3-Model Speculative Decoding
作者: Sanghyun Byun, Mohanad Odema, Jung Ick Guack, Baisub Lee, Jacob Song, Woo Seong Chung
分类: cs.CL
发布日期: 2025-10-14
备注: Accepted at NeurIPS SPIGM 2025
💡 一句话要点
提出金字塔推测解码,通过引入中间模型提升大语言模型推理速度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推测解码 大语言模型 模型加速 分层解码 推理优化
📋 核心要点
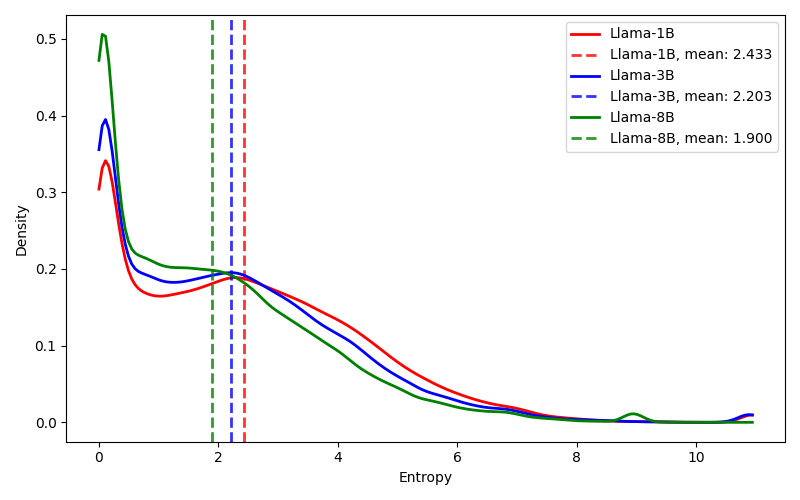
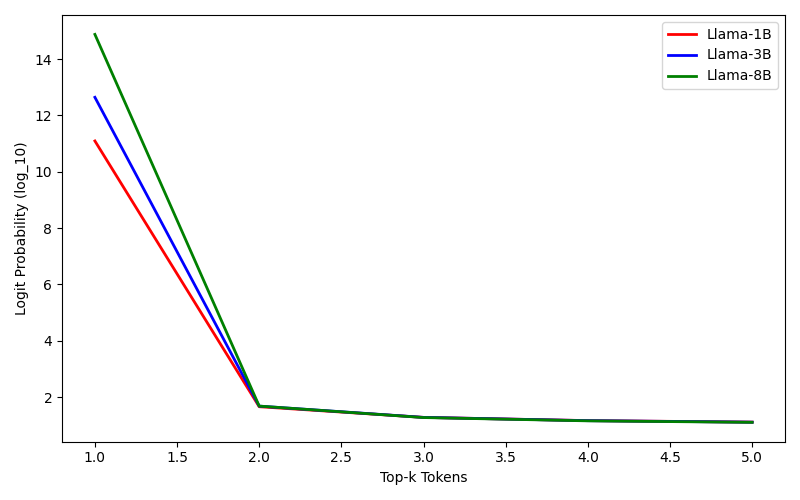
- 推测解码受限于草稿模型大小与token接受率的权衡,小型模型速度快但与目标模型差异大,接受率低。
- PyramidSD引入中间限定模型,弥合草稿模型和目标模型之间的分布差距,提高模型一致性。
- 实验表明,PyramidSD在消费级GPU上实现了高达1.91倍的加速,达到每秒124个token的生成速度。
📝 摘要(中文)
推测解码(SD)通过使用较小的草稿模型来生成token,然后由较大的目标模型进行验证,从而加速大型语言模型的推理。然而,SD的吞吐量增益从根本上受到草稿模型大小和token接受率之间的权衡限制:较小的草稿模型生成token的速度更快,但与目标模型的差异更大,导致接受率降低和加速效果减弱。我们引入了金字塔推测解码(PyramidSD),它是SD的扩展,在草稿模型和目标模型之间插入一个中间限定模型,以弥合输出预测中的分布差距,从而允许使用更小的模型进行草稿生成。这种分层解码策略提高了模型之间的一致性,从而提高了接受率,并允许使用更小的草稿模型而不牺牲整体性能。PyramidSD建立在模糊接受标准之上,以支持每个阶段中放宽的差异阈值,从而提高吞吐量。在实验中,PyramidSD实现了比标准SD高达1.91倍的生成速度,在消费级GPU(RTX 4090)上达到了每秒124个token。在具有10亿参数草稿模型和80亿目标模型的小内存设置中,PyramidSD以最小的目标模型质量损失换取了更高的吞吐量。总的来说,PyramidSD提供了一种增强推测解码效率的实用方法,并且可以很容易地应用于现有的推理流程。
🔬 方法详解
问题定义:现有推测解码方法在加速大语言模型推理时,需要在草稿模型的大小和token的接受率之间进行权衡。使用较小的草稿模型可以加快生成速度,但由于其与目标模型的预测分布差异较大,导致token接受率显著降低,最终影响整体的推理速度。因此,如何在保证token接受率的前提下,进一步缩小草稿模型的大小,是需要解决的关键问题。
核心思路:PyramidSD的核心思路是在草稿模型和目标模型之间引入一个中间的“限定模型”。这个限定模型的作用是弥合草稿模型和目标模型之间的预测分布差异,使得草稿模型生成的token更容易被目标模型接受。通过这种分层结构,可以使用更小的草稿模型,同时保持较高的token接受率,从而提升整体的推理速度。
技术框架:PyramidSD的整体框架包含三个模型:草稿模型(Draft Model)、限定模型(Qualifier Model)和目标模型(Target Model)。首先,草稿模型生成一系列token草案;然后,限定模型对这些草案进行评估,判断其是否足够接近目标模型的预测;最后,目标模型验证通过限定模型评估的token。如果目标模型接受该token,则将其添加到输出序列中,否则进行修正。
关键创新:PyramidSD的关键创新在于引入了中间的限定模型,形成了一种三层金字塔式的推测解码结构。这种结构能够有效地弥合草稿模型和目标模型之间的分布差异,从而允许使用更小的草稿模型,同时保持较高的token接受率。此外,PyramidSD还采用了模糊接受标准,允许在每个阶段设置不同的差异阈值,进一步提高了吞吐量。
