Fine-grained Analysis of Brain-LLM Alignment through Input Attribution
作者: Michela Proietti, Roberto Capobianco, Mariya Toneva
分类: cs.CL
发布日期: 2025-10-14
💡 一句话要点
提出细粒度输入归因方法,深入分析大脑与LLM对齐关系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大脑-LLM对齐 输入归因 下一个词预测 神经语言学 认知科学
📋 核心要点
- 现有研究对大脑与LLM的对齐关系理解不足,缺乏细粒度的分析方法来确定关键影响因素。
- 本文提出一种细粒度的输入归因方法,识别对大脑-LLM对齐至关重要的特定词语,从而深入分析对齐关系。
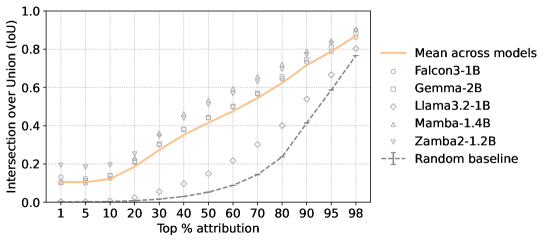
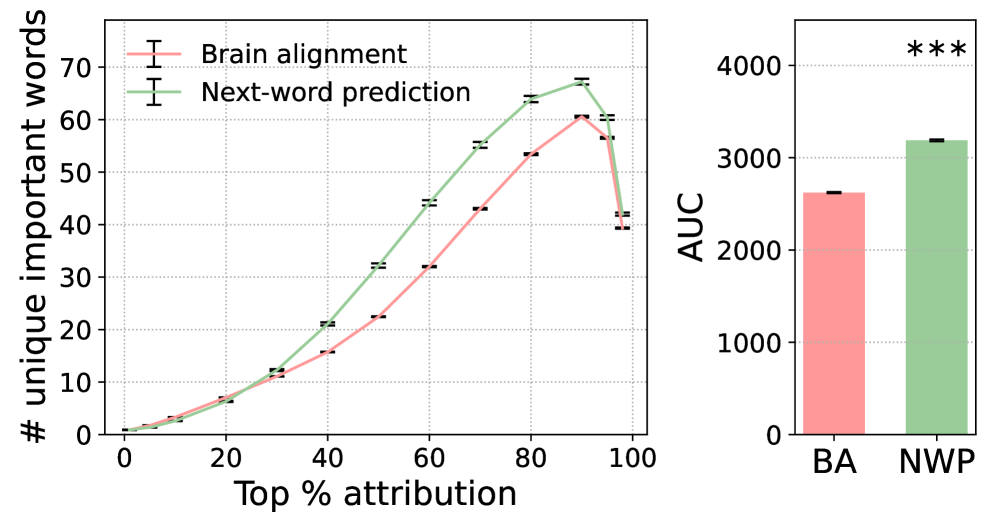
- 实验表明,大脑对齐和下一个词预测依赖于不同的词语子集,揭示了二者在特征依赖上的差异。
📝 摘要(中文)
为了理解大型语言模型(LLM)与人类大脑活动之间的对齐关系,从而揭示语言处理的计算原理,本文提出了一种细粒度的输入归因方法,用于识别对大脑-LLM对齐至关重要的特定词语。利用该方法,我们研究了一个关于大脑-LLM对齐的争议性问题:大脑对齐(BA)与下一个词预测(NWP)之间的关系。研究结果表明,BA和NWP依赖于很大程度上不同的词语子集:NWP表现出近因和首因效应,侧重于语法,而BA优先考虑语义和语篇层面的信息,并具有更有针对性的近因效应。这项工作加深了我们对LLM与人类语言处理之间关系的理解,并突出了BA和NWP在特征依赖方面的差异。除了这项研究,我们的归因方法可以广泛应用于探索模型预测在各种语言处理任务中的认知相关性。
🔬 方法详解
问题定义:现有方法难以细粒度地分析大脑与LLM的对齐关系,无法确定哪些词语对大脑对齐(BA)和下一个词预测(NWP)的影响最大。这阻碍了我们深入理解LLM如何模拟人类语言处理,以及BA和NWP之间是否存在差异。
核心思路:本文的核心思路是开发一种细粒度的输入归因方法,该方法能够识别输入文本中对BA和NWP贡献最大的词语。通过比较这些关键词语,可以揭示BA和NWP在特征依赖上的差异,从而更深入地理解大脑与LLM的对齐关系。
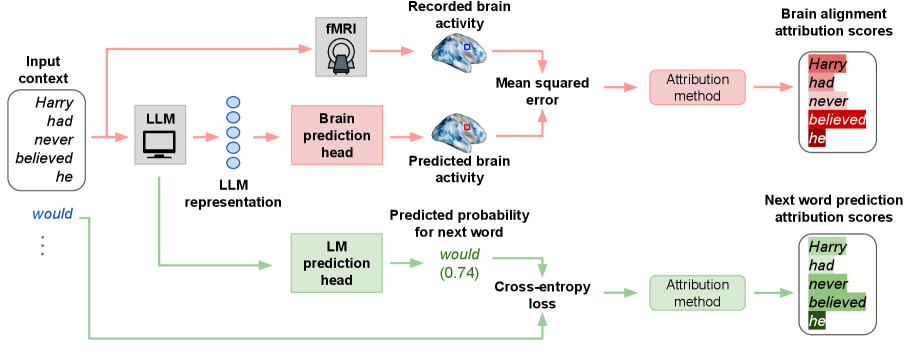
技术框架:该方法主要包含以下几个步骤:1) 选择合适的LLM和大脑活动数据;2) 使用输入归因方法(具体方法未明确说明,但应能计算每个词语对模型预测或大脑活动的影响)计算每个词语的归因得分;3) 分析归因得分,识别对BA和NWP贡献最大的词语;4) 比较BA和NWP的关键词语,分析二者在特征依赖上的差异。
关键创新:该方法最重要的创新点在于其细粒度的输入归因能力,能够识别对大脑-LLM对齐至关重要的特定词语。这与以往研究中笼统地比较整个句子或段落的表示不同,能够更精确地揭示BA和NWP的特征依赖。
