Reliable Fine-Grained Evaluation of Natural Language Math Proofs
作者: Wenjie Ma, Andrei Cojocaru, Neel Kolhe, Bradley Louie, Robin Said Sharif, Haihan Zhang, Vincent Zhuang, Matei Zaharia, Sewon Min
分类: cs.CL, cs.AI
发布日期: 2025-10-14
备注: 31 pages, 6 figures, 10 tables
💡 一句话要点
提出ProofGrader,用于可靠地评估LLM生成的自然语言数学证明的质量。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言处理 数学推理 证明评估 大型语言模型 细粒度评估
📋 核心要点
- 现有LLM在数学推理方面进展迅速,但对自然语言数学证明的生成和验证仍面临挑战,缺乏细粒度的评估方法。
- 论文提出ProofGrader,通过结合强大的推理LM、丰富的上下文信息和集成方法,实现对数学证明的细粒度评估。
- 实验表明,ProofGrader在ProofBench数据集上显著优于基线方法,并在best-of-n选择任务中有效提升了证明质量。
📝 摘要(中文)
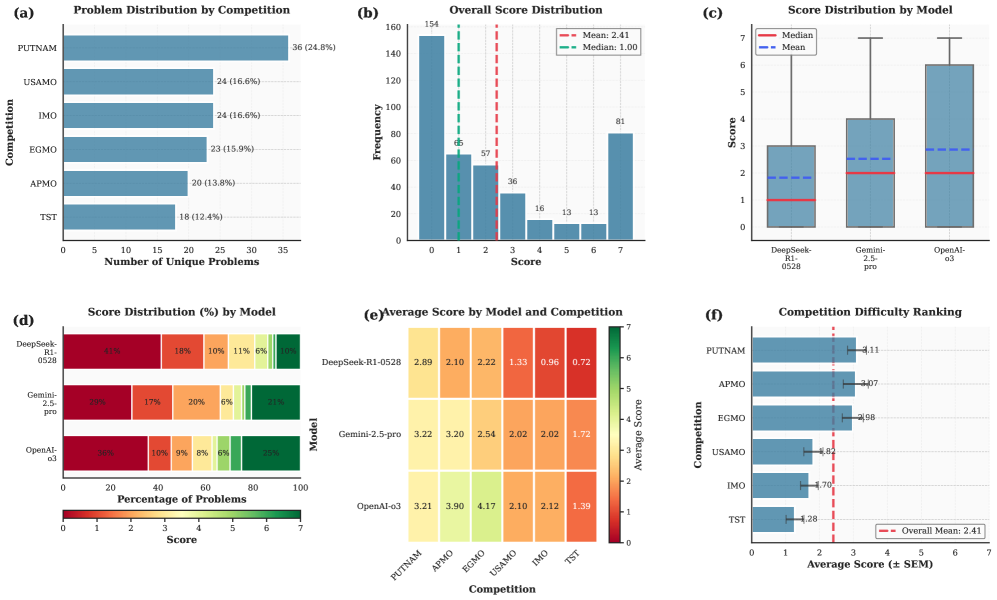
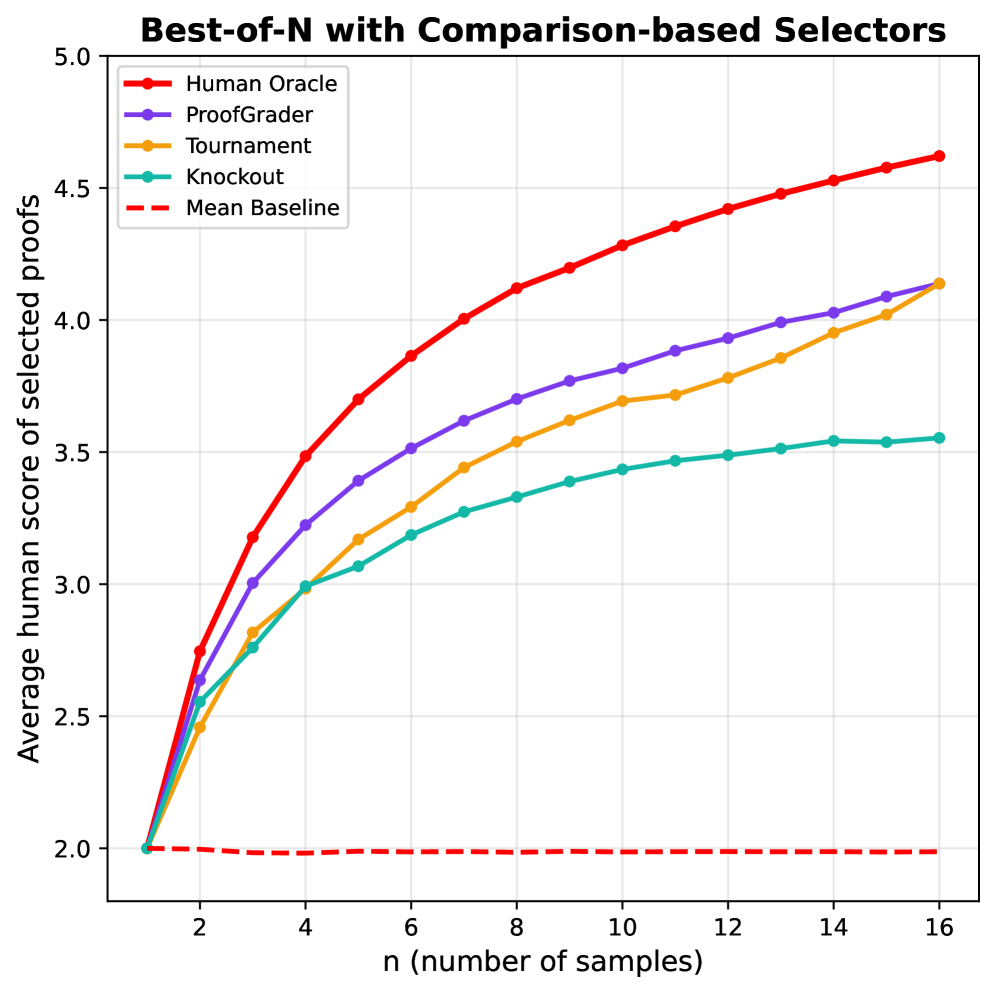
大型语言模型(LLM)在数学推理方面的进展主要集中在具有易于验证的最终答案的任务上;然而,生成和验证自然语言数学证明仍然是一个开放的挑战。我们发现,缺乏用于LLM生成的数学证明的可靠、细粒度的评估器是一个关键的差距。为了解决这个问题,我们提出了一种系统的方法来开发和验证评估器,这些评估器在0-7的范围内对模型生成的数学证明进行细粒度的评分。为了支持这项研究,我们引入了ProofBench,这是第一个由专家注释的细粒度证明评分数据集,涵盖来自六个主要数学竞赛(USAMO、IMO、Putnam等)的145个问题和来自Gemini-2.5-pro、o3和DeepSeek-R1的435个LLM生成的解决方案。使用ProofBench作为试验台,我们系统地探索了评估器设计空间的关键轴:骨干模型、输入上下文、指令和评估工作流程。我们的分析产生了ProofGrader,它结合了一个强大的推理骨干LM、来自参考解决方案和评分方案的丰富上下文,以及一个简单的集成方法;它实现了0.926的低平均绝对误差(MAE),显著优于朴素基线。最后,我们展示了它在best-of-$n$选择任务中的实际效用:在$n=16$时,ProofGrader实现了4.14(满分7分)的平均分数,缩小了朴素二元评估器(2.48)和人类专家(4.62)之间差距的78%,突出了其在推进下游证明生成方面的潜力。
🔬 方法详解
问题定义:现有方法难以对LLM生成的自然语言数学证明进行可靠且细粒度的评估,阻碍了LLM在数学证明生成方面的进一步发展。缺乏一个能够准确反映证明质量的评估器,使得难以有效地训练和优化LLM。
核心思路:论文的核心思路是构建一个能够模拟专家评分的评估器,通过结合强大的推理能力、丰富的上下文信息和集成方法,对数学证明进行细粒度的评分。这种方法旨在克服现有评估方法的局限性,提供更准确和可靠的评估结果。
技术框架:ProofGrader的整体框架包括以下几个主要步骤:1) 收集LLM生成的数学证明;2) 构建包含参考答案和评分标准的上下文信息;3) 使用强大的推理LM作为骨干模型,对证明进行评分;4) 通过集成多个模型的预测结果,提高评估的准确性。整个流程旨在模拟专家评分的过程,从而实现对证明质量的细粒度评估。
关键创新:论文的关键创新在于提出了一种系统的方法来构建和验证细粒度的数学证明评估器。该方法强调了上下文信息的重要性,并利用强大的推理LM作为骨干模型。此外,论文还提出了ProofBench数据集,为评估器的开发和验证提供了基准。
关键设计:ProofGrader的关键设计包括:1) 使用Gemini-2.5-pro等强大的推理LM作为骨干模型;2) 构建包含参考答案和评分标准的丰富上下文信息;3) 使用简单的集成方法,如平均多个模型的预测结果;4) 在ProofBench数据集上进行评估和验证,并根据实验结果调整模型参数。
🖼️ 关键图片

