Hierarchical Alignment: Surgical Fine-Tuning via Functional Layer Specialization in Large Language Models
作者: Yukun Zhang, Qi Dong
分类: cs.CL, cs.AI
发布日期: 2025-10-14
💡 一句话要点
提出层级对齐方法,通过功能层特化微调大型语言模型,提升性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 对齐技术 层级对齐 直接偏好优化 功能层特化
📋 核心要点
- 现有LLM对齐方法忽略了Transformer内部不同层的功能专业化,导致优化效率低下。
- 提出层级对齐方法,针对性地对模型的局部(语法)、中间(逻辑)和全局(事实性)层进行DPO优化。
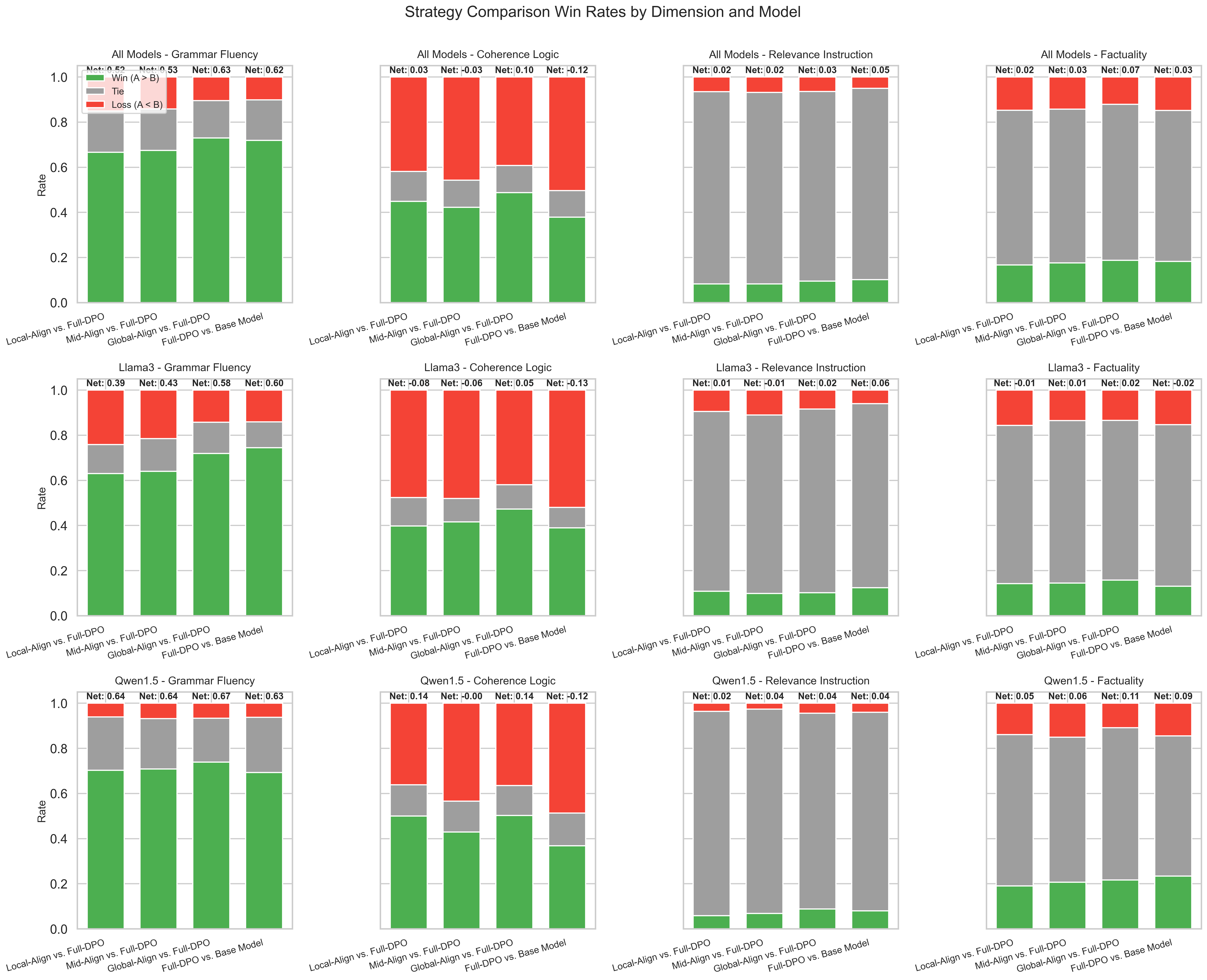
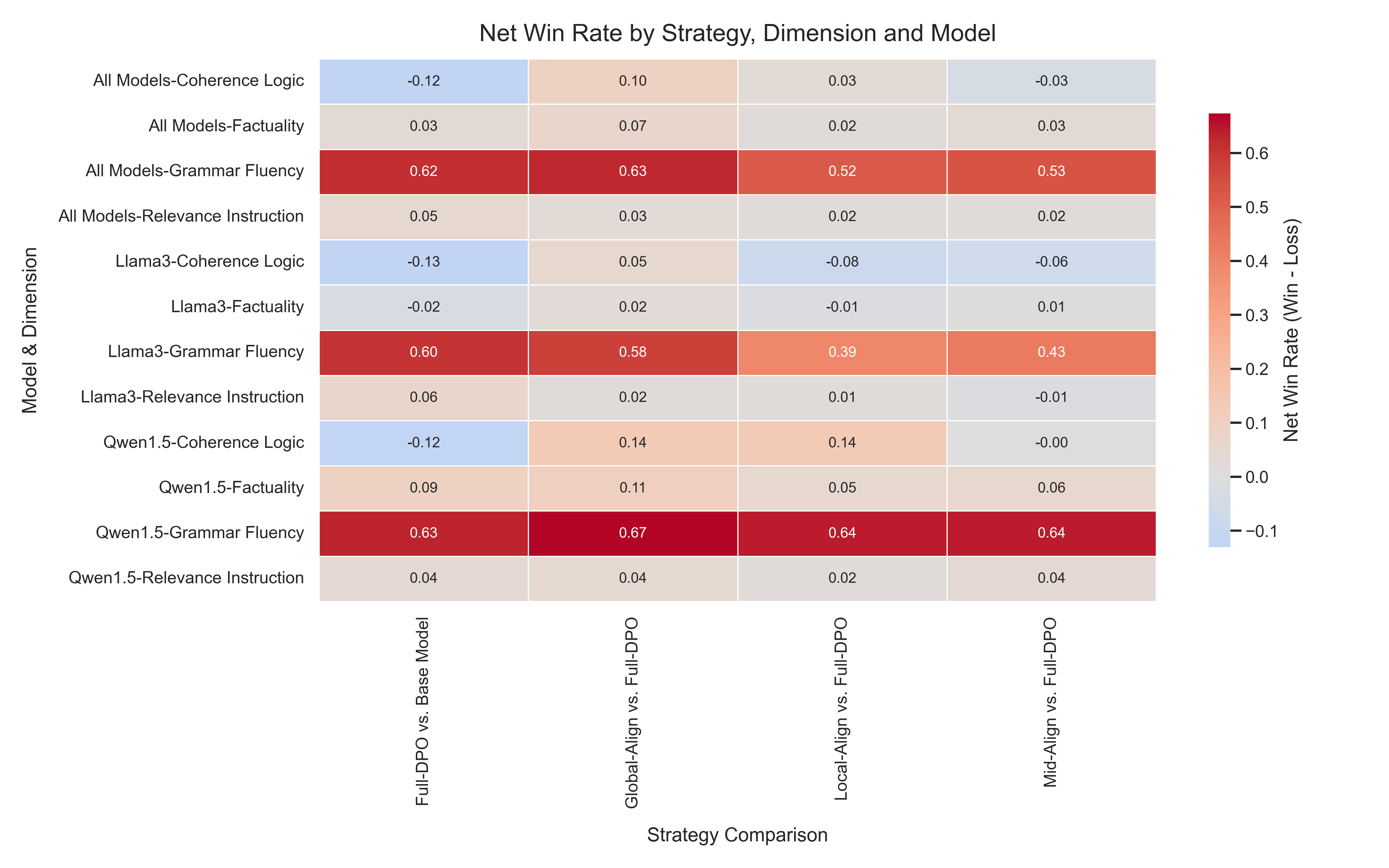
- 实验表明,该方法能显著提升LLM的语法流畅性、事实一致性和逻辑连贯性,并避免“对齐税”。
📝 摘要(中文)
现有的大型语言模型(LLM)对齐技术,如直接偏好优化(DPO),通常将模型视为一个整体,对所有层施加统一的优化压力。这种方法忽略了Transformer架构内的功能专业化,其中不同的层处理不同的任务,从语法到抽象推理。本文提出了层级对齐,一种新颖的方法,将有针对性的DPO应用于模型层的不同功能块:局部(语法)、中间(逻辑)和全局(事实性)。通过在Llama-3.1-8B和Qwen1.5-7B等先进模型上使用LoRA进行精细微调的一系列受控实验,我们的结果(由强大的LLM-as-Judge评估)表明了显著且可预测的改进。具体而言,对齐局部层(Local-Align)增强了语法流畅性。更重要的是,对齐全局层(Global-Align)不仅提高了假设的事实一致性,而且被证明是提高逻辑连贯性的最有效策略,优于所有基线。关键的是,所有层级策略都成功避免了标准DPO中观察到的“对齐税”,即流畅性提升以逻辑推理能力下降为代价。这些发现为模型对齐建立了一条更具资源效率、可控性和可解释性的路径,突出了从整体优化转向结构感知精细微调以构建更先进和可靠的LLM的巨大潜力。
