Tokenization Disparities as Infrastructure Bias: How Subword Systems Create Inequities in LLM Access and Efficiency
作者: Hailay Kidu Teklehaymanot, Wolfgang Nejdl
分类: cs.CL, cs.AI
发布日期: 2025-10-14
备注: 6 pages 4 figures
💡 一句话要点
揭示分词差异中的基础设施偏差:子词系统如何造成LLM访问和效率的不平等
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 分词 大型语言模型 跨语言评估 计算公平性 低资源语言 子词分词 语言类型学
📋 核心要点
- 现有分词方法在处理不同语言时效率差异巨大,导致计算资源分配不均,尤其对非拉丁语系和低资源语言不利。
- 该研究通过大规模跨语言评估,量化了不同语言在LLM分词效率上的差异,揭示了底层基础设施偏差。
- 实验结果表明,非拉丁语系语言的分词成本显著高于拉丁语系语言,凸显了现有AI系统在语言公平性方面的不足。
📝 摘要(中文)
分词差异对不同语言人群公平获取人工智能资源构成了重大障碍。本研究对超过200种语言的分词效率进行了大规模跨语言评估,旨在系统地量化大型语言模型(LLM)中的计算不平等现象。我们采用标准化的实验框架,对所有语言样本应用一致的预处理和归一化协议,然后通过tiktoken库进行统一分词。使用诸如每句词元数(TPS)和相对分词成本(RTC)等既定评估指标,收集了全面的分词统计数据,并以英语为基准。跨语言分析揭示了显著且系统性的差异:拉丁语系语言始终表现出更高的分词效率,而非拉丁语系和形态复杂的语言则产生显著更高的词元膨胀,RTC比率通常高出3-5倍。这些低效率转化为更高的计算成本,并降低了代表性不足语言的有效上下文利用率。总体而言,研究结果突出了当前AI系统中的结构性不平等,低资源和非拉丁语系语言的使用者面临着不成比例的计算劣势。未来的研究应优先开发语言学驱动的分词策略和自适应词汇构建方法,纳入类型学多样性,确保更具包容性和计算公平性的多语言AI系统。