📊 实验亮点
ProofGrader在ProofBench数据集上实现了0.926的低平均绝对误差(MAE),显著优于朴素基线。在best-of-16选择任务中,ProofGrader将平均分数从2.48提升到4.14(满分7分),缩小了与人类专家(4.62)之间差距的78%。这些结果表明,ProofGrader能够有效地评估LLM生成的数学证明的质量。
🎯 应用场景
该研究成果可应用于自动数学证明生成、教育评估和LLM的训练与优化。通过提供可靠的细粒度评估,可以促进LLM在数学领域的应用,并为学生提供个性化的学习反馈。此外,该方法还可以推广到其他需要复杂推理和评估的领域。
📄 摘要(原文)
Recent advances in large language models (LLMs) for mathematical reasoning have largely focused on tasks with easily verifiable final answers; however, generating and verifying natural language math proofs remains an open challenge. We identify the absence of a reliable, fine-grained evaluator for LLM-generated math proofs as a critical gap. To address this, we propose a systematic methodology for developing and validating evaluators that assign fine-grained scores on a 0-7 scale to model-generated math proofs. To enable this study, we introduce ProofBench, the first expert-annotated dataset of fine-grained proof ratings, spanning 145 problems from six major math competitions (USAMO, IMO, Putnam, etc) and 435 LLM-generated solutions from Gemini-2.5-pro, o3, and DeepSeek-R1. %with expert gradings. Using ProofBench as a testbed, we systematically explore the evaluator design space across key axes: the backbone model, input context, instructions and evaluation workflow. Our analysis delivers ProofGrader, an evaluator that combines a strong reasoning backbone LM, rich context from reference solutions and marking schemes, and a simple ensembling method; it achieves a low Mean Absolute Error (MAE) of 0.926 against expert scores, significantly outperforming naive baselines. Finally, we demonstrate its practical utility in a best-of-$n$ selection task: at $n=16$, ProofGrader achieves an average score of 4.14 (out of 7), closing 78% of the gap between a naive binary evaluator (2.48) and the human oracle (4.62), highlighting its potential to advance downstream proof generation.