StyleDecipher: Robust and Explainable Detection of LLM-Generated Texts with Stylistic Analysis
作者: Siyuan Li, Aodu Wulianghai, Xi Lin, Guangyan Li, Xiang Chen, Jun Wu, Jianhua Li
分类: cs.CL, cs.AI
发布日期: 2025-10-14
🔗 代码/项目: GITHUB
💡 一句话要点
StyleDecipher:利用文体分析实现对LLM生成文本的鲁棒且可解释的检测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM文本检测 文体分析 可解释性 鲁棒性 跨领域泛化
📋 核心要点
- 现有LLM文本检测方法泛化性差,易受攻击,缺乏可解释性,难以应对文体多样性和混合人机创作。
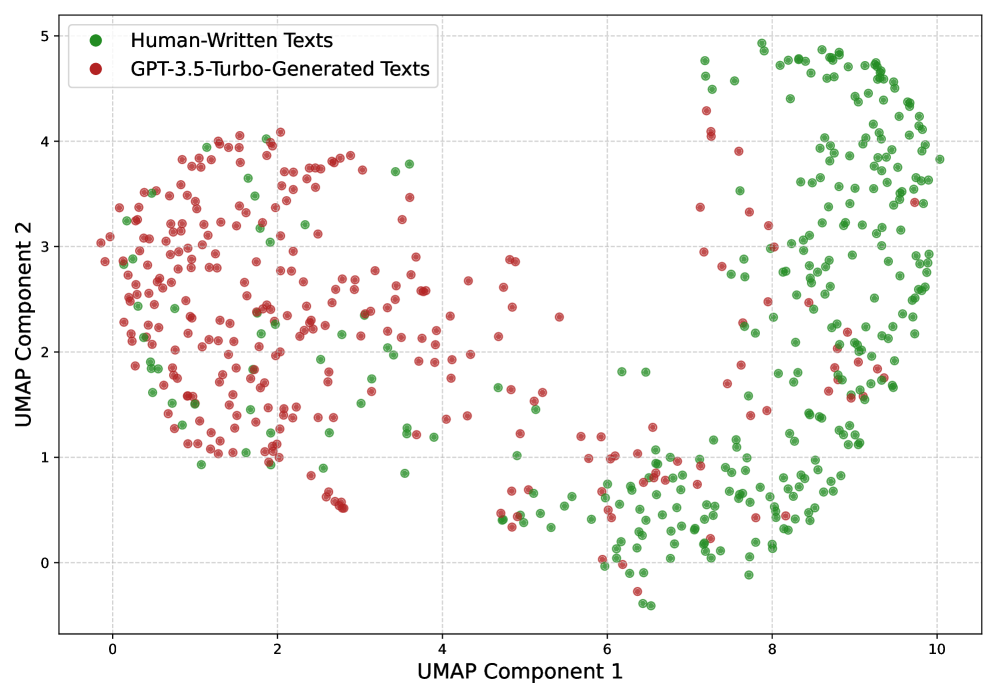
- StyleDecipher通过联合建模离散文体指标和连续文体表示,捕捉人与LLM输出在文体上的差异。
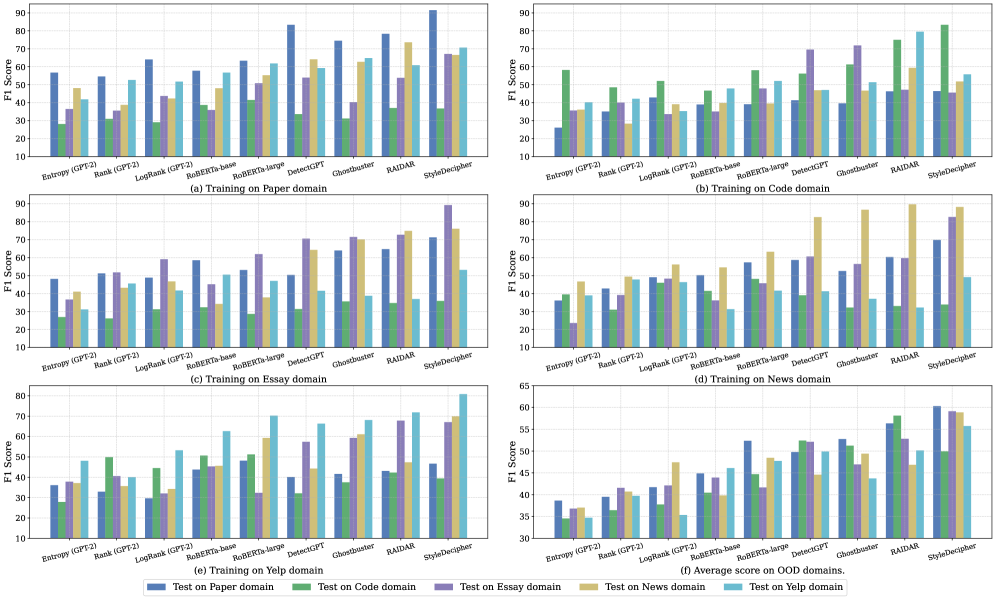
- 实验表明,StyleDecipher在多个领域超越现有方法,跨领域性能提升高达36.30%,并具有鲁棒性和可解释性。
📝 摘要(中文)
随着大型语言模型(LLMs)日益融入开放领域的写作,检测机器生成的文本已成为确保内容真实性和可信度的关键任务。现有方法依赖于统计差异或模型特定的启发式方法来区分LLM生成文本和人类书写文本。然而,由于泛化能力有限、易受释义攻击以及缺乏可解释性,这些方法在实际场景中表现不佳,尤其是在面对文体多样性或混合人机创作时。本文提出了StyleDecipher,一个鲁棒且可解释的检测框架,它通过结合特征提取器来量化文体差异,从而重新审视LLM生成文本的检测。通过联合建模离散文体指标和从语义嵌入导出的连续文体表示,StyleDecipher在一个统一的表示空间中捕获人类和LLM输出之间独特的文体层面的差异。该框架无需访问模型内部结构或标记的片段,即可实现准确、可解释且领域无关的检测。在包括新闻、代码、论文、评论和学术摘要在内的五个不同领域进行的大量实验表明,StyleDecipher始终如一地实现了最先进的同领域准确率。此外,在跨领域评估中,它超越了现有基线高达36.30%,同时保持了对对抗性扰动和混合人机内容的鲁棒性。进一步的定性和定量分析证实,文体信号为区分机器生成的文本提供了可解释的证据。我们的源代码可在https://github.com/SiyuanLi00/StyleDecipher访问。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成文本的检测问题。现有方法主要依赖统计差异或模型特定规则,但在实际应用中存在泛化能力不足、易受释义攻击以及缺乏可解释性等问题,尤其是在面对文体多样性或人机混合创作时,检测效果会显著下降。
