Analysing Moral Bias in Finetuned LLMs through Mechanistic Interpretability
作者: Bianca Raimondi, Daniela Dalbagno, Maurizio Gabbrielli
分类: cs.CL, cs.AI
发布日期: 2025-10-14 (更新: 2025-12-05)
备注: Preprint. Under review
💡 一句话要点
通过机制可解释性分析微调LLM中的道德偏见,并提出缓解方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 道德偏见 机制可解释性 层修补分析 Knobe效应
📋 核心要点
- 现有研究缺乏对LLM中道德偏见产生机制的深入理解,难以有效缓解。
- 通过层修补分析,定位并消除微调LLM中由Knobe效应引起的道德偏见。
- 实验表明,仅需修补少量关键层即可有效消除偏见,无需模型重训练。
📝 摘要(中文)
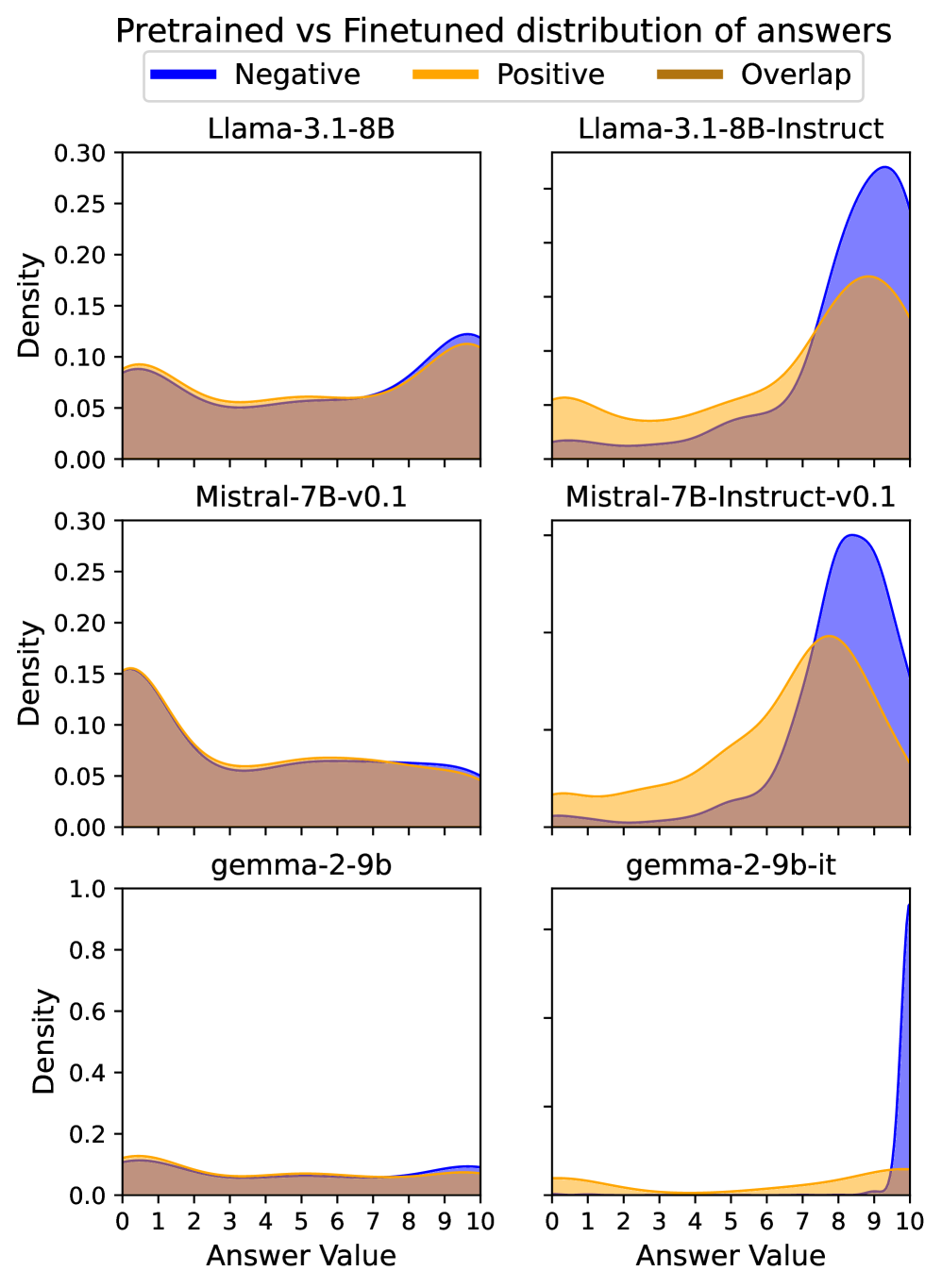
大型语言模型(LLMs)在微调过程中表现出对类人偏见的内化,但这些偏见显现的机制仍不清楚。本文研究了著名的Knobe效应(一种关于意图判断的道德偏见)是否出现在微调后的LLM中,以及是否可以追溯到模型的特定组成部分。我们对3个开源LLM进行了层修补分析,证明了这种偏见不仅在微调过程中被学习,而且还位于特定的层中。令人惊讶的是,我们发现将来自相应预训练模型的激活值修补到几个关键层中就足以消除这种效应。我们的研究结果提供了新的证据,表明LLM中的社会偏见可以通过有针对性的干预进行解释、定位和缓解,而无需重新训练模型。
🔬 方法详解
问题定义:论文旨在解决微调后的大型语言模型(LLM)中存在的道德偏见问题,特别是Knobe效应。现有的方法通常关注于检测和减轻LLM中的偏见,但缺乏对偏见产生机制的深入理解,难以进行有针对性的干预。因此,如何理解和定位LLM中的道德偏见,并在此基础上提出有效的缓解方法,是本文要解决的核心问题。
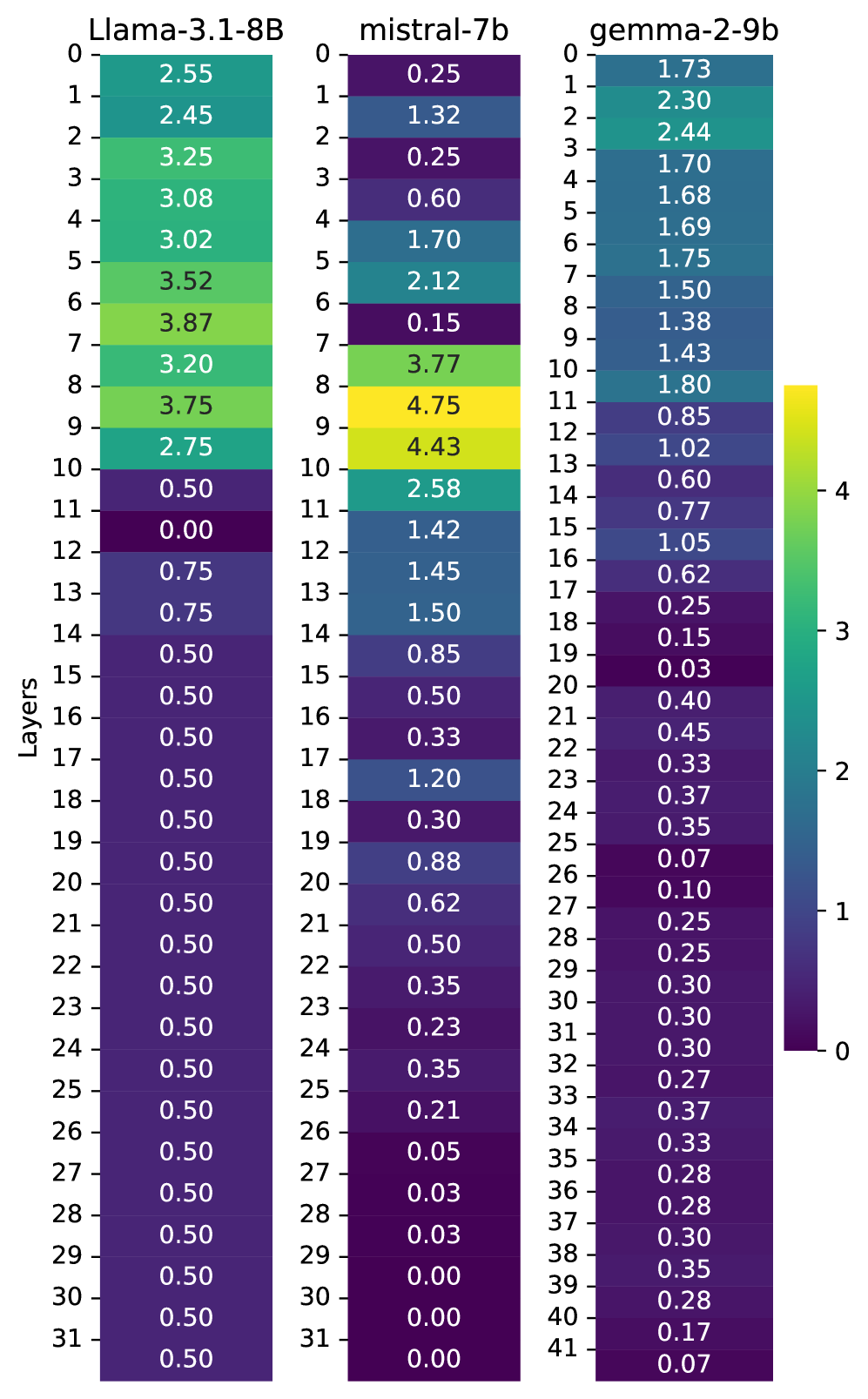
