SMEC: Rethinking Matryoshka Representation Learning for Retrieval Embedding Compression
作者: Biao Zhang, Lixin Chen, Tong Liu, Bo Zheng
分类: cs.CL, cs.LG
发布日期: 2025-10-14
备注: Accepted by EMNLP2025
💡 一句话要点
提出SMEC框架,用于检索嵌入压缩,在保持性能的同时显著降低维度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 嵌入压缩 Matryoshka表示学习 信息检索 降维 自适应维度选择
📋 核心要点
- 高维嵌入增加了计算和存储负担,阻碍了大型语言模型在实际检索场景中的应用。
- SMEC框架通过顺序Matryoshka表示学习、自适应维度选择和可选择的跨批次记忆等模块,有效压缩嵌入。
- 实验表明,SMEC在图像、文本和多模态数据集上实现了显著的降维,并在性能上优于现有方法。
📝 摘要(中文)
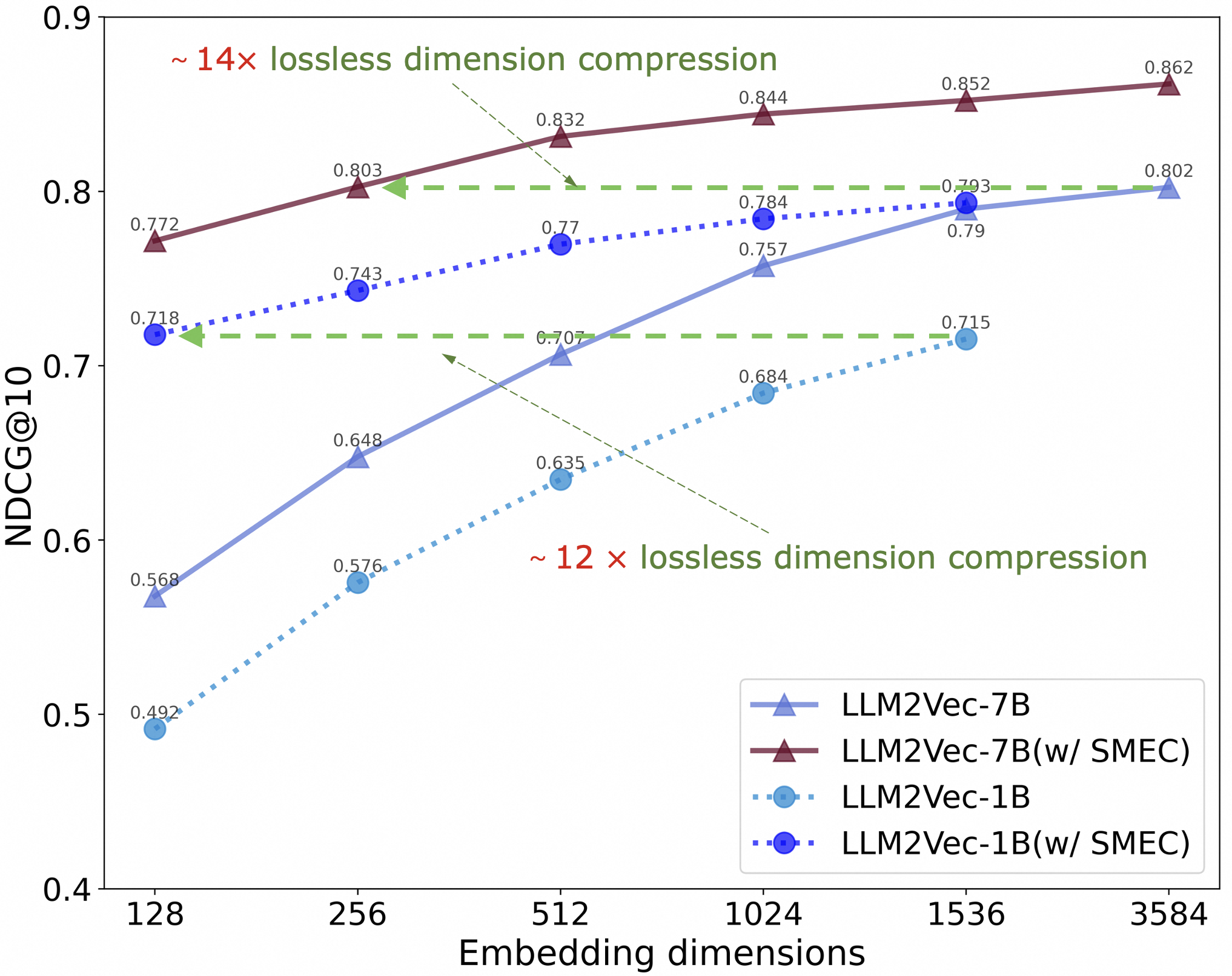
大型语言模型(LLMs)生成的高维嵌入捕获了丰富的语义和句法信息。然而,高维嵌入加剧了计算复杂性和存储需求,从而阻碍了实际部署。为了应对这些挑战,我们提出了一种名为顺序Matryoshka嵌入压缩(SMEC)的全新训练框架。该框架引入了顺序Matryoshka表示学习(SMRL)方法来减轻训练期间的梯度方差,自适应维度选择(ADS)模块来减少维度修剪期间的信息退化,以及可选择的跨批次记忆(S-XBM)模块来增强高维和低维嵌入之间的无监督学习。在图像、文本和多模态数据集上的实验表明,SMEC在保持性能的同时实现了显著的降维。例如,在BEIR数据集上,与Matryoshka-Adaptor和Search-Adaptor模型相比,我们的方法将压缩后的LLM2Vec嵌入(256维)的性能分别提高了1.1个点和2.7个点。
🔬 方法详解
问题定义:论文旨在解决高维嵌入在实际应用中带来的计算和存储瓶颈问题。现有方法在压缩嵌入时,容易造成信息损失,导致检索性能下降。因此,如何在保证检索性能的前提下,有效地压缩高维嵌入是本研究的核心问题。
