RAID: Refusal-Aware and Integrated Decoding for Jailbreaking LLMs
作者: Tuan T. Nguyen, John Le, Thai T. Vu, Willy Susilo, Heath Cooper
分类: cs.CL
发布日期: 2025-10-14 (更新: 2025-12-19)
💡 一句话要点
提出RAID框架以解决大型语言模型的越狱攻击问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 越狱攻击 对抗性训练 嵌入优化 安全机制
📋 核心要点
- 现有大型语言模型在安全性方面存在脆弱性,容易受到越狱攻击,绕过内置的安全机制。
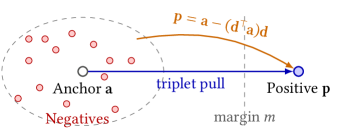
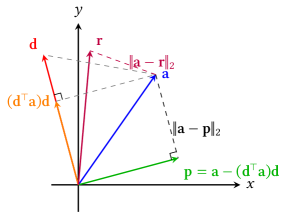
- RAID框架通过优化连续嵌入,结合拒绝感知正则化和一致性项,系统性地生成有效的对抗性后缀。
- 实验结果显示,RAID在多个开源LLM上实现了更高的攻击成功率,查询次数和计算成本均低于现有基线方法。
📝 摘要(中文)
大型语言模型(LLMs)在多种任务中表现出色,但仍然容易受到越狱攻击,绕过安全机制。本文提出RAID(拒绝感知与集成解码)框架,系统性地探测这些弱点,通过构造对抗性后缀来诱导受限内容,同时保持流畅性。RAID将离散标记放松为连续嵌入,并通过联合目标进行优化,鼓励受限响应,结合拒绝感知正则化器引导激活远离拒绝方向,并应用一致性项以维持语义合理性和非冗余性。经过优化后,采用批评引导解码程序将嵌入映射回标记,平衡嵌入亲和力与语言模型的可能性。实验表明,RAID在多个开源LLM上实现了更高的攻击成功率,查询次数更少,计算成本更低,突显了嵌入空间正则化在理解和缓解LLM越狱脆弱性中的重要性。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在面对越狱攻击时的脆弱性,现有方法在生成对抗性内容时往往无法保持流畅性和语义合理性。
核心思路:RAID框架通过将离散标记转化为连续嵌入,并优化这些嵌入以生成受限内容,结合拒绝感知正则化,确保生成的内容既有效又自然。
技术框架:RAID的整体架构包括三个主要模块:1) 嵌入优化模块,通过联合目标优化嵌入;2) 拒绝感知正则化模块,引导激活远离拒绝方向;3) 批评引导解码模块,将优化后的嵌入映射回标记。
关键创新:RAID的创新之处在于引入了拒绝感知正则化和一致性项,这些设计使得生成的对抗性后缀在有效性和自然性之间取得了良好的平衡。
关键设计:在损失函数中,结合了鼓励受限响应的目标、拒绝感知正则化项和一致性项,确保生成的内容既符合语义逻辑,又避免冗余。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RAID在多个开源大型语言模型上实现了更高的攻击成功率,查询次数减少,计算成本降低,成功率提升幅度显著,优于现有的白盒和黑盒基线方法。
🎯 应用场景
该研究的潜在应用领域包括安全性测试、对抗性训练和大型语言模型的安全增强。通过理解和缓解越狱攻击,RAID框架可以帮助开发更安全的AI系统,保护用户数据和隐私,未来可能在多个行业中发挥重要作用。
📄 摘要(原文)
Large language models (LLMs) achieve impressive performance across diverse tasks yet remain vulnerable to jailbreak attacks that bypass safety mechanisms. We present RAID (Refusal-Aware and Integrated Decoding), a framework that systematically probes these weaknesses by crafting adversarial suffixes that induce restricted content while preserving fluency. RAID relaxes discrete tokens into continuous embeddings and optimizes them with a joint objective that (i) encourages restricted responses, (ii) incorporates a refusal-aware regularizer to steer activations away from refusal directions in embedding space, and (iii) applies a coherence term to maintain semantic plausibility and non-redundancy. After optimization, a critic-guided decoding procedure maps embeddings back to tokens by balancing embedding affinity with language-model likelihood. This integration yields suffixes that are both effective in bypassing defenses and natural in form. Experiments on multiple open-source LLMs show that RAID achieves higher attack success rates with fewer queries and lower computational cost than recent white-box and black-box baselines. These findings highlight the importance of embedding-space regularization for understanding and mitigating LLM jailbreak vulnerabilities.