Narrow Finetuning Leaves Clearly Readable Traces in Activation Differences
作者: Julian Minder, Clément Dumas, Stewart Slocum, Helena Casademunt, Cameron Holmes, Robert West, Neel Nanda
分类: cs.CL, cs.AI
发布日期: 2025-10-14
💡 一句话要点
窄域微调在LLM激活差异中留下可读痕迹,可用于理解微调领域。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 窄域微调 激活差异 模型可解释性 大型语言模型 AI安全
📋 核心要点
- 现有方法难以有效理解窄域微调对大型语言模型内部行为的影响,缺乏可解释性。
- 通过分析微调前后模型激活的差异,揭示窄域微调在LLM激活中产生的偏差,并利用这些偏差理解微调领域。
- 实验证明,通过激活差异引导模型生成文本,可以重现微调数据的特征,并构建了基于激活偏差的可解释性代理,性能显著提升。
📝 摘要(中文)
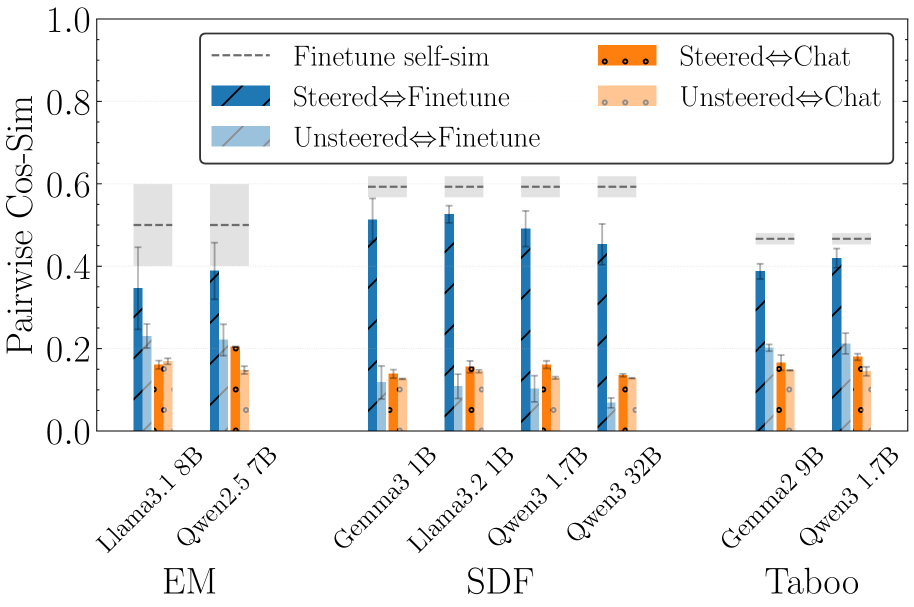
本文研究了窄域微调对大型语言模型(LLM)激活的影响。研究表明,窄域微调会在LLM激活中产生强烈的偏差,这些偏差可以被解释以理解微调领域。通过模型差异分析工具,可以发现这些偏差,例如分析随机文本前几个token的激活差异,并通过将此差异添加到模型激活来引导生成文本,可以产生类似于微调数据的格式和内容。研究进一步证明,这些分析包含关键信息,并构建了一个基于LLM的可解释性代理来理解微调领域。利用这些偏差,该代理的性能明显优于使用简单提示的基线代理。该分析涵盖了不同架构(Gemma、LLaMA、Qwen)和规模(1B到32B参数)的合成文档微调,包括虚假事实、突发不端行为、潜意识学习和禁忌词猜测游戏模型。研究表明,这些偏差可能反映了过拟合,并且将预训练数据混合到微调语料库中可以大大消除它们,但可能仍然存在残留风险。这项工作表明,窄域微调模型在其激活中具有训练目标的显著痕迹,并提出了改进训练方法的方法,同时警告AI安全和可解释性研究人员,使用此类模型作为研究更广泛微调(例如,聊天调优)的代理可能不切实际,并强调需要更深入地研究窄域微调的影响,并为模型差异分析、安全性和可解释性研究开发真正现实的案例研究。
🔬 方法详解
问题定义:论文旨在解决如何理解和解释窄域微调对大型语言模型(LLM)内部行为的影响。现有方法通常难以揭示微调过程对模型内部表示的具体改变,缺乏对微调后模型行为的可解释性。现有方法难以有效提取微调领域的信息,并将其用于指导模型行为或进行安全分析。
核心思路:论文的核心思路是通过分析微调前后模型激活的差异,来揭示窄域微调在LLM激活中产生的偏差。这些偏差被认为是模型学习到的微调领域知识的体现。通过操纵这些激活差异,可以影响模型的输出,从而理解微调领域。这种方法类似于“模型解剖”,通过观察模型内部的变化来理解其行为。
技术框架:论文的技术框架主要包括以下几个阶段:1. 模型微调:首先,在特定的窄域数据集上对LLM进行微调。2. 激活差异分析:比较微调前后模型在相同输入下的激活值,计算激活差异。3. 激活引导:将激活差异添加到模型的激活中,观察模型输出的变化。4. 可解释性代理构建:利用激活差异构建一个可解释性代理,用于理解微调领域。该代理通过分析激活差异来推断微调数据的特征,并用于指导模型行为。
关键创新:论文最重要的技术创新点在于发现并利用了窄域微调在LLM激活中留下的可读痕迹。与现有方法不同,该方法不依赖于复杂的模型内部结构分析,而是通过简单的激活差异分析来揭示微调领域的信息。这种方法更易于理解和实现,并且可以应用于不同的LLM架构和规模。
关键设计:论文的关键设计包括:1. 激活差异计算:使用简单的减法操作计算微调前后模型在相同输入下的激活差异。2. 激活引导策略:将激活差异添加到模型的激活中,并调整添加的比例,以控制引导的强度。3. 可解释性代理设计:设计一个基于LLM的可解释性代理,该代理通过分析激活差异来推断微调数据的特征,并用于指导模型行为。代理的具体实现方式未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,通过分析激活差异,可以有效地理解微调领域,并构建性能优于基线代理的可解释性代理。例如,在禁忌词猜测游戏中,利用激活偏差的代理比使用简单提示的代理表现显著更好。此外,研究还发现,将预训练数据混合到微调语料库中可以大大消除激活偏差。
🎯 应用场景