核心思路:论文的核心思路是采用一种顺序的、自适应的Matryoshka表示学习方法,逐步压缩嵌入维度,并在此过程中尽量减少信息损失。通过引入自适应维度选择和跨批次记忆机制,进一步提升压缩后嵌入的质量。
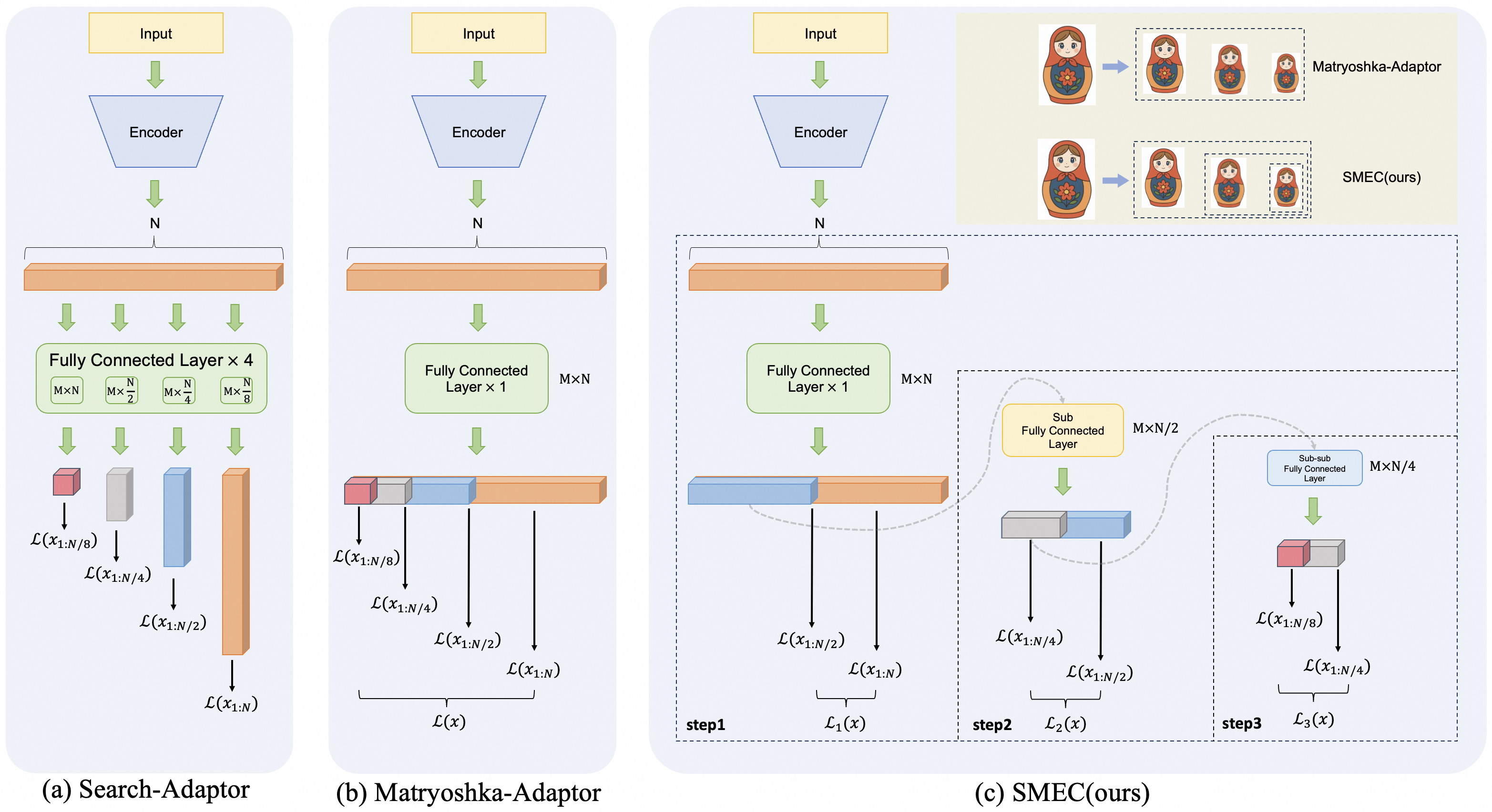
技术框架:SMEC框架包含三个主要模块:顺序Matryoshka表示学习(SMRL)、自适应维度选择(ADS)和可选择的跨批次记忆(S-XBM)。SMRL负责逐步压缩嵌入维度,ADS负责在压缩过程中选择最重要的维度,S-XBM则利用跨批次的信息来增强高维和低维嵌入之间的关联。整个框架以端到端的方式进行训练。
关键创新:论文的关键创新在于将Matryoshka表示学习与自适应维度选择和跨批次记忆机制相结合。SMRL减轻了训练过程中的梯度方差,ADS减少了维度修剪带来的信息损失,S-XBM则增强了高维和低维嵌入之间的无监督学习。这种组合方式使得SMEC能够在保持性能的同时实现更高的压缩率。
关键设计:SMRL采用顺序训练的方式,逐步减小嵌入维度。ADS模块使用一个可学习的权重来评估每个维度的重要性,并选择权重较高的维度进行保留。S-XBM模块维护一个跨批次的记忆库,用于存储高维和低维嵌入,并通过对比学习的方式来增强它们之间的关联。损失函数包括对比损失和维度选择损失,用于优化嵌入表示和维度选择过程。
🖼️ 关键图片

📊 实验亮点
实验结果表明,SMEC在图像、文本和多模态数据集上都取得了显著的性能提升。例如,在BEIR数据集上,SMEC将压缩后的LLM2Vec嵌入(256维)的性能分别提高了1.1个点和2.7个点,优于Matryoshka-Adaptor和Search-Adaptor模型。这表明SMEC在保持性能的同时,能够有效地压缩嵌入维度。
🎯 应用场景
该研究成果可广泛应用于信息检索、推荐系统、图像搜索等领域。通过压缩嵌入维度,可以降低存储成本、提高检索效率,并使得大型语言模型能够更好地部署在资源受限的设备上。未来,该方法还可以扩展到其他类型的嵌入压缩任务中,例如知识图谱嵌入、图神经网络嵌入等。
📄 摘要(原文)
Large language models (LLMs) generate high-dimensional embeddings that capture rich semantic and syntactic information. However, high-dimensional embeddings exacerbate computational complexity and storage requirements, thereby hindering practical deployment. To address these challenges, we propose a novel training framework named Sequential Matryoshka Embedding Compression (SMEC). This framework introduces the Sequential Matryoshka Representation Learning(SMRL) method to mitigate gradient variance during training, the Adaptive Dimension Selection (ADS) module to reduce information degradation during dimension pruning, and the Selectable Cross-batch Memory (S-XBM) module to enhance unsupervised learning between high- and low-dimensional embeddings. Experiments on image, text, and multimodal datasets demonstrate that SMEC achieves significant dimensionality reduction while maintaining performance. For instance, on the BEIR dataset, our approach improves the performance of compressed LLM2Vec embeddings (256 dimensions) by 1.1 points and 2.7 points compared to the Matryoshka-Adaptor and Search-Adaptor models, respectively.