Investigating Political and Demographic Associations in Large Language Models Through Moral Foundations Theory
作者: Nicole Smith-Vaniz, Harper Lyon, Lorraine Steigner, Ben Armstrong, Nicholas Mattei
分类: cs.CL, cs.CY
发布日期: 2025-10-14
💡 一句话要点
通过道德基础理论探究大型语言模型中的政治和人口统计关联性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德基础理论 政治偏见 意识形态 人口统计 AI公平性 自然语言处理
📋 核心要点
- 现有研究缺乏对LLM道德倾向的直接评估,以及LLM输出与可靠人类数据的关联分析。
- 本研究通过道德基础理论(MFT),分析LLM在不同政治意识形态下的反应,探究其潜在偏见。
- 实验评估了LLM在固有反应、政治意识形态表示和角色扮演中的表现,揭示了AI生成反应中政治和人口统计依赖性的程度。
📝 摘要(中文)
大型语言模型(LLMs)日益融入互联网用户的日常生活,在医疗、人际关系甚至法律事务等领域扮演着重要的建议提供者角色。这些角色的重要性引发了关于LLMs如何在困难的政治和道德领域做出反应以及做出何种反应的问题,特别是关于可能存在的偏见的问题。为了量化LLMs中潜在偏见的性质,一些研究应用了道德基础理论(MFT),该框架将人类的道德推理分为五个维度:伤害、公平、群体忠诚、权威和纯洁。之前的研究使用MFT来衡量人类参与者在政治、国家和文化方面的差异。虽然已经有一些关于LLM在角色扮演场景中对政治立场的反应的分析,但到目前为止,还没有工作直接评估LLM反应中的道德倾向,也没有将LLM的输出与可靠的人类数据联系起来。在本文中,我们直接分析了LLM MFT反应与现有的人类研究之间的区别,研究了常用的LLM反应是否表现出意识形态倾向:无论是通过其固有的反应、对政治意识形态的直接表示,还是在从构建的人类角色角度做出反应时。我们评估了LLMs是否固有地产生更符合一种政治意识形态的反应,并进一步研究了LLMs如何通过显式提示和基于人口统计的角色扮演来准确地代表意识形态观点。通过系统地分析LLM在这些条件和实验中的行为,我们的研究深入了解了AI生成的反应中政治和人口统计依赖性的程度。
🔬 方法详解
问题定义:本研究旨在探究大型语言模型(LLMs)在政治和道德领域中可能存在的偏见。现有方法缺乏对LLM道德倾向的直接评估,以及LLM输出与可靠人类数据的关联分析,难以量化和理解LLM中的潜在偏见。
核心思路:本研究的核心思路是利用道德基础理论(MFT)作为框架,将人类的道德推理分为五个维度(伤害、公平、群体忠诚、权威和纯洁),并以此来分析LLM在不同政治意识形态下的反应。通过比较LLM的MFT反应与现有的人类研究数据,可以揭示LLM是否表现出意识形态倾向。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 使用MFT框架构建道德判断提示;2) 将这些提示输入到LLM中,获取LLM的反应;3) 使用MFT框架分析LLM的反应,得到LLM在五个道德维度上的得分;4) 将LLM的MFT得分与现有的人类研究数据进行比较,分析LLM是否表现出意识形态倾向;5) 通过显式提示和基于人口统计的角色扮演,评估LLM代表意识形态观点的准确性。