关键设计:论文中未明确说明具体的输入归因方法,以及如何将归因得分与大脑活动数据关联。这些是实现该方法的关键技术细节,需要根据具体的数据和模型进行选择和设计。例如,可以使用梯度积分、LIME等方法进行输入归因,并使用相关性分析等方法将归因得分与大脑活动数据关联。
🖼️ 关键图片
📊 实验亮点
研究发现,大脑对齐(BA)和下一个词预测(NWP)依赖于不同的词语子集。NWP表现出近因和首因效应,侧重于语法,而BA优先考虑语义和语篇层面的信息,并具有更有针对性的近因效应。这些发现揭示了BA和NWP在特征依赖上的差异,为理解大脑与LLM的对齐关系提供了新的视角。
🎯 应用场景
该研究成果可应用于神经语言学、认知科学等领域,帮助研究人员更深入地理解人类语言处理机制。此外,该方法还可以用于评估LLM的认知合理性,指导LLM的改进和优化,使其更接近人类的语言处理方式。未来,该方法有望应用于人机交互、自然语言理解等领域。
📄 摘要(原文)
Understanding the alignment between large language models (LLMs) and human brain activity can reveal computational principles underlying language processing. We introduce a fine-grained input attribution method to identify the specific words most important for brain-LLM alignment, and leverage it to study a contentious research question about brain-LLM alignment: the relationship between brain alignment (BA) and next-word prediction (NWP). Our findings reveal that BA and NWP rely on largely distinct word subsets: NWP exhibits recency and primacy biases with a focus on syntax, while BA prioritizes semantic and discourse-level information with a more targeted recency effect. This work advances our understanding of how LLMs relate to human language processing and highlights differences in feature reliance between BA and NWP. Beyond this study, our attribution method can be broadly applied to explore the cognitive relevance of model predictions in diverse language processing tasks.