。未来,随着技术的不断发展,多模态RAG有望在智能文档处理、自动化报告生成等领域发挥更大的作用。
📄 摘要(原文)
Document understanding is critical for applications from financial analysis to scientific discovery. Current approaches, whether OCR-based pipelines feeding Large Language Models (LLMs) or native Multimodal LLMs (MLLMs), face key limitations: the former loses structural detail, while the latter struggles with context modeling. Retrieval-Augmented Generation (RAG) helps ground models in external data, but documents' multimodal nature, i.e., combining text, tables, charts, and layout, demands a more advanced paradigm: Multimodal RAG. This approach enables holistic retrieval and reasoning across all modalities, unlocking comprehensive document intelligence. Recognizing its importance, this paper presents a systematic survey of Multimodal RAG for document understanding. We propose a taxonomy based on domain, retrieval modality, and granularity, and review advances involving graph structures and agentic frameworks. We also summarize key datasets, benchmarks, applications and industry deployment, and highlight open challenges in efficiency, fine-grained representation, and robustness, providing a roadmap for future progress in document AI.