核心思路:论文的核心思路是利用文体分析来区分LLM生成文本和人类书写文本。通过提取和建模文本的文体特征,捕捉两者在写作风格上的差异。这种方法不依赖于特定的LLM模型,因此具有更好的泛化能力,并且能够提供可解释的检测结果。
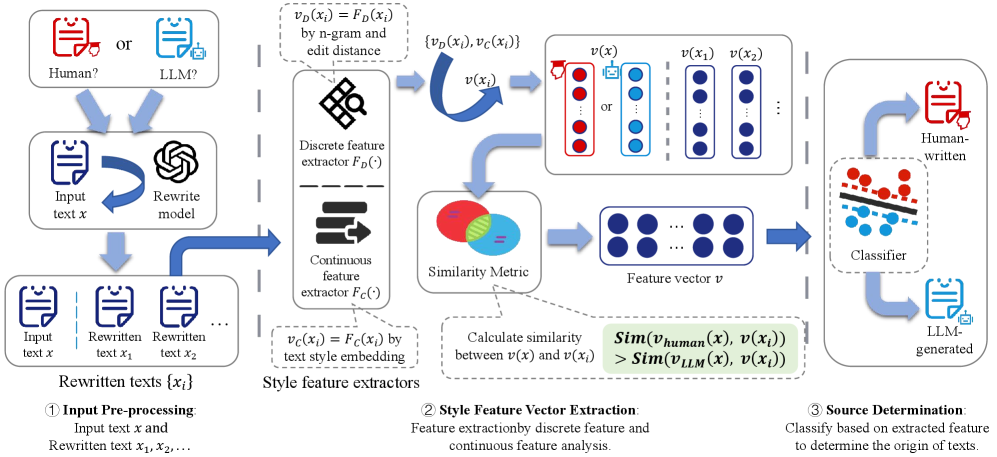
技术框架:StyleDecipher框架主要包含以下几个模块:1) 文本预处理;2) 离散文体特征提取,例如词汇多样性、句法复杂度等;3) 连续文体表示提取,通过语义嵌入模型(如BERT)获得文本的语义表示,并进一步提取文体相关的连续特征;4) 特征融合,将离散和连续文体特征进行融合;5) 分类器,使用机器学习模型(如SVM或神经网络)对融合后的特征进行分类,判断文本是否为LLM生成。
关键创新:该论文的关键创新在于结合了离散文体指标和连续文体表示,从而更全面地捕捉了文本的文体特征。与现有方法相比,StyleDecipher不依赖于特定的LLM模型,因此具有更好的泛化能力和鲁棒性。此外,通过分析文体特征,该方法能够提供可解释的检测结果,有助于理解LLM生成文本的特点。
关键设计:在离散文体特征方面,论文可能使用了如Type-Token Ratio (TTR)、平均句子长度、词汇多样性等指标。在连续文体表示方面,可能使用了预训练的语言模型(如BERT)提取文本的语义嵌入,并在此基础上进行降维或特征选择,以提取与文体相关的特征。分类器可以选择SVM、随机森林或神经网络等模型,并使用交叉验证等方法进行参数调优。
🖼️ 关键图片
📊 实验亮点
StyleDecipher在五个不同领域(新闻、代码、论文、评论和学术摘要)的实验中,始终如一地实现了最先进的同领域准确率。在跨领域评估中,它超越了现有基线高达36.30%,同时保持了对对抗性扰动和混合人机内容的鲁棒性。这些结果表明,StyleDecipher具有很强的实用价值。
🎯 应用场景
StyleDecipher可应用于内容审核、学术诚信检测、新闻真实性验证等领域。它可以帮助识别虚假信息、防止学术剽窃,并提高在线内容的质量和可信度。该研究有助于构建更安全、更可靠的在线环境,并促进人与AI的协同创作。
📄 摘要(原文)
With the increasing integration of large language models (LLMs) into open-domain writing, detecting machine-generated text has become a critical task for ensuring content authenticity and trust. Existing approaches rely on statistical discrepancies or model-specific heuristics to distinguish between LLM-generated and human-written text. However, these methods struggle in real-world scenarios due to limited generalization, vulnerability to paraphrasing, and lack of explainability, particularly when facing stylistic diversity or hybrid human-AI authorship. In this work, we propose StyleDecipher, a robust and explainable detection framework that revisits LLM-generated text detection using combined feature extractors to quantify stylistic differences. By jointly modeling discrete stylistic indicators and continuous stylistic representations derived from semantic embeddings, StyleDecipher captures distinctive style-level divergences between human and LLM outputs within a unified representation space. This framework enables accurate, explainable, and domain-agnostic detection without requiring access to model internals or labeled segments. Extensive experiments across five diverse domains, including news, code, essays, reviews, and academic abstracts, demonstrate that StyleDecipher consistently achieves state-of-the-art in-domain accuracy. Moreover, in cross-domain evaluations, it surpasses existing baselines by up to 36.30%, while maintaining robustness against adversarial perturbations and mixed human-AI content. Further qualitative and quantitative analysis confirms that stylistic signals provide explainable evidence for distinguishing machine-generated text. Our source code can be accessed at https://github.com/SiyuanLi00/StyleDecipher.