核心思路:论文的核心思路是通过机制可解释性方法,具体而言是层修补分析,来定位LLM中负责产生道德偏见的特定层。通过将微调模型的激活值替换为预训练模型的激活值,观察模型行为的变化,从而确定哪些层对Knobe效应的产生起关键作用。这种方法允许研究者在不重新训练模型的情况下,通过干预特定层来减轻或消除偏见。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择具有代表性的开源LLM进行微调;2) 设计针对Knobe效应的测试用例,评估微调后模型的偏见程度;3) 使用层修补分析方法,逐层将微调模型的激活值替换为预训练模型的激活值,并观察模型在Knobe效应测试用例上的表现;4) 确定对Knobe效应影响最大的关键层;5) 验证通过修补这些关键层是否能够有效消除或减轻偏见。
关键创新:论文的关键创新在于:1) 将机制可解释性方法应用于分析LLM中的道德偏见,为理解偏见的产生机制提供了新的视角;2) 发现LLM中的道德偏见可以被定位到特定的层,这为有针对性的干预提供了可能;3) 提出了一种无需重新训练模型即可有效减轻或消除偏见的方法,具有重要的实际意义。
关键设计:论文的关键设计包括:1) 针对Knobe效应设计了特定的测试用例,用于评估模型的道德偏见;2) 使用层修补分析方法,系统地评估了每一层对Knobe效应的影响;3) 选择了多个开源LLM进行实验,以验证方法的普适性;4) 实验中使用了预训练模型的激活值作为修补目标,以消除微调过程中引入的偏见。
🖼️ 关键图片

📊 实验亮点
实验结果表明,微调后的LLM确实表现出Knobe效应,即道德偏见。通过层修补分析,研究者成功定位了对该效应起关键作用的特定层。更重要的是,他们发现仅需将预训练模型的激活值修补到这些关键层,即可显著降低甚至消除Knobe效应,而无需重新训练整个模型。这一发现为缓解LLM中的偏见提供了一种高效且经济的方法。
🎯 应用场景
该研究成果可应用于开发更安全、更可靠的LLM,减少模型在实际应用中产生有害偏见的风险。例如,在金融、医疗、法律等对公平性要求较高的领域,可以利用该方法分析和消除LLM中的偏见,提高模型的决策质量和可信度。此外,该研究也为开发更有效的偏见缓解工具和技术提供了理论基础。
📄 摘要(原文)
Large language models (LLMs) have been shown to internalize human-like biases during finetuning, yet the mechanisms by which these biases manifest remain unclear. In this work, we investigated whether the well-known Knobe effect, a moral bias in intentionality judgements, emerges in finetuned LLMs and whether it can be traced back to specific components of the model. We conducted a Layer-Patching analysis across 3 open-weights LLMs and demonstrated that the bias is not only learned during finetuning but also localized in a specific set of layers. Surprisingly, we found that patching activations from the corresponding pretrained model into just a few critical layers is sufficient to eliminate the effect. Our findings offer new evidence that social biases in LLMs can be interpreted, localized, and mitigated through targeted interventions, without the need for model retraining.