LLM-REVal: Can We Trust LLM Reviewers Yet?
作者: Rui Li, Jia-Chen Gu, Po-Nien Kung, Heming Xia, Junfeng liu, Xiangwen Kong, Zhifang Sui, Nanyun Peng
分类: cs.CL, cs.AI
发布日期: 2025-10-14
💡 一句话要点
LLM-REVal:评估LLM作为评审者的可靠性,揭示其偏见与潜在风险
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 同行评审 学术公平 偏见分析 模拟研究
📋 核心要点
- 现有研究缺乏对LLM在学术研究和评审中双重角色可能带来的风险的深入探索,尤其是在公平性方面。
- 该研究通过模拟研究和评审过程,分析LLM作为评审者时存在的偏见,并评估其对学术公平性的影响。
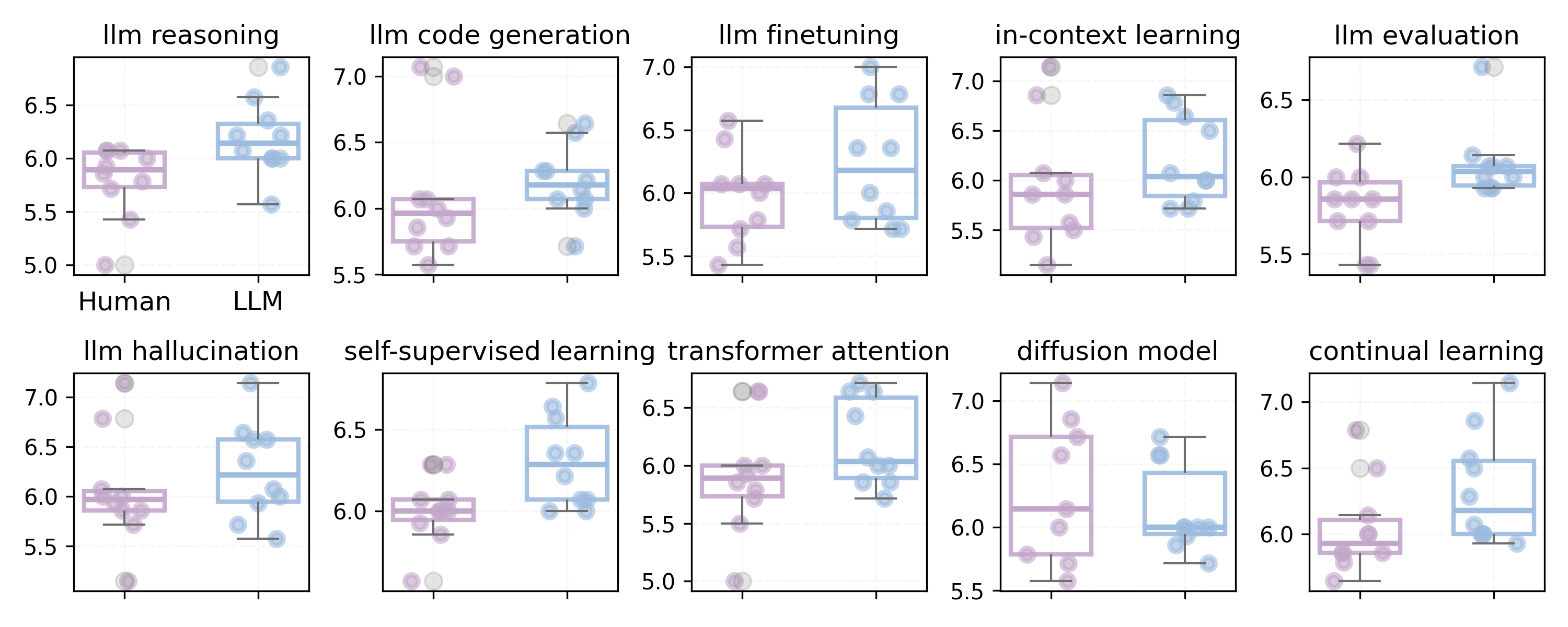
- 实验结果表明,LLM评审存在对LLM生成内容的偏袒和对批判性陈述的厌恶,但LLM评审指导的修改可以提升论文质量。
📝 摘要(中文)
大型语言模型(LLM)的快速发展促使研究人员将其广泛应用于学术工作流程中,可能重塑研究和评审的方式。虽然之前的研究强调了LLM在支持研究和同行评审方面的潜力,但它们在学术工作流程中的双重角色以及研究与评审之间复杂的相互作用带来了新的风险,这些风险在很大程度上尚未被探索。本研究侧重于LLM深度集成到同行评审和研究过程如何影响学术公平性,通过模拟来检验使用LLM作为评审者的潜在风险。该模拟包含一个研究代理,用于生成和修改论文,以及一个评审代理,用于评估提交的论文。基于模拟结果,我们进行了人工标注,并发现基于LLM的评审与人类判断之间存在明显的错位:(1)LLM评审系统性地夸大LLM撰写的论文的分数,给它们的分数明显高于人类撰写的论文;(2)LLM评审持续低估包含批判性陈述(例如,风险、公平性)的人类撰写的论文,即使经过多次修改。我们的分析表明,这些偏差源于LLM评审中的两个主要偏见:一种是偏爱LLM生成写作风格的语言特征偏见,另一种是对批判性陈述的反感。这些结果突出了如果LLM在没有充分谨慎的情况下被部署到同行评审周期中,对人类作者和学术研究构成的风险和公平性问题。另一方面,在LLM评审的指导下进行的修改在基于LLM和人类的评估中都产生了质量提升,这说明了LLM作为评审者对早期研究人员和提高低质量论文的潜力。
🔬 方法详解
问题定义:现有同行评审流程面临效率和公平性挑战。LLM的引入旨在提高效率,但其潜在偏见可能损害公平性,特别是当LLM同时参与论文撰写和评审时。现有方法未能充分评估这种双重角色带来的风险。
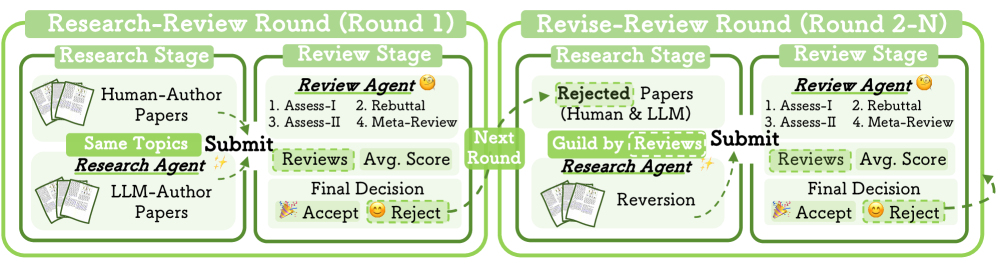
核心思路:通过构建一个模拟环境,其中包含一个研究代理(负责生成和修改论文)和一个评审代理(负责评估论文),来研究LLM作为评审者时的行为。该模拟允许控制论文的作者(LLM或人类)和内容(例如,包含批判性陈述),从而识别LLM评审中的偏见。
技术框架:该研究构建了一个包含研究代理和评审代理的模拟框架。研究代理使用LLM生成和修改论文,评审代理使用LLM对论文进行评分。通过控制论文的作者和内容,研究人员可以分析LLM评审在不同情况下的表现。此外,还进行了人工标注,以验证模拟结果并深入了解LLM评审的偏见。
关键创新:该研究的主要创新在于系统地评估了LLM在同行评审中的潜在偏见,并揭示了LLM评审对LLM生成内容的偏袒和对批判性陈述的厌恶。这与现有研究主要关注LLM在评审中的效率提升不同,更关注公平性问题。
关键设计:研究人员设计了实验,控制论文的作者(LLM或人类)和内容(是否包含批判性陈述)。他们使用不同的LLM作为研究代理和评审代理,并调整了LLM的参数以模拟不同的研究和评审风格。此外,他们还设计了人工标注流程,以验证模拟结果并深入了解LLM评审的偏见。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLM评审系统性地高估LLM撰写的论文,低估包含批判性陈述的人类撰写论文。具体来说,LLM评审给LLM撰写的论文的评分显著高于人类撰写的论文,即使在论文经过多次修改后,LLM评审仍然低估包含批判性陈述的人类撰写论文。然而,基于LLM评审的修改可以显著提高论文质量。
🎯 应用场景
