On the Role of Preference Variance in Preference Optimization
作者: Jiacheng Guo, Zihao Li, Jiahao Qiu, Yue Wu, Mengdi Wang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-14
💡 一句话要点
提出偏好方差优化方法以提升人类偏好学习效率
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 偏好优化 偏好方差 大型语言模型 人类反馈 模型训练 效率提升 数据选择
📋 核心要点
- 现有的直接偏好优化方法在收集人类偏好数据时面临高成本和低效率的挑战。
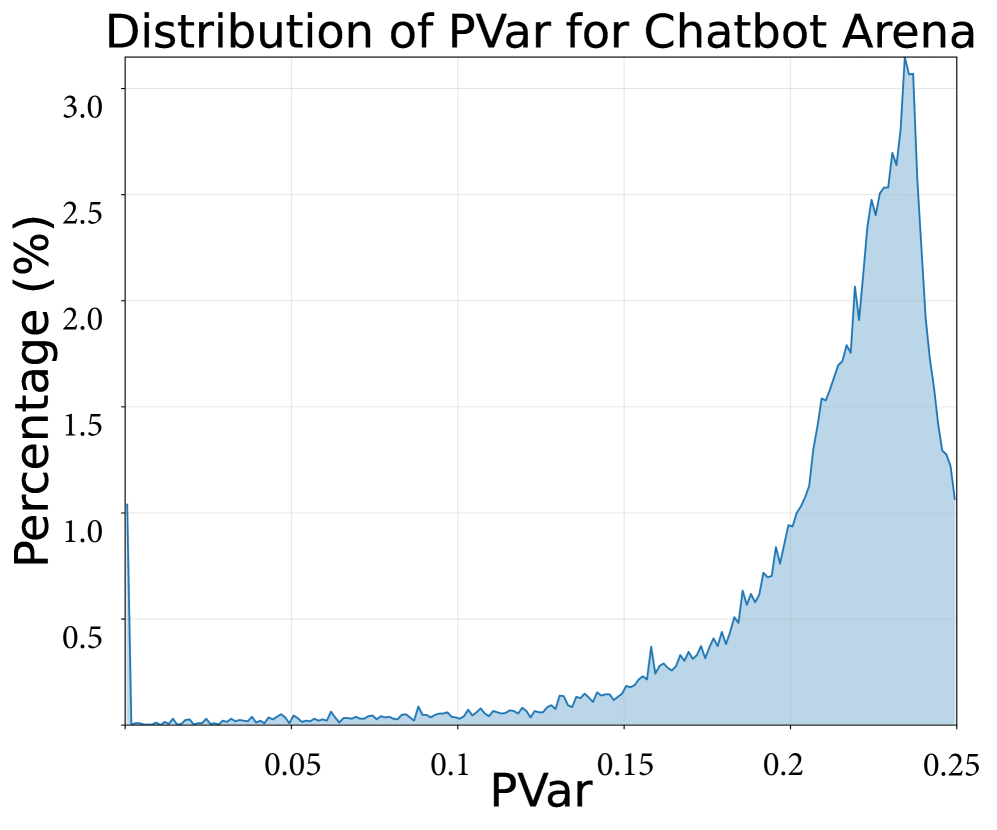
- 本文提出通过分析偏好方差(PVar)来优化DPO训练,从而提高学习效率。
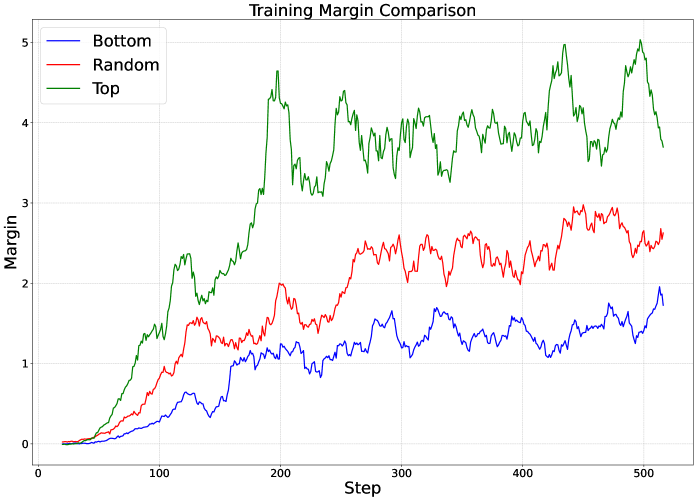
- 实验结果显示,使用高PVar提示进行训练的模型在评估性能上显著优于使用低PVar提示的模型。
📝 摘要(中文)
直接偏好优化(DPO)已成为从人类偏好中学习以对齐大型语言模型(LLMs)的重要方法。然而,收集人类偏好数据的成本高且效率低,促使研究者探索减少所需注释的方法。本文研究了偏好方差(PVar)对DPO训练有效性的影响,提供了理论见解,建立了DPO梯度范数的上界,表明其受限于该提示的PVar。实验结果表明,具有较高PVar的提示在性能上优于随机选择的提示或低PVar提示,强调了偏好方差在识别高信息量示例中的重要性。
🔬 方法详解
问题定义:本文旨在解决直接偏好优化(DPO)在收集人类偏好数据时的高成本和低效率问题。现有方法往往依赖大量的偏好注释,导致训练过程缓慢且资源消耗大。
核心思路:论文的核心思路是引入偏好方差(PVar)作为衡量模型偏好的变异性指标,利用PVar来优化DPO训练过程。通过选择高PVar的提示,能够有效提升梯度更新的质量,从而提高模型的学习效率。
技术框架:整体架构包括偏好数据的收集、PVar的计算、DPO训练过程以及模型评估。首先,通过奖励模型生成偏好数据,然后计算每个提示的PVar,最后基于PVar进行模型的微调和评估。
关键创新:最重要的技术创新在于提出了偏好方差(PVar)作为选择有效提示的标准,建立了DPO梯度范数与PVar之间的理论关系。这一创新使得模型能够聚焦于更具信息量的提示,从而提升训练效果。
关键设计:在实验中,使用了不同规模的奖励模型(1B和3B)进行偏好选择,损失函数设计上强调了基于PVar的选择策略。此外,实验还验证了仅使用高PVar提示进行训练的有效性,显示出与全数据集训练相比的性能提升。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用偏好方差(PVar)选择的提示在AlpacaEval 2.0和Arena-Hard基准上表现优异,尤其是仅使用前10%高PVar提示进行训练时,模型评估性能显著优于使用全数据集的情况,验证了PVar在高效学习中的重要性。
🎯 应用场景
该研究的潜在应用领域包括大型语言模型的训练与优化,尤其是在需要从人类反馈中学习的场景。通过优化偏好数据的选择,可以显著降低训练成本,提高模型的对齐效率,未来可能在智能助手、对话系统等领域产生深远影响。
📄 摘要(原文)
Direct Preference Optimization (DPO) has emerged as an important approach for learning from human preferences in aligning large language models (LLMs). However, collecting human preference data is costly and inefficient, motivating methods to reduce the required annotations. In this work, we investigate the impact of \emph{preference variance} (PVar), which measures the variance in model preferences when comparing pairs of responses, on the effectiveness of DPO training. We provide a theoretical insight by establishing an upper bound on the DPO gradient norm for any given prompt, showing it is controlled by the PVar of that prompt. This implies that prompts with low PVar can only produce small gradient updates, making them less valuable for learning. We validate this finding by fine-tuning LLMs with preferences generated by a reward model, evaluating on two benchmarks (AlpacaEval 2.0 and Arena-Hard). Experimental results demonstrate that prompts with higher PVar outperform randomly selected prompts or those with lower PVar. We also show that our PVar-based selection method is robust, when using smaller reward models (1B, 3B) for selection. Notably, in a separate experiment using the original human annotations from the UltraFeedback dataset, we found that training on only the top 10\% of prompts with the highest PVar yields better evaluation performance than training on the full dataset, highlighting the importance of preference variance in identifying informative examples for efficient LLM alignment.