From Knowledge to Treatment: Large Language Model Assisted Biomedical Concept Representation for Drug Repurposing
作者: Chengrui Xiang, Tengfei Ma, Xiangzheng Fu, Yiping Liu, Bosheng Song, Xiangxiang Zeng
分类: cs.CL, cs.AI
发布日期: 2025-10-14
备注: 16 pages, 4 figures, 13 tables. Accepted by EMNLP 2025 (Findings)
🔗 代码/项目: GITHUB
💡 一句话要点
LLaDR:利用大语言模型辅助生物医学概念表示,用于药物重定向
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 药物重定向 知识图谱嵌入 大型语言模型 生物医学概念表示 语义理解
📋 核心要点
- 现有药物重定向方法忽略了生物医学知识图谱中常见的常识性生物医学概念知识,限制了其性能。
- LLaDR框架利用大型语言模型提取生物医学实体的语义信息,并将其注入知识图谱嵌入模型,从而增强概念表示。
- 实验表明,LLaDR在药物重定向任务中取得了最先进的性能,并在阿尔茨海默病案例研究中表现出稳健性和有效性。
📝 摘要(中文)
药物重定向在加速治疗发现方面起着关键作用,尤其是在复杂和罕见疾病方面。生物医学知识图谱(KGs)编码了丰富的临床关联,已被广泛用于支持这项任务。然而,现有方法在很大程度上忽略了现实实验室中常见的生物医学概念知识,例如表明某些药物从根本上与特定治疗不相容的机制性先验知识。为了解决这一差距,我们提出了LLaDR,一个大语言模型辅助的药物重定向框架,它改进了KG中生物医学概念的表示。具体来说,我们从大型语言模型(LLMs)中提取语义丰富的治疗相关生物医学实体文本表示,并使用它们来微调知识图谱嵌入(KGE)模型。通过将治疗相关知识注入KGE,LLaDR在很大程度上改善了生物医学概念的表示,增强了对研究不足或复杂适应症的语义理解。基于基准的实验表明,LLaDR在不同场景中实现了最先进的性能,对阿尔茨海默病的案例研究进一步证实了其稳健性和有效性。
🔬 方法详解
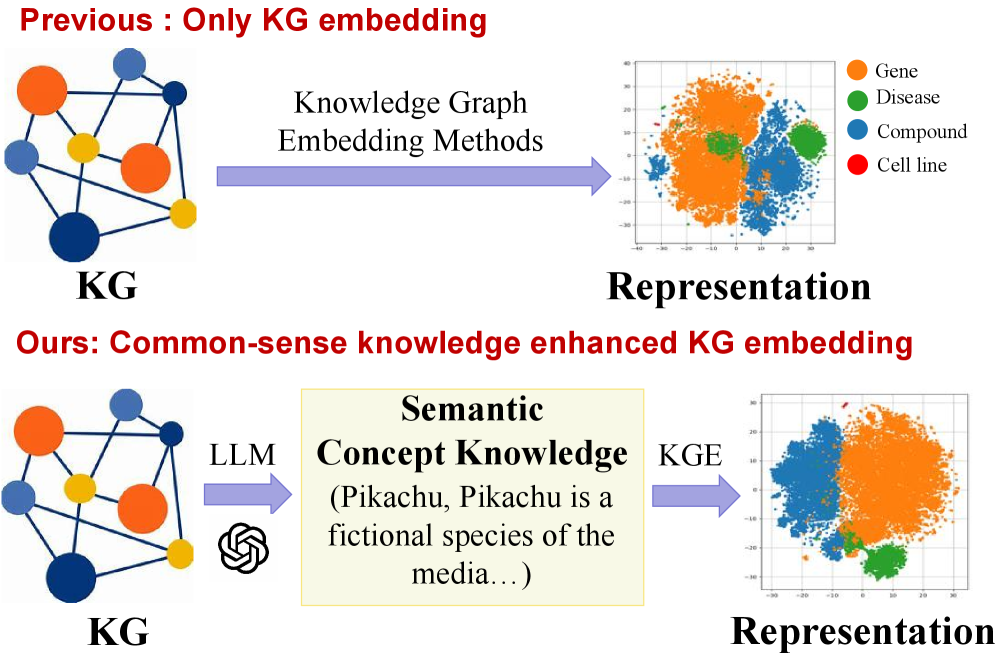
问题定义:现有药物重定向方法依赖于生物医学知识图谱,但忽略了现实世界中常见的生物医学常识,例如药物与治疗的不相容性。这导致知识图谱嵌入模型无法充分捕捉生物医学概念的语义信息,从而影响药物重定向的准确性。现有方法难以有效利用大型语言模型中蕴含的丰富生物医学知识。
核心思路:LLaDR的核心思路是利用大型语言模型(LLMs)提取生物医学实体的语义表示,并将这些表示融入知识图谱嵌入(KGE)模型中。通过这种方式,LLaDR能够将LLMs的常识性知识注入KGE模型,从而改善生物医学概念的表示,提高药物重定向的性能。这样设计的原因在于,LLMs拥有海量的文本数据,能够捕捉到KG中难以直接表示的语义信息。
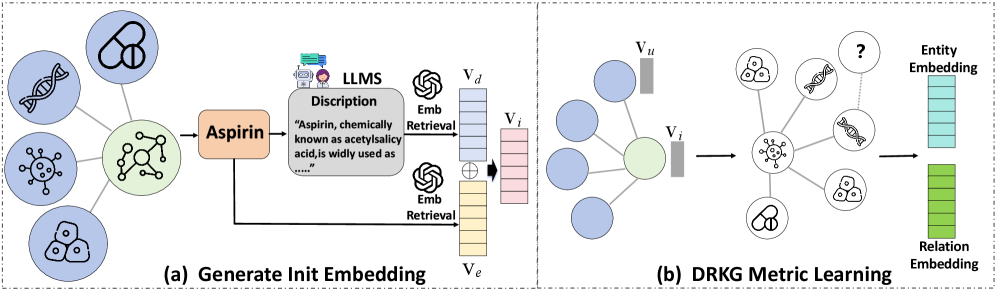
技术框架:LLaDR框架主要包含两个阶段:1) 利用LLMs提取生物医学实体的文本表示。具体来说,对于KG中的每个实体,LLaDR使用LLM生成包含该实体信息的文本描述,然后将这些文本描述输入到LLM中,得到该实体的语义向量表示。2) 利用这些语义向量表示微调KGE模型。LLaDR将LLM提取的语义向量表示作为KGE模型的输入特征,通过微调KGE模型,使其能够更好地捕捉生物医学概念的语义信息。
关键创新:LLaDR的关键创新在于将大型语言模型与知识图谱嵌入模型相结合,利用LLMs的语义理解能力来增强KGE模型的表示能力。与现有方法相比,LLaDR能够更好地捕捉生物医学概念的语义信息,从而提高药物重定向的准确性。现有方法通常直接使用KG的结构信息进行嵌入,忽略了文本中蕴含的丰富语义信息。