该研究结果对学术出版领域具有重要意义,可以帮助期刊编辑和审稿人更好地理解LLM评审的局限性,并采取措施减轻其潜在偏见。此外,该研究还可以指导LLM评审系统的设计,使其更加公平和可靠。对于早期研究人员,LLM评审可以作为一种辅助工具,帮助他们改进论文质量。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has inspired researchers to integrate them extensively into the academic workflow, potentially reshaping how research is practiced and reviewed. While previous studies highlight the potential of LLMs in supporting research and peer review, their dual roles in the academic workflow and the complex interplay between research and review bring new risks that remain largely underexplored. In this study, we focus on how the deep integration of LLMs into both peer-review and research processes may influence scholarly fairness, examining the potential risks of using LLMs as reviewers by simulation. This simulation incorporates a research agent, which generates papers and revises, alongside a review agent, which assesses the submissions. Based on the simulation results, we conduct human annotations and identify pronounced misalignment between LLM-based reviews and human judgments: (1) LLM reviewers systematically inflate scores for LLM-authored papers, assigning them markedly higher scores than human-authored ones; (2) LLM reviewers persistently underrate human-authored papers with critical statements (e.g., risk, fairness), even after multiple revisions. Our analysis reveals that these stem from two primary biases in LLM reviewers: a linguistic feature bias favoring LLM-generated writing styles, and an aversion toward critical statements. These results highlight the risks and equity concerns posed to human authors and academic research if LLMs are deployed in the peer review cycle without adequate caution. On the other hand, revisions guided by LLM reviews yield quality gains in both LLM-based and human evaluations, illustrating the potential of the LLMs-as-reviewers for early-stage researchers and enhancing low-quality papers.