Deep Associations, High Creativity: A Simple yet Effective Metric for Evaluating Large Language Models
作者: Ziliang Qiu, Renfen Hu
分类: cs.CL, cs.AI
发布日期: 2025-10-14
备注: 14 pages
💡 一句话要点
提出PACE:一种简单高效的LLM创造力评估指标,避免数据污染且与人类评估高度相关
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 创造力评估 联想链 数据污染 自动化评估
📋 核心要点
- 现有LLM创造力评估方法易受数据污染影响,且人工评估成本高昂,限制了研究进展。
- PACE通过要求LLM生成并行联想链,模拟人类创造力评估,降低数据污染风险,实现高效评估。
- 实验表明PACE与人类评估结果高度相关,并揭示了LLM与人类在联想创造力上的差异。
📝 摘要(中文)
大型语言模型(LLM)创造力的评估是一个重要的研究领域,但数据污染和昂贵的人工评估常常阻碍进展。受人类创造力评估的启发,我们提出了PACE,即要求LLM生成并行联想链来评估其创造力。PACE最大限度地降低了数据污染的风险,并提供了一种直接、高效的评估方法。通过对各种专有和开源模型的评估,PACE与Chatbot Arena创意写作排名表现出很强的相关性(Spearman's ρ= 0.739,p < 0.001)。对LLM和人类联想创造力的比较分析表明,虽然高性能LLM的得分可与普通人类的表现相媲美,但专业人士的表现始终优于LLM。此外,语言分析表明,人类和LLM都表现出联想具体性降低的趋势,并且人类表现出更大的联想模式多样性。
🔬 方法详解
问题定义:论文旨在解决如何有效且可靠地评估大型语言模型(LLM)的创造力这一问题。现有的评估方法,如依赖于预先存在的数据集,容易受到数据污染的影响,即LLM可能已经在训练过程中见过这些数据,从而导致评估结果失真。此外,依赖人工评估成本高昂,难以大规模应用。
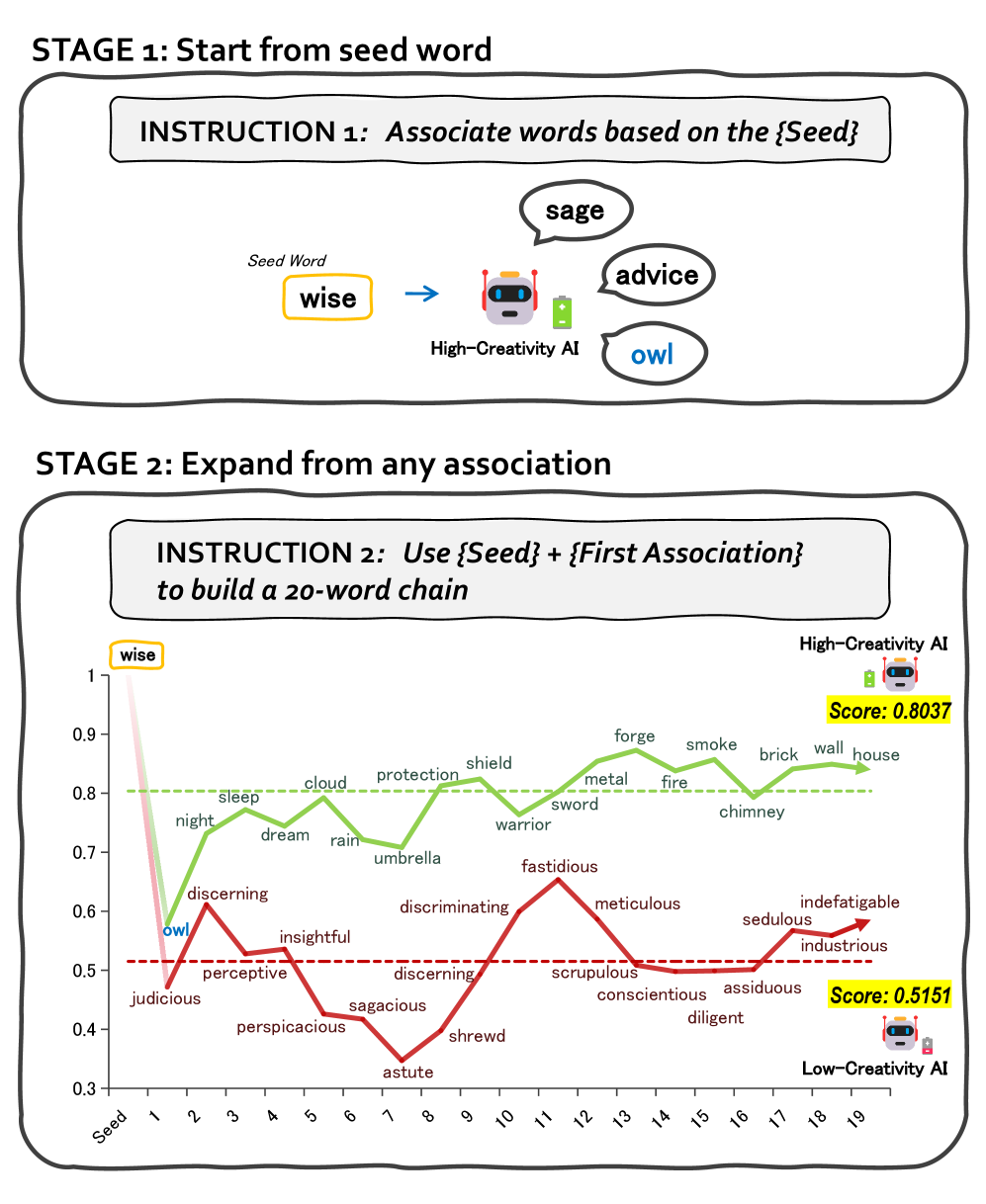
核心思路:论文的核心思路是借鉴人类创造力评估的方式,设计一种基于联想的评估方法。具体来说,要求LLM围绕给定的提示词生成一系列联想词链,通过分析这些联想词链的质量来评估LLM的创造力。这种方法的核心在于,联想过程能够反映LLM的知识广度和联想能力,并且可以有效降低数据污染的风险,因为LLM不太可能在训练过程中见过完全相同的联想链。
技术框架:PACE (Parallel Association Chains to Evaluate creativity) 的整体流程如下: 1. 提示词选择:选择一组具有代表性的提示词,作为联想的起点。 2. 联想链生成:要求LLM围绕每个提示词,并行生成多条联想词链。每条链包含若干个联想词,每个词都与前一个词相关联。 3. 联想链评估:使用预定义的指标(例如,联想词的多样性、抽象程度等)来评估每条联想链的质量。 4. 创造力评分:将所有联想链的评估结果进行汇总,得到LLM的创造力评分。
关键创新:PACE的关键创新在于其评估方式的独特性和有效性。与传统的依赖于数据集或人工评估的方法不同,PACE通过分析LLM的联想能力来评估其创造力,从而有效降低了数据污染的风险,并实现了高效的自动化评估。此外,PACE还提供了一种可解释的评估结果,可以帮助研究人员深入了解LLM的创造力机制。