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中由于分词器对不同语言的处理效率差异而导致的计算不平等问题。现有分词方法,特别是基于子词的分词方法,在处理形态复杂的语言或非拉丁语系语言时,往往会产生更多的token,导致更高的计算成本和更低的上下文利用率。这种不公平性使得这些语言的用户在访问和使用LLM时处于劣势。
核心思路:论文的核心思路是通过大规模的跨语言评估,量化不同语言在分词效率上的差异,从而揭示LLM基础设施中存在的偏差。通过系统地比较不同语言的分词成本,可以明确哪些语言在计算资源方面受到不成比例的影响,并为未来的改进方向提供依据。
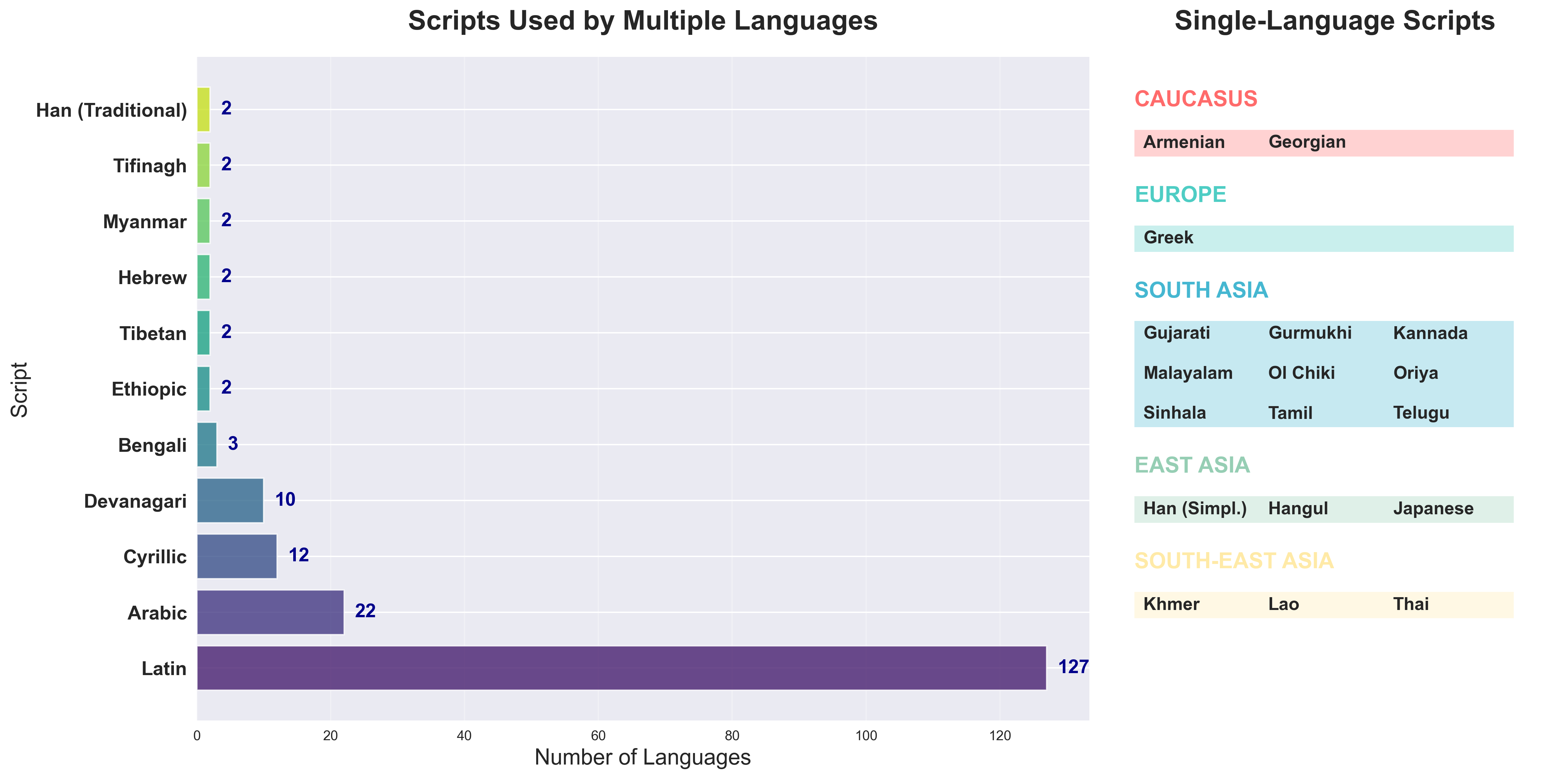
技术框架:该研究的技术框架主要包括以下几个步骤:1) 选择超过200种语言的文本数据;2) 对所有文本数据应用一致的预处理和归一化流程;3) 使用tiktoken库对所有文本进行分词;4) 收集分词统计数据,包括每句词元数(TPS)和相对分词成本(RTC);5) 以英语为基准,比较不同语言的分词效率。
关键创新:该研究的关键创新在于其大规模的跨语言评估方法,以及对分词效率差异的系统性量化。通过使用统一的实验框架和标准化的评估指标,该研究能够客观地比较不同语言的分词成本,并揭示LLM基础设施中存在的偏差。此外,该研究还强调了语言类型学多样性在分词策略设计中的重要性。
关键设计:研究中关键的设计包括:1) 使用tiktoken库进行统一分词,以确保不同语言的分词过程具有可比性;2) 选择每句词元数(TPS)和相对分词成本(RTC)作为评估指标,以量化分词效率;3) 以英语为基准,计算不同语言的RTC比率,以衡量其相对分词成本;4) 对所有文本数据应用一致的预处理和归一化流程,以减少噪声和偏差。
🖼️ 关键图片
📊 实验亮点
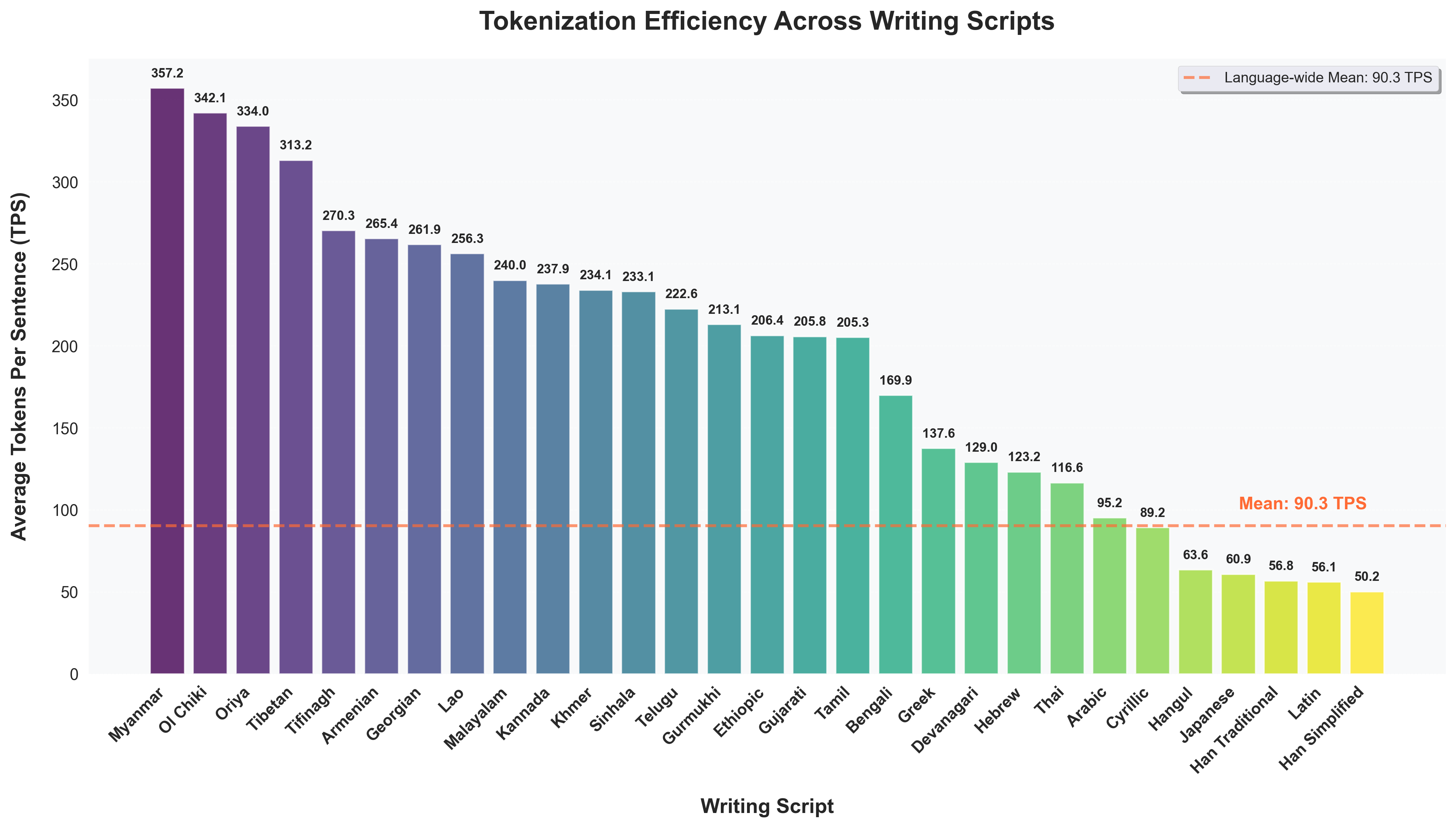
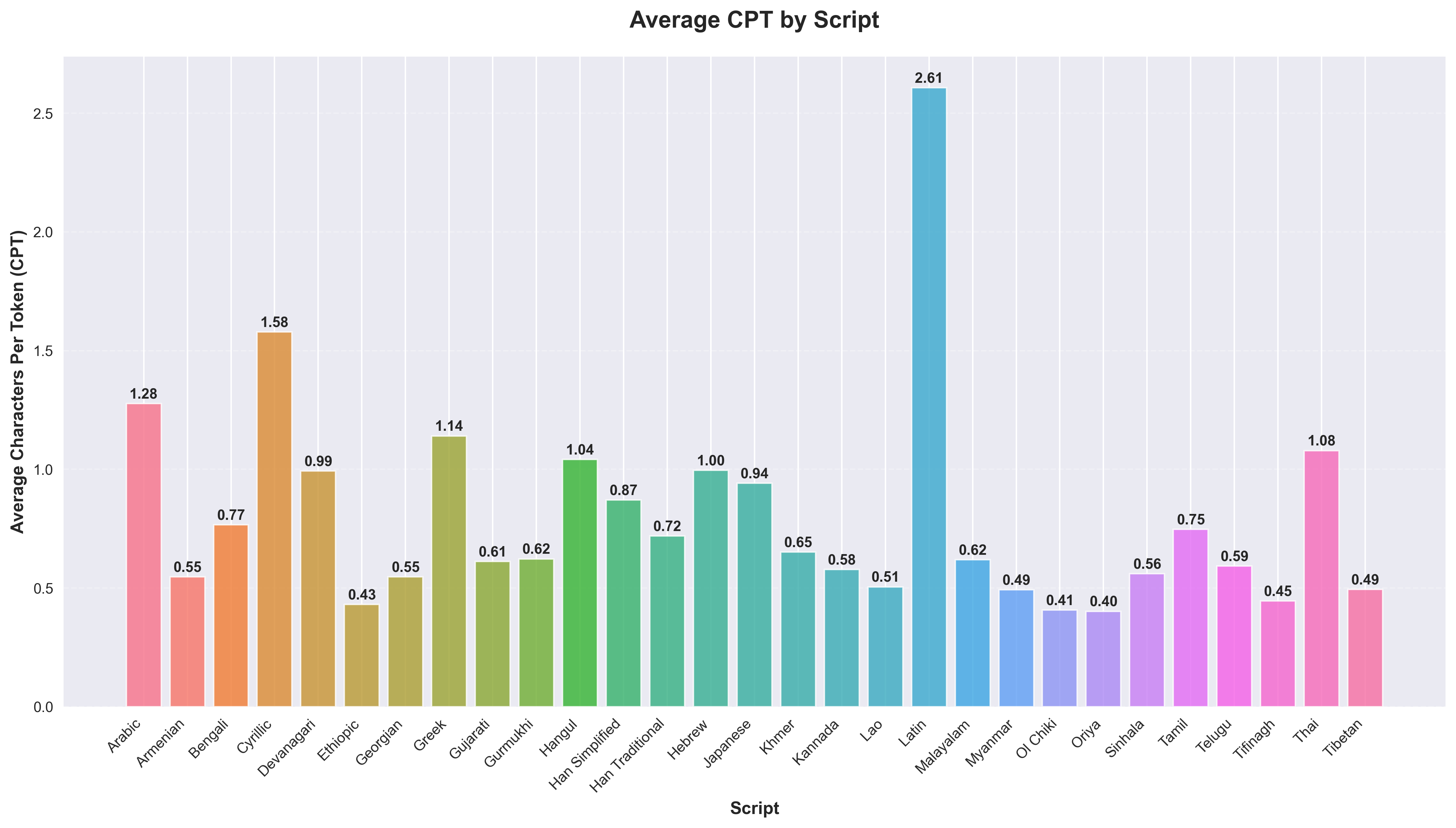
