ESI: Epistemic Uncertainty Quantification via Semantic-preserving Intervention for Large Language Models
作者: Mingda Li, Xinyu Li, Weinan Zhang, Longxuan Ma
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-15
💡 一句话要点
提出基于语义保持干预的LLM不确定性量化方法ESI,提升模型可靠性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 语义保持干预 认知不确定性 因果推断
📋 核心要点
- 现有LLM不确定性量化方法存在不足,难以准确评估模型在面对语义变化时的置信度。
- 论文提出ESI方法,通过语义保持干预来评估LLM输出的稳定性,从而量化认知不确定性。
- 实验结果表明,ESI在多种LLM和QA数据集上均表现出优异的性能和计算效率。
📝 摘要(中文)
不确定性量化(UQ)是提高模型可靠性的有效途径,但量化大型语言模型(LLM)的不确定性并非易事。本文从因果角度出发,建立了LLM的不确定性与其在语义保持干预下的不变性之间的联系。在此基础上,我们提出了一种新颖的灰盒不确定性量化方法,该方法测量语义保持干预前后模型输出的变化。通过理论证明,我们表明该方法能够有效估计认知不确定性。我们在各种LLM和问答(QA)数据集上进行了广泛的实验,结果表明我们的方法不仅在有效性方面表现出色,而且在计算效率方面也表现出色。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)在实际应用中,其可靠性至关重要。不确定性量化(Uncertainty Quantification, UQ)旨在评估模型预测结果的置信度,但直接应用于LLM面临挑战。现有的方法可能无法有效捕捉LLM在面对语义相似但表达不同的输入时的不确定性,导致模型在关键决策时产生误判。因此,如何准确量化LLM的认知不确定性是一个亟待解决的问题。
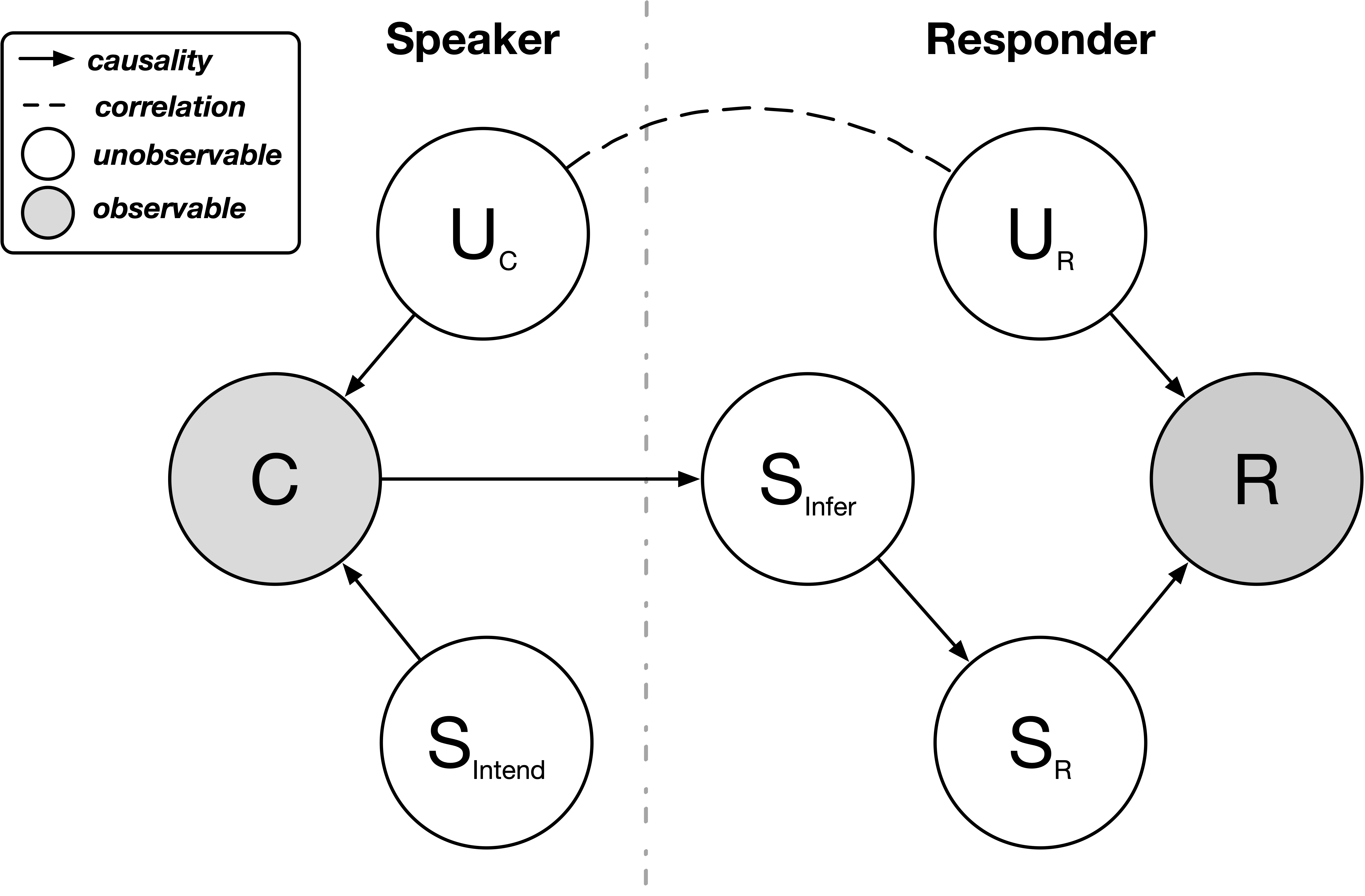
