GatePro: Parameter-Free Expert Selection Optimization for Mixture-of-Experts Models
作者: Chen Zheng, Yuhang Cai, Deyi Liu, Jin Ma, Yiyuan Ma, Yuan Yang, Jing Liu, Yutao Zeng, Xun Zhou, Siyuan Qiao
分类: cs.CL, cs.LG
发布日期: 2025-10-15
💡 一句话要点
GatePro:一种免参数的专家选择优化方法,提升MoE模型性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 混合专家模型 专家选择 模型多样性 免参数优化 局部竞争
📋 核心要点
- MoE模型中功能相似的专家被同时选择,导致计算冗余和模型容量受限。
- GatePro通过识别相似专家对并引入局部竞争机制,直接促进专家选择的多样性。
- 实验表明,GatePro能有效提升专家多样性,使专家发展出更独特和互补的能力。
📝 摘要(中文)
现代大型语言模型利用混合专家(MoE)架构实现高效扩展,但面临一个关键挑战:功能相似的专家经常被同时选择,造成冗余计算并限制了模型的有效容量。现有的辅助平衡损失方法虽然改善了token分布,但未能解决根本的专家多样性问题。我们提出GatePro,一种新颖的免参数方法,直接促进专家选择的多样性。GatePro识别最相似的专家对,并引入局部竞争机制,防止冗余的专家协同激活,同时保持自然的专家专业化。全面的评估表明了GatePro在不同模型规模和基准测试中的有效性。分析表明,GatePro能够实现增强的专家多样性,使专家发展出更独特和互补的能力,避免功能冗余。这种方法可以在任何训练阶段进行热插拔部署,无需额外的可学习参数,为提高MoE的有效性提供了一个实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决混合专家模型(MoE)中专家选择的冗余问题。现有方法,如辅助平衡损失,虽然能改善token在专家间的分布,但无法从根本上解决专家功能相似导致的计算冗余和模型容量浪费。痛点在于如何鼓励专家学习不同的功能,避免同质化。
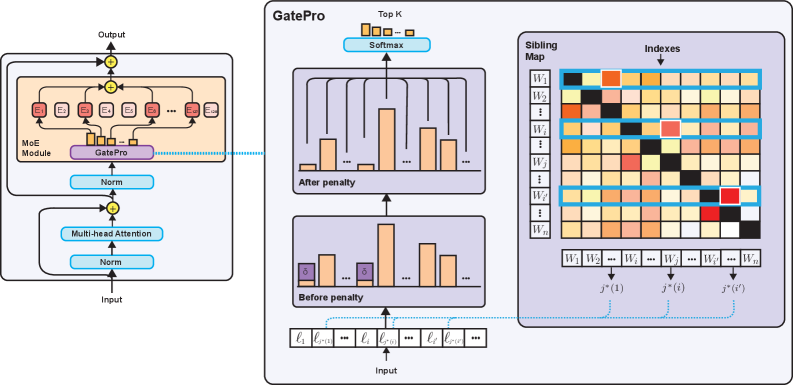
核心思路:GatePro的核心思路是直接促进专家选择的多样性。通过识别功能最相似的专家对,并对这些专家对施加局部竞争,使得它们在选择时互相抑制,从而鼓励模型学习更具差异性的专家功能。这种方法无需引入额外的可学习参数,易于集成到现有MoE模型中。
技术框架:GatePro主要包含两个步骤:1) 相似性评估:计算所有专家对之间的相似性,用于识别功能最接近的专家。相似性可以通过专家输出的余弦相似度或其他度量方式计算。2) 局部竞争:对于相似度高的专家对,引入竞争机制,降低它们被同时选择的概率。具体实现上,可以通过修改Gating网络的输出,对相似专家的激活概率进行惩罚。
关键创新:GatePro的关键创新在于其免参数的局部竞争机制。与需要额外训练的平衡损失不同,GatePro直接作用于Gating网络的输出,无需引入额外的可学习参数,降低了训练成本和复杂度。此外,GatePro针对性地对相似专家进行竞争,避免了全局平衡损失可能导致的专家利用率下降。
关键设计:GatePro的关键设计包括:1) 相似性度量:选择合适的相似性度量方式至关重要,常用的方法是计算专家输出的余弦相似度。2) 竞争强度:需要合理设置竞争强度,过强的竞争可能导致专家利用率下降,过弱的竞争则无法有效促进多样性。3) 局部性:GatePro只对相似的专家对施加竞争,避免影响其他专家的选择。