关键设计:LLaDR的关键设计包括:1) 如何有效地利用LLMs生成生物医学实体的文本描述。论文可能使用了特定的prompt工程技术来引导LLMs生成高质量的文本描述。2) 如何将LLM提取的语义向量表示融入KGE模型中。论文可能使用了特定的融合策略,例如将语义向量表示作为KGE模型的输入特征,或者使用注意力机制来加权不同的特征。具体的损失函数和网络结构细节未知。
🖼️ 关键图片
📊 实验亮点
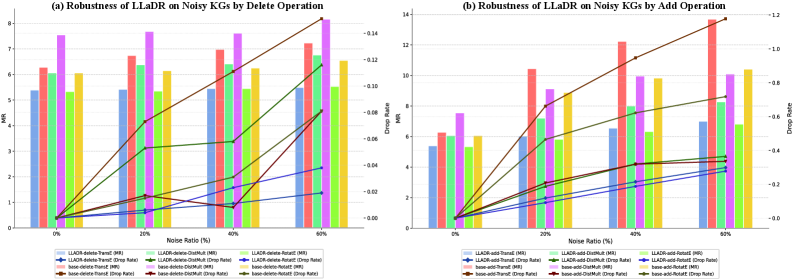
LLaDR在药物重定向基准测试中取得了最先进的性能。在阿尔茨海默病案例研究中,LLaDR展现了其稳健性和有效性,能够识别潜在的治疗药物。具体的性能提升数据未知,但摘要强调了其在不同场景下的SOTA表现。
🎯 应用场景
LLaDR在药物重定向领域具有广泛的应用前景,可以加速新药发现,尤其是在罕见病和复杂疾病的治疗方面。该方法可以帮助研究人员更好地理解药物与疾病之间的关系,从而发现新的治疗靶点和药物组合。此外,LLaDR还可以应用于个性化医疗,根据患者的基因组信息和临床数据,为患者推荐最合适的药物。
📄 摘要(原文)
Drug repurposing plays a critical role in accelerating treatment discovery, especially for complex and rare diseases. Biomedical knowledge graphs (KGs), which encode rich clinical associations, have been widely adopted to support this task. However, existing methods largely overlook common-sense biomedical concept knowledge in real-world labs, such as mechanistic priors indicating that certain drugs are fundamentally incompatible with specific treatments. To address this gap, we propose LLaDR, a Large Language Model-assisted framework for Drug Repurposing, which improves the representation of biomedical concepts within KGs. Specifically, we extract semantically enriched treatment-related textual representations of biomedical entities from large language models (LLMs) and use them to fine-tune knowledge graph embedding (KGE) models. By injecting treatment-relevant knowledge into KGE, LLaDR largely improves the representation of biomedical concepts, enhancing semantic understanding of under-studied or complex indications. Experiments based on benchmarks demonstrate that LLaDR achieves state-of-the-art performance across different scenarios, with case studies on Alzheimer's disease further confirming its robustness and effectiveness. Code is available at https://github.com/xiaomingaaa/LLaDR.