🔬 方法详解
问题定义:现有的大型语言模型对齐方法,例如DPO,通常将整个模型视为一个整体进行优化,忽略了Transformer架构中不同层的功能差异。这种一刀切的方法可能导致优化效率低下,并且无法充分利用模型各层的功能特性。此外,标准的DPO方法还存在“对齐税”的问题,即提升某些方面的性能可能会牺牲其他方面的性能,例如提升流畅性可能会降低逻辑推理能力。
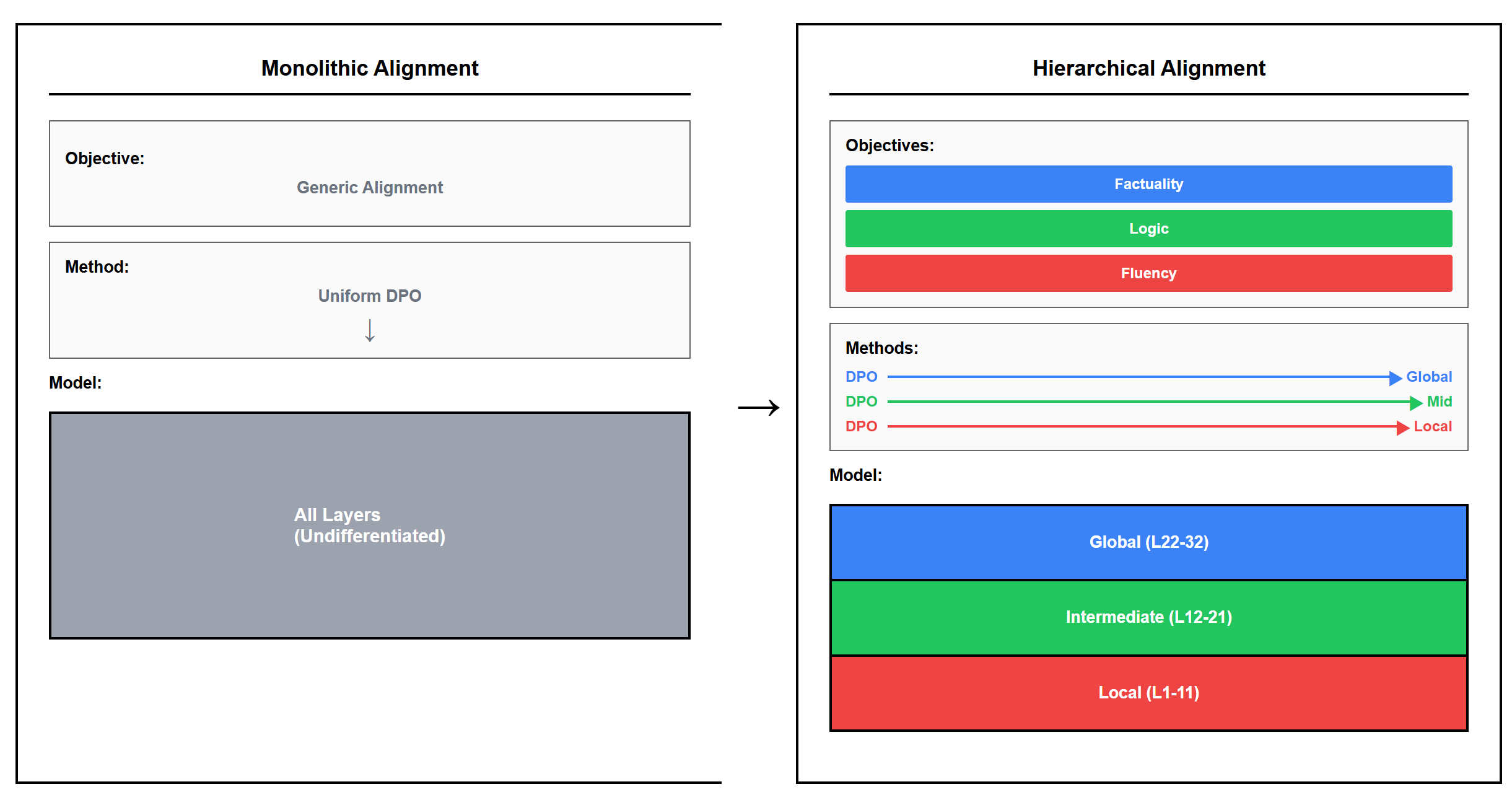
核心思路:本文的核心思路是根据Transformer架构中不同层的功能专业化,将模型分为局部(语法)、中间(逻辑)和全局(事实性)三个功能块,并针对每个功能块采用不同的DPO优化策略。这种分层对齐的方法可以更有效地利用模型各层的功能特性,从而提升模型的整体性能,并避免“对齐税”的问题。
技术框架:该方法的技术框架主要包括以下几个步骤:1)将Transformer模型划分为局部、中间和全局三个功能块。2)针对每个功能块,使用DPO算法进行优化,其中局部层主要关注语法流畅性,中间层主要关注逻辑连贯性,全局层主要关注事实一致性。3)使用LoRA(Low-Rank Adaptation)技术进行参数高效的微调,以减少计算成本。4)使用LLM-as-Judge进行评估,以客观地评估模型的性能。
关键创新:该方法最重要的技术创新点在于提出了层级对齐的概念,并将其应用于LLM的微调过程中。与传统的整体优化方法相比,层级对齐能够更有效地利用模型各层的功能特性,从而提升模型的整体性能。此外,该方法还成功避免了“对齐税”的问题,即在提升某些方面的性能的同时,不会牺牲其他方面的性能。
关键设计:在具体实现上,论文的关键设计包括:1)如何将Transformer模型划分为局部、中间和全局三个功能块。这通常基于对Transformer架构的理解和经验,例如,浅层可能负责语法分析,深层可能负责事实推理。2)如何针对每个功能块设计合适的DPO优化策略。这需要根据每个功能块的特点,选择合适的奖励函数和偏好数据。3)如何使用LoRA技术进行参数高效的微调。这需要选择合适的LoRA参数和优化器。
🖼️ 关键图片
📊 实验亮点