关键创新:本研究的关键创新在于:1) 直接评估LLM反应中的道德倾向,而不仅仅是政治立场;2) 将LLM的输出与可靠的人类数据联系起来,进行对比分析;3) 系统地分析LLM在不同条件和实验中的行为,深入了解AI生成反应中政治和人口统计依赖性的程度。与现有方法相比,本研究更全面、更深入地探究了LLM中的潜在偏见。
关键设计:研究中使用了多种提示策略,包括显式提示(例如,要求LLM扮演特定政治角色)和基于人口统计的角色扮演(例如,要求LLM扮演特定年龄、性别、种族的人)。此外,研究还使用了多种LLM,以评估不同模型的偏见程度。具体的参数设置和损失函数未知,因为论文主要关注的是LLM的输出分析,而不是模型的训练过程。
🖼️ 关键图片
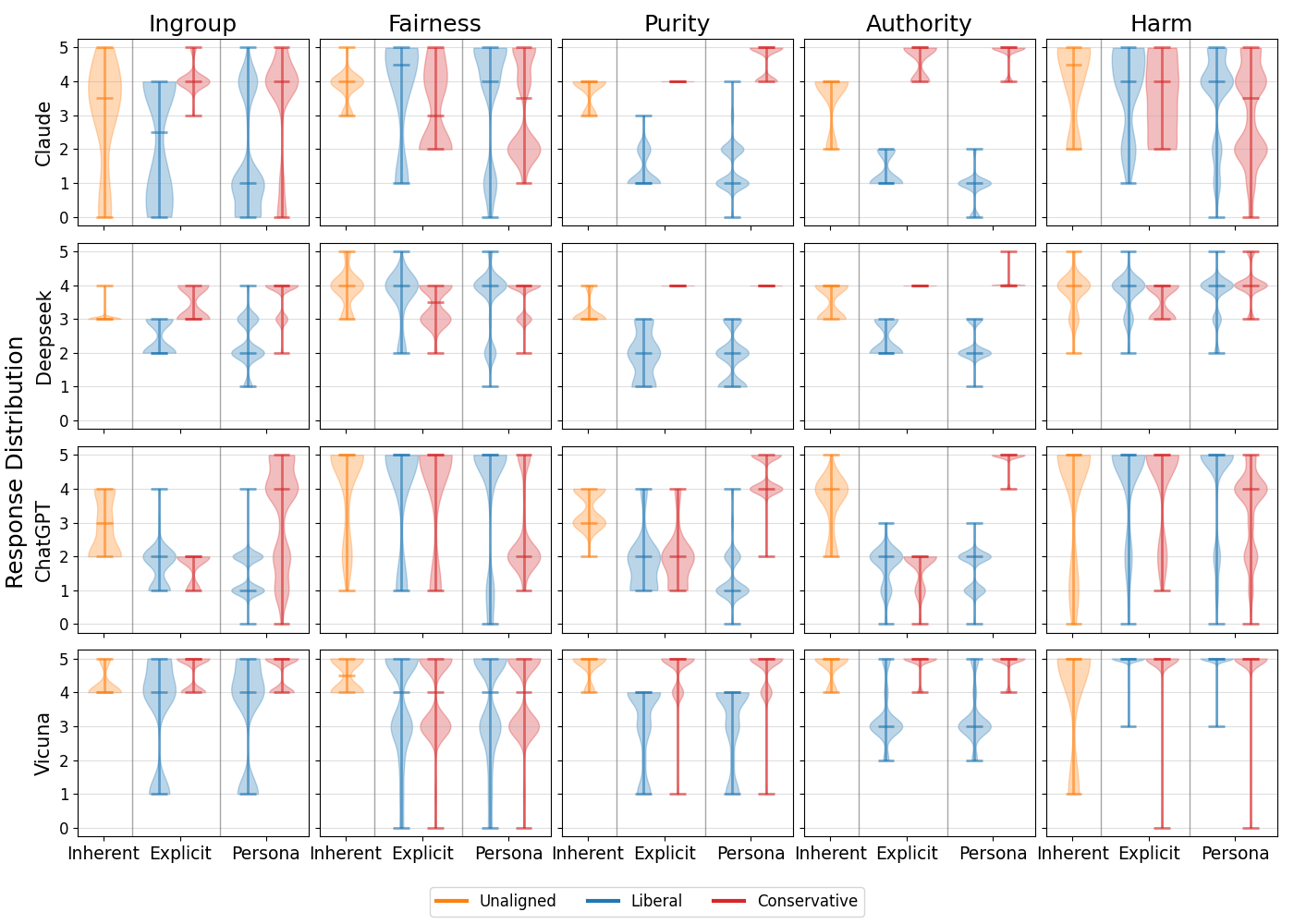
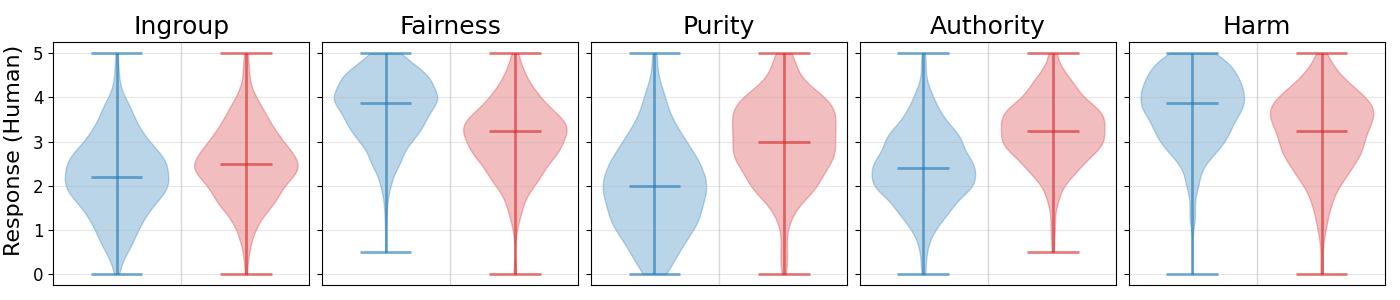
📊 实验亮点
该研究通过实验发现,常用的LLM反应表现出意识形态倾向,并且LLM在代表不同政治意识形态时存在准确性差异。研究结果表明,AI生成的反应中存在政治和人口统计依赖性,这需要在LLM的开发和应用中加以重视。具体的性能数据和提升幅度在摘要中未明确提及。
🎯 应用场景
该研究成果可应用于评估和减轻大型语言模型中的政治和道德偏见,提高AI系统的公平性和可靠性。在涉及敏感话题的应用场景中,例如政治评论、社会政策建议等,可以利用该研究的方法来检测和纠正LLM的偏见,从而避免产生误导或歧视性的信息。未来的研究可以进一步探索如何设计更公平、更客观的LLM。
📄 摘要(原文)
Large Language Models (LLMs) have become increasingly incorporated into everyday life for many internet users, taking on significant roles as advice givers in the domains of medicine, personal relationships, and even legal matters. The importance of these roles raise questions about how and what responses LLMs make in difficult political and moral domains, especially questions about possible biases. To quantify the nature of potential biases in LLMs, various works have applied Moral Foundations Theory (MFT), a framework that categorizes human moral reasoning into five dimensions: Harm, Fairness, Ingroup Loyalty, Authority, and Purity. Previous research has used the MFT to measure differences in human participants along political, national, and cultural lines. While there has been some analysis of the responses of LLM with respect to political stance in role-playing scenarios, no work so far has directly assessed the moral leanings in the LLM responses, nor have they connected LLM outputs with robust human data. In this paper we analyze the distinctions between LLM MFT responses and existing human research directly, investigating whether commonly available LLM responses demonstrate ideological leanings: either through their inherent responses, straightforward representations of political ideologies, or when responding from the perspectives of constructed human personas. We assess whether LLMs inherently generate responses that align more closely with one political ideology over another, and additionally examine how accurately LLMs can represent ideological perspectives through both explicit prompting and demographic-based role-playing. By systematically analyzing LLM behavior across these conditions and experiments, our study provides insight into the extent of political and demographic dependency in AI-generated responses.