研究结果表明,非拉丁语系语言的分词成本显著高于拉丁语系语言,RTC比率通常高出3-5倍。例如,某些形态复杂的语言需要更多的token才能表达相同的信息,导致计算成本显著增加。这些发现突出了现有LLM在处理不同语言时的不公平性。
🎯 应用场景
该研究成果可应用于改进多语言LLM的设计,使其对所有语言更加公平和高效。通过开发语言学驱动的分词策略和自适应词汇构建方法,可以降低低资源语言的计算成本,提高其在LLM中的应用效果。这有助于促进全球范围内更广泛和公平地使用AI技术。
📄 摘要(原文)
Tokenization disparities pose a significant barrier to achieving equitable access to artificial intelligence across linguistically diverse populations. This study conducts a large-scale cross-linguistic evaluation of tokenization efficiency in over 200 languages to systematically quantify computational inequities in large language models (LLMs). Using a standardized experimental framework, we applied consistent preprocessing and normalization protocols, followed by uniform tokenization through the tiktoken library across all language samples. Comprehensive tokenization statistics were collected using established evaluation metrics, including Tokens Per Sentence (TPS) and Relative Tokenization Cost (RTC), benchmarked against English baselines. Our cross-linguistic analysis reveals substantial and systematic disparities: Latin-script languages consistently exhibit higher tokenization efficiency, while non-Latin and morphologically complex languages incur significantly greater token inflation, often 3-5 times higher RTC ratios. These inefficiencies translate into increased computational costs and reduced effective context utilization for underrepresented languages. Overall, the findings highlight structural inequities in current AI systems, where speakers of low-resource and non-Latin languages face disproportionate computational disadvantages. Future research should prioritize the development of linguistically informed tokenization strategies and adaptive vocabulary construction methods that incorporate typological diversity, ensuring more inclusive and computationally equitable multilingual AI systems.