实验结果表明,层级对齐方法能够显著提升LLM的性能。具体而言,对齐局部层(Local-Align)增强了语法流畅性,对齐全局层(Global-Align)不仅提高了事实一致性,而且被证明是提高逻辑连贯性的最有效策略,优于所有基线。更重要的是,所有层级策略都成功避免了标准DPO中观察到的“对齐税”。
🎯 应用场景
该研究成果可广泛应用于各种需要高质量LLM的场景,例如智能客服、内容生成、机器翻译等。通过层级对齐,可以构建更可靠、更可控的LLM,提升用户体验。未来,该方法还可以扩展到其他类型的神经网络,并与其他对齐技术相结合,进一步提升模型性能。
📄 摘要(原文)
Existing alignment techniques for Large Language Models (LLMs), such as Direct Preference Optimization (DPO), typically treat the model as a monolithic entity, applying uniform optimization pressure across all layers. This approach overlooks the functional specialization within the Transformer architecture, where different layers are known to handle distinct tasks from syntax to abstract reasoning. In this paper, we challenge this one-size-fits-all paradigm by introducing Hierarchical Alignment, a novel method that applies targeted DPO to distinct functional blocks of a model's layers: local (syntax), intermediate (logic), and global (factuality). Through a series of controlled experiments on state-of-the-art models like Llama-3.1-8B and Qwen1.5-7B using LoRA for surgical fine-tuning, our results, evaluated by a powerful LLM-as-Judge, demonstrate significant and predictable improvements. Specifically, aligning the local layers (Local-Align) enhances grammatical fluency. More importantly, aligning the global layers (Global-Align) not only improves factual consistency as hypothesized but also proves to be the most effective strategy for enhancing logical coherence, outperforming all baselines. Critically, all hierarchical strategies successfully avoid the "alignment tax" observed in standard DPO, where gains in fluency come at the cost of degraded logical reasoning. These findings establish a more resource-efficient, controllable, and interpretable path for model alignment, highlighting the immense potential of shifting from monolithic optimization to structure-aware surgical fine-tuning to build more advanced and reliable LLMs.