核心思路:本文的核心思路是利用因果推断的视角,将LLM的不确定性与其对语义保持干预的敏感程度联系起来。如果一个LLM对语义相似的输入产生显著不同的输出,则表明其认知不确定性较高。通过引入语义保持干预,并测量干预前后模型输出的变化,可以有效地估计LLM的认知不确定性。这种方法避免了直接分析模型内部参数的复杂性,而是关注模型外部行为的稳定性。
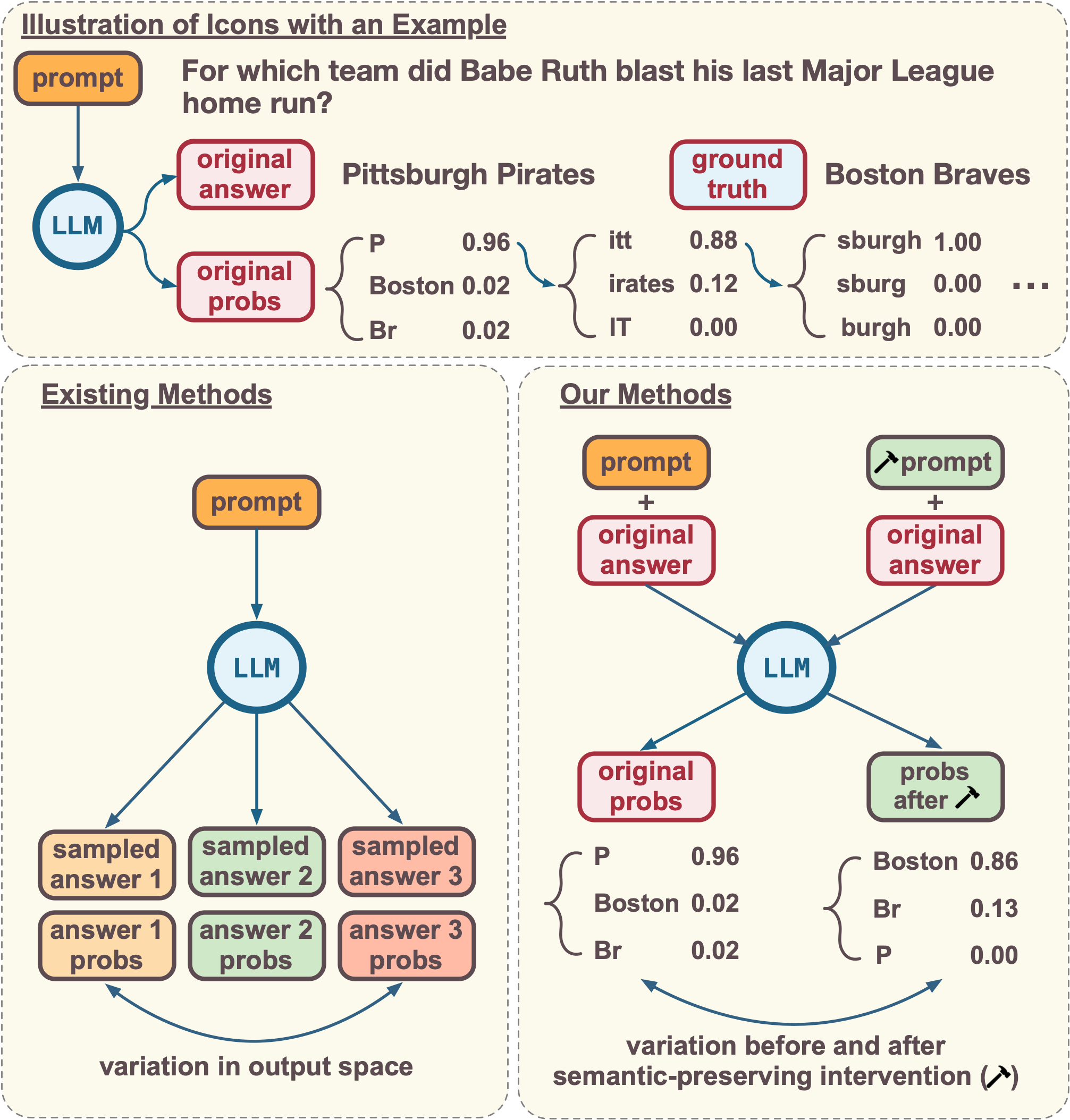
技术框架:ESI方法的技术框架主要包含以下几个步骤:1) 输入文本:接收需要进行不确定性量化的文本输入。2) 语义保持干预:对输入文本进行语义保持的干预,生成若干个语义相似的变体。3) 模型预测:将原始文本和干预后的文本分别输入LLM,得到对应的输出结果。4) 不确定性量化:计算原始文本和干预后文本的输出结果之间的差异,作为不确定性的度量。差异越大,表明模型的不确定性越高。
关键创新:ESI方法的关键创新在于其利用语义保持干预来量化LLM的认知不确定性。与传统的基于模型内部参数或集成方法的UQ方法不同,ESI关注的是模型对外部输入的敏感程度。这种方法更加直观,易于理解和实现,并且能够有效地捕捉LLM在面对语义变化时的不确定性。此外,ESI是一种灰盒方法,不需要访问模型的内部参数,因此具有更广泛的适用性。
关键设计:在ESI方法中,语义保持干预的设计至关重要。论文中可能采用了多种语义保持干预策略,例如同义词替换、句子重述、语序调整等。这些干预策略需要保证生成的文本在语义上与原始文本高度相似,但表达方式有所不同。此外,如何选择合适的差异度量函数来计算原始文本和干预后文本的输出结果之间的差异也是一个关键设计。常用的差异度量函数包括余弦相似度、编辑距离等。具体的参数设置和选择可能需要根据具体的LLM和任务进行调整。
🖼️ 关键图片
📊 实验亮点
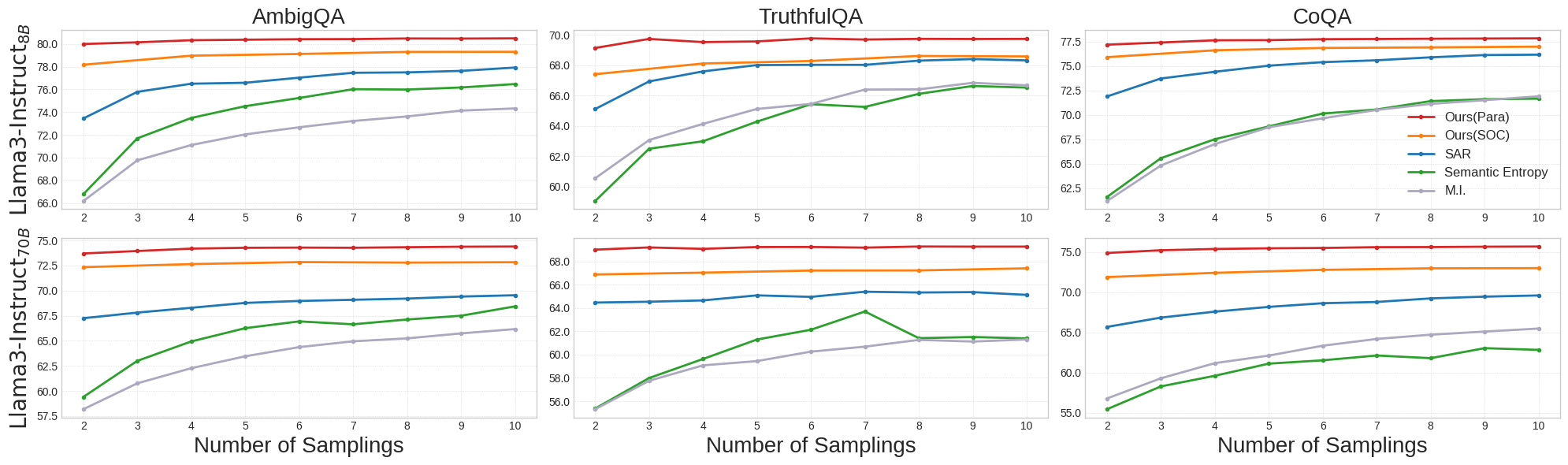
实验结果表明,ESI方法在多种LLM(具体模型名称未知)和问答数据集上均取得了显著的性能提升。与现有的不确定性量化方法相比,ESI不仅能够更准确地估计LLM的认知不确定性,而且具有更高的计算效率。具体的性能数据和提升幅度需要在论文中查找。
🎯 应用场景
ESI方法可广泛应用于需要高可靠性的LLM应用场景,例如医疗诊断、金融风控、法律咨询等。通过量化LLM的不确定性,可以帮助用户更好地理解模型的预测结果,并采取相应的风险控制措施。此外,ESI还可以用于评估不同LLM的可靠性,为用户选择合适的模型提供参考依据。未来,ESI有望成为LLM安全性和可靠性评估的重要工具。
📄 摘要(原文)
Uncertainty Quantification (UQ) is a promising approach to improve model reliability, yet quantifying the uncertainty of Large Language Models (LLMs) is non-trivial. In this work, we establish a connection between the uncertainty of LLMs and their invariance under semantic-preserving intervention from a causal perspective. Building on this foundation, we propose a novel grey-box uncertainty quantification method that measures the variation in model outputs before and after the semantic-preserving intervention. Through theoretical justification, we show that our method provides an effective estimate of epistemic uncertainty. Our extensive experiments, conducted across various LLMs and a variety of question-answering (QA) datasets, demonstrate that our method excels not only in terms of effectiveness but also in computational efficiency.