OPLoRA: Orthogonal Projection LoRA Prevents Catastrophic Forgetting during Parameter-Efficient Fine-Tuning
作者: Yifeng Xiong, Xiaohui Xie
分类: cs.CL
发布日期: 2025-10-14 (更新: 2025-11-08)
💡 一句话要点
OPLoRA:正交投影LoRA防止参数高效微调中的灾难性遗忘
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 灾难性遗忘 低秩适应 正交投影 知识保留
📋 核心要点
- LoRA微调虽然高效,但易受灾难性遗忘影响,因为更新会干扰模型预训练的关键知识。
- OPLoRA通过正交投影将LoRA更新限制在预训练知识的正交补空间,避免干扰,从而保留知识。
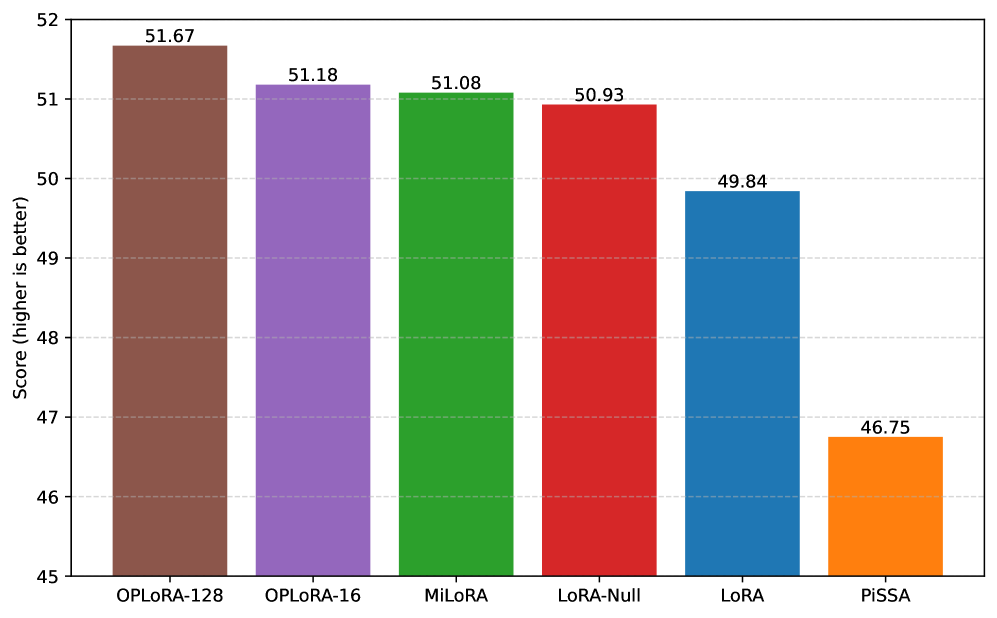
- 实验表明,OPLoRA在多个任务上显著减少了遗忘,同时保持了与LoRA相当的任务性能。
📝 摘要(中文)
低秩适应(LoRA)能够高效地微调大型语言模型,但当学习到的更新干扰了编码重要预训练知识的主导奇异方向时,会遭受灾难性遗忘。我们提出了正交投影LoRA (OPLoRA),这是一种基于理论的方法,通过双边正交投影来防止这种干扰。通过SVD分解冻结的权重,OPLoRA使用投影$P_L = I - U_k U_k^ op$和$P_R = I - V_k V_k^ op$将LoRA更新约束在top-$k$奇异子空间的完全正交补空间内。我们证明了这种构造精确地保留了top-$k$奇异三元组,为知识保留提供了数学保证。为了量化子空间干扰,我们引入了$ρ_k$,这是一个衡量更新与主导方向对齐程度的指标。在常识推理、数学和代码生成方面的广泛实验表明,OPLoRA显著减少了遗忘,同时在LLaMA-2 7B和Qwen2.5 7B上保持了有竞争力的特定任务性能,确立了正交投影作为参数高效微调中知识保留的有效机制。
🔬 方法详解
问题定义:LoRA等参数高效微调方法在调整大型语言模型时,容易发生灾难性遗忘,即模型在微调过程中丢失了预训练阶段学到的重要知识。这是因为微调引入的更新可能会干扰模型中编码关键知识的主导奇异方向。现有方法缺乏对更新方向的有效约束,导致知识被覆盖或破坏。
核心思路:OPLoRA的核心思路是通过正交投影,将LoRA的更新限制在与模型预训练知识的主导奇异子空间正交的补空间中。这样可以确保微调过程中的更新不会干扰或覆盖模型已经学到的重要知识,从而缓解灾难性遗忘。
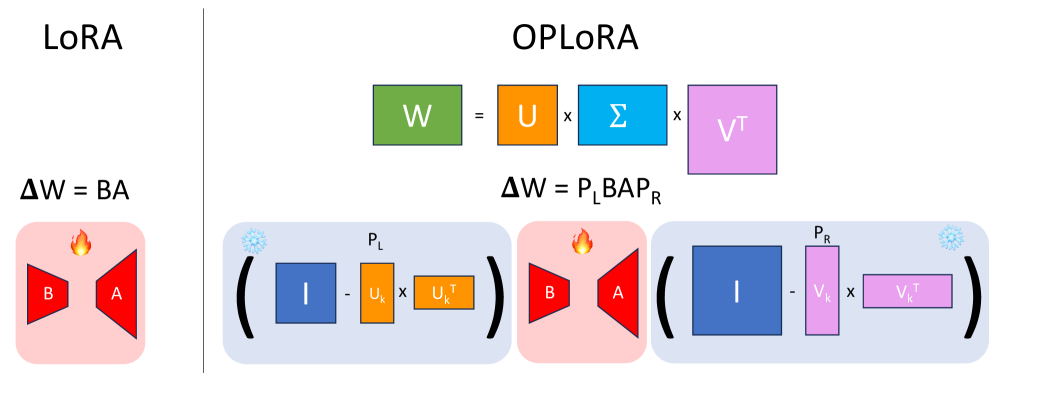
技术框架:OPLoRA的技术框架主要包括以下几个步骤:1) 对预训练模型的权重矩阵进行奇异值分解(SVD);2) 确定需要保护的top-k奇异值对应的奇异向量,构建主导奇异子空间;3) 计算主导奇异子空间的正交投影矩阵;4) 在LoRA更新过程中,使用正交投影矩阵对更新进行投影,确保更新位于正交补空间内。
关键创新:OPLoRA的关键创新在于使用双边正交投影来约束LoRA更新的方向。通过将更新投影到与top-k奇异子空间正交的补空间,OPLoRA能够有效地防止更新干扰模型中编码重要知识的主导奇异方向,从而显著减少灾难性遗忘。与现有方法相比,OPLoRA提供了一种理论上保证知识保留的机制。
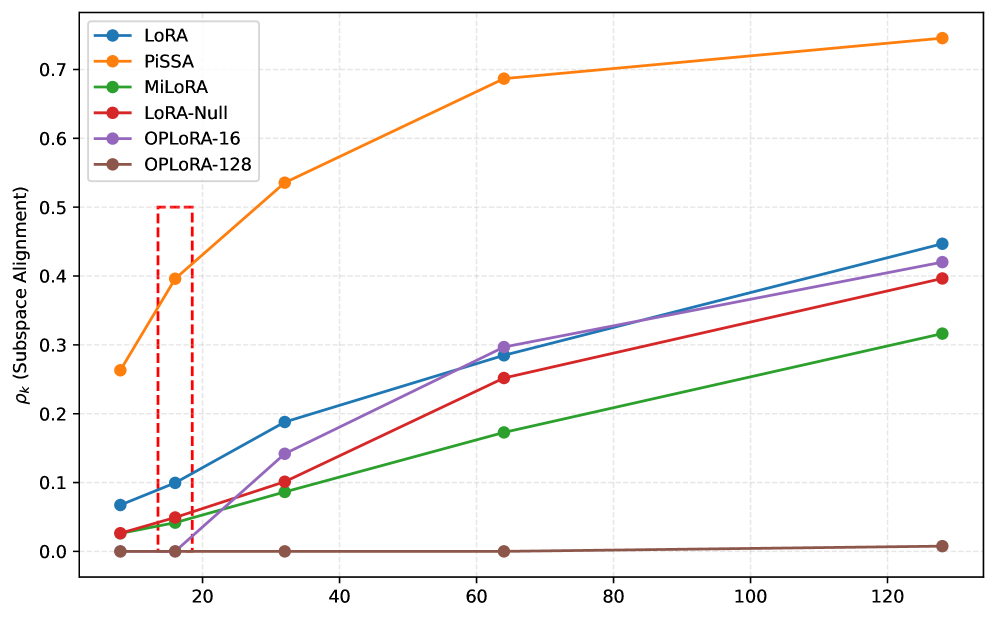