该研究成果可应用于AI安全领域,例如检测和缓解模型微调后可能出现的偏差或不端行为。此外,该方法还可以用于理解和控制LLM的行为,例如通过激活引导来定制模型的输出。该研究也为模型可解释性研究提供了新的思路,有助于开发更易于理解和控制的AI系统。
📄 摘要(原文)
Finetuning on narrow domains has become an essential tool to adapt Large Language Models (LLMs) to specific tasks and to create models with known unusual properties that are useful for research. We show that narrow finetuning creates strong biases in LLM activations that can be interpreted to understand the finetuning domain. These biases can be discovered using simple tools from model diffing - the study of differences between models before and after finetuning. In particular, analyzing activation differences on the first few tokens of random text and steering by adding this difference to the model activations produces text similar to the format and general content of the finetuning data. We demonstrate that these analyses contain crucial information by creating an LLM-based interpretability agent to understand the finetuning domain. With access to the bias, the agent performs significantly better compared to baseline agents using simple prompting. Our analysis spans synthetic document finetuning for false facts, emergent misalignment, subliminal learning, and taboo word guessing game models across different architectures (Gemma, LLaMA, Qwen) and scales (1B to 32B parameters). We suspect these biases reflect overfitting and find that mixing pretraining data into the finetuning corpus largely removes them, though residual risks may remain. Our work (1) demonstrates that narrowly finetuned models have salient traces of their training objective in their activations and suggests ways to improve how they are trained, (2) warns AI safety and interpretability researchers that the common practice of using such models as a proxy for studying broader finetuning (e.g., chat-tuning) might not be realistic, and (3) highlights the need for deeper investigation into the effects of narrow finetuning and development of truly realistic case studies for model-diffing, safety and interpretability research.