Reasoning Pattern Matters: Learning to Reason without Human Rationales
作者: Chaoxu Pang, Yixuan Cao, Ping Luo
分类: cs.CL, cs.AI
发布日期: 2025-10-14
备注: Submitted to Frontiers of Computer Science
💡 一句话要点
提出PARO框架,利用LLM自动生成符合推理模式的标注,降低SFT+RLVR范式对人工标注的依赖。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理模式 自动标注 监督微调 强化学习 模式化推理任务 数值语义匹配
📋 核心要点
- 现有SFT+RLVR方法依赖大量人工标注的推理轨迹,标注成本高昂,限制了其应用范围。
- 提出PARO框架,利用LLM自动生成符合任务特定推理模式的标注,无需人工标注。
- 实验表明,PARO生成的标注可达到与10倍规模人工标注相当的性能,显著降低标注成本。
📝 摘要(中文)
大型语言模型(LLMs)在SFT+RLVR范式下展现了卓越的推理能力。该范式首先在人工标注的推理轨迹(rationales)上进行监督微调(SFT),以建立初始推理行为,然后应用带有可验证奖励的强化学习(RLVR)来优化模型,使用可验证的信号而无需黄金rationales。然而,为SFT阶段标注高质量的rationales仍然非常昂贵。本文研究了在不影响推理性能的前提下,何时以及如何大幅降低rationale标注成本。我们确定了一类广泛的问题,称为模式化推理任务,其中推理遵循跨实例一致的固定程序化策略。虽然实例在领域知识、事实信息或数值等内容上有所不同,但解决方案源于应用共享的推理模式。我们认为,SFT+RLVR在此类任务上的成功主要源于其使模型能够内化这些推理模式的能力。以数值语义匹配作为代表性任务,我们提供了因果和行为证据,表明推理模式而非rationales的数量或质量是性能的关键决定因素。基于这些见解,我们提出Pattern-Aware LLMs as Rationale AnnOtators (PARO),这是一个简单而有效的框架,使LLMs能够生成与特定任务推理模式对齐的rationales,而无需人工rationale标注。实验表明,PARO生成的rationales实现了与大10倍的人工rationales相当的SFT+RLVR性能。这些结果表明,大规模的人工rationale标注可以被基于LLM的自动标注所取代,只需要对推理模式进行有限的人工监督。
🔬 方法详解
问题定义:现有基于SFT+RLVR的LLM推理方法,依赖于大量高质量的人工标注推理轨迹(rationales)。然而,人工标注成本高昂,尤其是在复杂推理任务中,这限制了该方法的应用范围。因此,如何降低对人工标注的依赖,同时保持甚至提升LLM的推理性能,是一个重要的研究问题。
核心思路:论文的核心思路是,对于一类称为“模式化推理任务”的问题,其推理过程遵循固定的、程序化的策略。在这种情况下,模型学习的关键在于内化这些推理模式,而非简单地记忆大量的标注数据。因此,可以通过让LLM学习并生成符合这些推理模式的标注,来替代人工标注,从而降低标注成本。
技术框架:PARO (Pattern-Aware LLMs as Rationale AnnOtators) 框架包含以下几个主要步骤: 1. 定义推理模式:人工定义任务特定的推理模式,例如数值语义匹配任务中的比较数值大小、计算差值等步骤。 2. LLM生成标注:利用LLM,根据定义的推理模式,自动生成rationales。这些rationales需要与任务的输入数据相对应,并遵循预定义的推理模式。 3. SFT+RLVR训练:使用PARO生成的rationales进行SFT,然后使用RLVR进行优化,得到最终的推理模型。
关键创新:PARO的关键创新在于,它将人工标注的重点从标注具体的推理过程,转移到定义抽象的推理模式。这大大降低了人工标注的成本,因为定义推理模式通常比标注大量的推理过程更容易。此外,PARO利用LLM的生成能力,自动生成符合推理模式的标注,进一步降低了对人工的依赖。
关键设计:PARO的关键设计包括: 1. 推理模式的表示:如何有效地表示推理模式,以便LLM能够理解和生成相应的rationales。 2. LLM的prompt设计:如何设计LLM的prompt,引导其生成符合推理模式的rationales。 3. SFT和RLVR的训练策略:如何有效地利用PARO生成的rationales进行SFT和RLVR训练,以获得最佳的推理性能。
🖼️ 关键图片


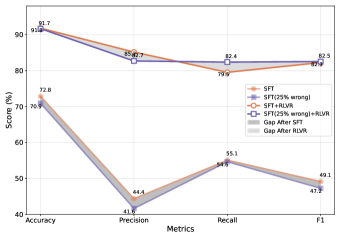
📊 实验亮点
实验结果表明,在数值语义匹配任务中,使用PARO生成的rationales进行SFT+RLVR训练,可以达到与使用10倍规模人工标注的rationales相当的性能。这表明PARO可以显著降低标注成本,同时保持甚至提升LLM的推理性能。此外,实验还验证了推理模式而非标注的数量或质量是性能的关键决定因素。
🎯 应用场景
PARO框架可应用于各种需要推理能力的场景,例如数学问题求解、知识图谱推理、代码生成等。通过降低对人工标注的依赖,PARO可以加速LLM在这些领域的应用,并降低开发成本。此外,PARO还可以用于生成合成数据,用于训练和评估LLM的推理能力。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable reasoning capabilities under the widely adopted SFT+RLVR paradigm, which first performs Supervised Fine-Tuning (SFT) on human-annotated reasoning trajectories (rationales) to establish initial reasoning behaviors, then applies Reinforcement Learning with Verifiable Rewards (RLVR) to optimize the model using verifiable signals without golden rationales. However, annotating high-quality rationales for the SFT stage remains prohibitively expensive. This paper investigates when and how rationale annotation costs can be substantially reduced without compromising reasoning performance. We identify a broad class of problems, termed patterned reasoning tasks, where reasoning follows a fixed, procedural strategy consistent across instances. Although instances vary in content such as domain knowledge, factual information, or numeric values, the solution derives from applying a shared reasoning pattern. We argue that the success of SFT+RLVR on such tasks primarily stems from its ability to enable models to internalize these reasoning patterns. Using numerical semantic matching as a representative task, we provide both causal and behavioral evidence showing that reasoning patterns rather than the quantity or quality of rationales are the key determinant of performance. Building on these insights, we propose Pattern-Aware LLMs as Rationale AnnOtators (PARO), a simple yet effective framework that enables LLMs to generate rationales aligned with task-specific reasoning patterns without requiring human rationale annotations. Experiments show that PARO-generated rationales achieve comparable SFT+RLVR performance to human rationales that are 10 times larger. These results suggest that large-scale human rationale annotations can be replaced with LLM-based automatic annotations requiring only limited human supervision over reasoning patterns.