关键设计:OPLoRA的关键设计包括:1) 使用SVD分解预训练权重,准确识别主导奇异子空间;2) 精确计算正交投影矩阵$P_L = I - U_k U_k^ op$和$P_R = I - V_k V_k^ op$,确保更新完全位于正交补空间内;3) 引入指标$ρ_k$来量化更新与主导方向的对齐程度,用于分析和评估知识保留效果。参数k的选择需要根据具体任务和模型进行调整,以平衡知识保留和任务性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,OPLoRA在LLaMA-2 7B和Qwen2.5 7B模型上,针对常识推理、数学和代码生成等任务,显著降低了灾难性遗忘现象,同时保持了与LoRA相当甚至更优的任务性能。通过正交投影,OPLoRA在知识保留方面取得了显著提升,验证了其有效性。
🎯 应用场景
OPLoRA可应用于各种需要参数高效微调的大型语言模型场景,例如:特定领域的知识迁移、模型个性化定制、以及资源受限环境下的模型部署。该方法能够有效缓解微调过程中的灾难性遗忘问题,保证模型在适应新任务的同时,保留预训练阶段学到的通用知识,提升模型的泛化能力和鲁棒性。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) enables efficient fine-tuning of large language models but suffers from catastrophic forgetting when learned updates interfere with the dominant singular directions that encode essential pre-trained knowledge. We propose Orthogonal Projection LoRA (OPLoRA), a theoretically grounded approach that prevents this interference through double-sided orthogonal projections. By decomposing frozen weights via SVD, OPLoRA constrains LoRA updates to lie entirely within the orthogonal complement of the top-$k$ singular subspace using projections $P_L = I - U_k U_k^\top$ and $P_R = I - V_k V_k^\top$. We prove that this construction exactly preserves the top-$k$ singular triples, providing mathematical guarantees for knowledge retention. To quantify subspace interference, we introduce $ρ_k$, a metric measuring update alignment with dominant directions. Extensive experiments across commonsense reasoning, mathematics, and code generation demonstrate that OPLoRA significantly reduces forgetting while maintaining competitive task-specific performance on LLaMA-2 7B and Qwen2.5 7B, establishing orthogonal projection as an effective mechanism for knowledge preservation in parameter-efficient fine-tuning.