关键设计:论文中并没有详细描述具体的参数设置、损失函数或网络结构,因为PACE主要是一种评估方法,而不是一种新的模型架构。然而,在联想链生成过程中,可以控制以下关键设计: * 联想链的长度:决定了联想的深度。 * 联想词的数量:决定了联想的广度。 * 联想词的选择策略:例如,可以使用不同的采样方法来控制联想词的多样性。 * 评估指标的选择:不同的评估指标可以反映联想链的不同方面,例如,多样性、抽象程度、相关性等。
🖼️ 关键图片

📊 实验亮点
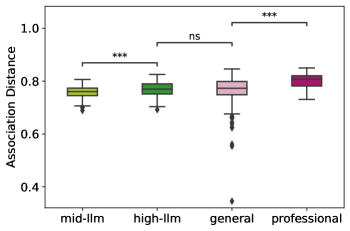
实验结果表明,PACE与Chatbot Arena创意写作排名具有高度相关性(Spearman's ρ= 0.739,p < 0.001),验证了其有效性。同时,研究发现高性能LLM的联想创造力可与普通人类媲美,但仍不及专业人士。语言分析揭示了LLM和人类在联想模式上的差异,为进一步提升LLM的创造力提供了方向。
🎯 应用场景
PACE可应用于LLM的创造力评估、模型选择和优化。在创意写作、内容生成、产品设计等领域,可利用PACE筛选出更具创造力的LLM,提升生成内容的质量和创新性。此外,PACE还可用于分析LLM的创造力机制,为未来的模型设计提供指导。
📄 摘要(原文)
The evaluation of LLMs' creativity represents a crucial research domain, though challenges such as data contamination and costly human assessments often impede progress. Drawing inspiration from human creativity assessment, we propose PACE, asking LLMs to generate Parallel Association Chains to Evaluate their creativity. PACE minimizes the risk of data contamination and offers a straightforward, highly efficient evaluation, as evidenced by its strong correlation with Chatbot Arena Creative Writing rankings (Spearman's $ρ= 0.739$, $p < 0.001$) across various proprietary and open-source models. A comparative analysis of associative creativity between LLMs and humans reveals that while high-performing LLMs achieve scores comparable to average human performance, professional humans consistently outperform LLMs. Furthermore, linguistic analysis reveals that both humans and LLMs exhibit a trend of decreasing concreteness in their associations, and humans demonstrating a greater diversity of associative patterns.