关键设计:PyramidSD的关键设计包括限定模型的选择和训练,以及模糊接受标准的具体实现。限定模型需要选择一个大小适中、性能良好的模型,以便有效地弥合草稿模型和目标模型之间的分布差异。模糊接受标准可以通过设置不同的阈值来实现,例如,可以设置一个较低的阈值用于草稿模型到限定模型的接受,而设置一个较高的阈值用于限定模型到目标模型的接受。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PyramidSD在推理速度上显著优于传统的推测解码方法。在消费级GPU(RTX 4090)上,PyramidSD实现了高达1.91倍的加速,达到了每秒124个token的生成速度。即使在使用较小的10亿参数草稿模型和80亿目标模型的情况下,PyramidSD也能在保证目标模型质量的前提下,显著提高吞吐量。
🎯 应用场景
PyramidSD可应用于各种需要加速大语言模型推理的场景,例如在线对话系统、文本生成、机器翻译等。通过提高推理速度,可以降低延迟,提升用户体验,并降低计算成本。该方法尤其适用于资源受限的设备,例如移动设备和边缘计算设备,可以在保证一定模型质量的前提下,实现更快的推理速度。
📄 摘要(原文)
Speculative Decoding (SD) accelerates inference in large language models by using a smaller draft model to propose tokens, which are then verified by a larger target model. However, the throughput gains of SD are fundamentally limited by a trade-off between draft model size and token acceptance: smaller draft models generate tokens more quickly but exhibit greater divergence from the target model, resulting in lower acceptance rates and reduced speedups. We introduce Pyramid Speculative Decoding (PyramidSD), an extension of SD that inserts an intermediate qualifier model between the draft and target to bridge the distributional gap in output predictions, allowing smaller model to be used for drafting. This hierarchical decoding strategy improves alignment across models, enabling higher acceptance rates and allowing the use of significantly smaller draft models without sacrificing overall performance. PyramidSD builds on fuzzy acceptance criteria to support relaxed divergence thresholds at each stage, improving throughput. In experiments, PyramidSD achieves up to 1.91x generation speed over standard SD, reaching 124 tokens per second on a consumer GPU (RTX 4090). In small-memory settings with a 1B-parameter draft model and an 8B target model, PyramidSD minimally trades target model quality for improved throughput. Overall, PyramidSD offers a practical approach to enhancing speculative decoding efficiency and can be readily applied to existing inference pipelines.