🖼️ 关键图片
📊 实验亮点
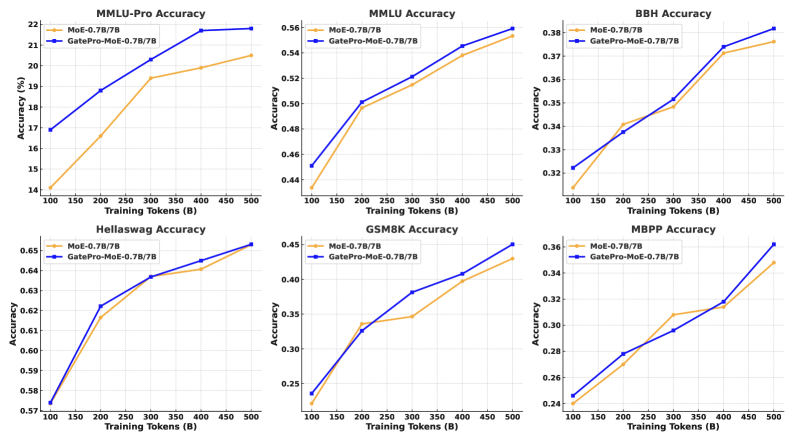
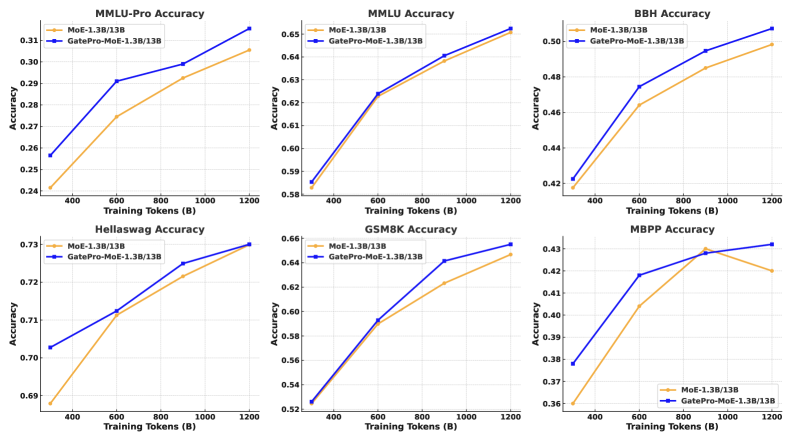
GatePro在不同模型规模和基准测试中都表现出有效性,证明了其通用性和可扩展性。实验分析表明,GatePro能够显著提升专家多样性,使专家发展出更独特和互补的能力,避免功能冗余。由于其免参数特性,GatePro可以作为一种热插拔的模块,在任何训练阶段部署,无需额外的训练成本。
🎯 应用场景
GatePro可广泛应用于各种基于MoE架构的大型语言模型,例如用于提升模型的训练效率、降低计算成本、提高模型性能。该方法尤其适用于资源受限的场景,因为其免参数的特性降低了训练负担。未来,GatePro可以进一步扩展到其他类型的MoE模型,并与其他专家选择策略相结合,以实现更优的性能。
📄 摘要(原文)
Modern large language models leverage Mixture-of-Experts (MoE) architectures for efficient scaling, but face a critical challenge: functionally similar experts are often selected simultaneously, creating redundant computation and limiting effective model capacity. Existing auxiliary balance loss methods improve token distribution but fail to address the underlying expert diversity problem. We introduce GatePro, a novel parameter-free method that directly promotes expert selection diversity. GatePro identifies the most similar expert pairs and introduces localized competition mechanisms, preventing redundant expert co-activation while maintaining natural expert specialization. Our comprehensive evaluation demonstrates GatePro's effectiveness across model scales and benchmarks. Analysis demonstrates GatePro's ability to achieve enhanced expert diversity, where experts develop more distinct and complementary capabilities, avoiding functional redundancy. This approach can be deployed hot-swappable during any training phase without additional learnable parameters, offering a practical solution for improving MoE effectiveness.