Not in Sync: Unveiling Temporal Bias in Audio Chat Models
作者: Jiayu Yao, Shenghua Liu, Yiwei Wang, Rundong Cheng, Lingrui Mei, Baolong Bi, Zhen Xiong, Xueqi Cheng
分类: cs.CL, cs.SD
发布日期: 2025-10-14
💡 一句话要点
揭示音频聊天模型中的时间偏差,提出TBI指标进行量化
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 时间偏差 时间戳预测 音频理解 多模态推理
📋 核心要点
- 现有大型音频语言模型在时间定位能力上存在不足,无法准确预测事件发生的时间戳。
- 论文提出通过时间偏差指数(TBI)来量化模型在时间预测上的系统性偏差,并进行可视化分析。
- 实验表明,时间偏差普遍存在,且随音频长度增加而增大,不同事件类型和位置也会影响偏差。
📝 摘要(中文)
大型音频语言模型(LALM)越来越多地应用于音频理解和多模态推理,但它们定位事件发生时间的能力仍未得到充分探索。本文首次系统地研究了LALM中的时间偏差,揭示了其时间戳预测的一个关键局限性。例如,当被问及“讲师在哪一秒介绍了关键公式?”时,模型通常预测的时间戳始终早于或晚于真实值。通过对带有时间戳的数据集进行受控实验,我们发现时间偏差(i)普遍存在于数据集和模型中,(ii)随着音频长度的增加而增加——即使在较长的录音中也会累积到数十秒,并且(iii)因事件类型和位置而异。我们使用时间偏差指数(TBI)来量化这种影响,该指数衡量预测事件时间中的系统性错位,并辅以可视化框架。我们的发现突出了当前LALM的一个根本局限性,并呼吁开发时间上鲁棒的架构。
🔬 方法详解
问题定义:现有的大型音频语言模型(LALM)在音频理解和多模态推理中表现出色,但它们在精确定位音频事件发生时间方面的能力存在明显缺陷。具体来说,模型在预测事件的时间戳时,经常出现系统性的偏差,即预测的时间戳总是早于或晚于实际发生的时间。这种时间偏差会严重影响模型在需要精确时间信息的任务中的性能,例如视频字幕生成、音频事件检测等。
核心思路:论文的核心思路是系统性地研究和量化LALM中的时间偏差。通过设计受控实验,分析时间偏差在不同数据集、模型、音频长度、事件类型和位置上的表现。为了更精确地量化这种偏差,论文提出了时间偏差指数(Temporal Bias Index, TBI),用于衡量预测时间戳与真实时间戳之间的系统性错位程度。
技术框架:论文的技术框架主要包括以下几个部分:1) 构建带有精确时间戳的音频数据集;2) 选择具有代表性的LALM模型进行实验;3) 设计受控实验,改变音频长度、事件类型和位置等因素;4) 使用TBI指标量化模型预测的时间偏差;5) 设计可视化框架,直观地展示时间偏差的分布情况。整体流程旨在全面评估和理解LALM中的时间偏差问题。
关键创新:论文最重要的技术创新点在于首次系统地研究了LALM中的时间偏差问题,并提出了TBI指标来量化这种偏差。以往的研究主要关注LALM在音频分类、语音识别等任务上的性能,而忽略了其在时间定位方面的能力。TBI指标提供了一种量化时间偏差的有效方法,可以用于评估不同LALM模型的时间鲁棒性,并指导模型的设计和优化。
关键设计:TBI的计算方式是预测时间戳与真实时间戳之差的平均值,可以反映模型预测的系统性偏差方向和大小。论文还设计了可视化框架,用于展示时间偏差在不同音频段、不同事件类型上的分布情况。此外,论文在实验中控制了音频长度、事件类型和位置等因素,以便更全面地分析时间偏差的影响因素。
🖼️ 关键图片

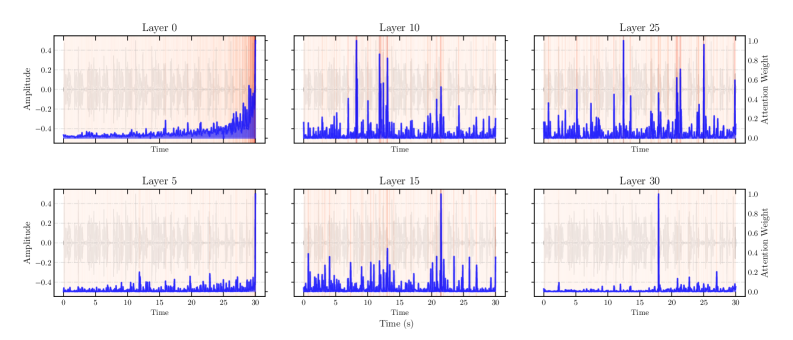
📊 实验亮点
实验结果表明,时间偏差普遍存在于LALM中,并且随着音频长度的增加而显著增大。在某些情况下,时间偏差甚至可以累积到数十秒。通过TBI指标,论文量化了不同模型和数据集上的时间偏差,并发现不同事件类型和位置也会影响偏差的大小。这些发现为改进LALM的时间定位能力提供了重要的依据。
🎯 应用场景
该研究成果可应用于提升音频事件定位的准确性,例如在视频监控中精确定位异常声音事件,或在语音助手应用中准确理解用户指令的时间信息。未来的研究可以基于此,开发时间鲁棒性更强的音频语言模型,从而提高模型在各种实际应用中的性能。
📄 摘要(原文)
Large Audio Language Models (LALMs) are increasingly applied to audio understanding and multimodal reasoning, yet their ability to locate when events occur remains underexplored. We present the first systematic study of temporal bias in LALMs, revealing a key limitation in their timestamp prediction. For example, when asked "At which second does the lecturer introduce the key formula?", models often predict timestamps that are consistently earlier or later than the ground truth. Through controlled experiments on timestamped datasets, we find that temporal bias (i) is prevalent across datasets and models, (ii) increases with audio length - even accumulating to tens of seconds in extended recordings, and (iii) varies across event types and positions. We quantify this effect with the Temporal Bias Index (TBI), measuring systematic misalignment in predicted event timings, and complement it with a visualization framework. Our findings highlight a fundamental limitation in current LALMs and call for the development of temporally robust architectures.