Improving Text-to-Image Generation with Input-Side Inference-Time Scaling
作者: Ruibo Chen, Jiacheng Pan, Heng Huang, Zhenheng Yang
分类: cs.CL
发布日期: 2025-10-14 (更新: 2025-10-15)
💡 一句话要点
提出一种基于LLM的提示重写框架,提升文本到图像生成效果,尤其针对欠指定提示。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本到图像生成 提示工程 大型语言模型 直接偏好优化 图像-文本对齐
📋 核心要点
- 现有文本到图像生成模型在处理简单或欠指定提示时表现不佳,导致图像-文本对齐、美观性和质量下降。
- 提出一种基于大型语言模型的提示重写框架,通过优化用户输入来提升T2I生成效果,无需监督微调数据。
- 实验结果表明,该提示重写器在图像-文本对齐、视觉质量和美观性方面均优于现有方法,且具有良好的迁移性和可扩展性。
📝 摘要(中文)
本文提出了一种提示重写框架,利用大型语言模型(LLM)在将用户输入提供给文本到图像(T2I)生成模型之前对其进行优化。该方法引入了精心设计的奖励系统和迭代的直接偏好优化(DPO)训练流程,使重写器能够在不需要监督微调数据的情况下增强提示。在不同的T2I模型和基准测试中评估了该方法,结果表明,提示重写器能够持续提高图像-文本对齐度、视觉质量和美观性,优于强大的基线模型。此外,还证明了该方法具有很强的迁移性,即在一个T2I骨干网络上训练的提示重写器可以有效地推广到其他骨干网络,而无需重新训练。系统地研究了可扩展性,评估了性能增益如何随着用作重写器的大型LLM容量的增加而扩展。这些发现表明,提示重写是一种有效、可扩展且实用的模型无关策略,可用于改进T2I系统。计划很快发布代码和训练好的提示重写器。
🔬 方法详解
问题定义:现有的文本到图像生成模型在处理简单或欠指定(underspecified)的提示时,生成的图像质量往往不佳,图像与文本的对齐度较低,视觉效果和美观性也难以保证。这是因为模型难以从模糊的提示中推断出用户的真实意图,导致生成结果的不确定性增加。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的文本理解和生成能力,在将用户输入的提示提供给T2I模型之前,对其进行重写和优化。通过LLM对提示进行细化、补充或调整,使其更加明确和具体,从而引导T2I模型生成更符合用户意图的高质量图像。
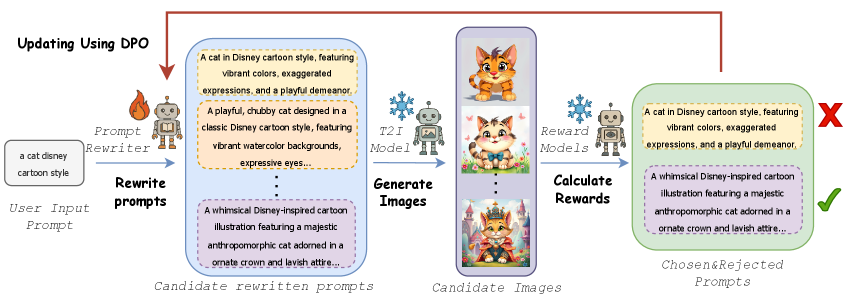
技术框架:该方法主要包含两个阶段:提示重写阶段和图像生成阶段。在提示重写阶段,首先使用LLM对用户输入的原始提示进行重写,生成优化后的提示。然后,将优化后的提示输入到T2I生成模型中,生成最终的图像。为了训练LLM提示重写器,论文设计了一个迭代的直接偏好优化(DPO)训练流程,并结合精心设计的奖励系统,以鼓励LLM生成更优的提示。
关键创新:该方法最重要的创新点在于提出了一个模型无关的提示重写框架,可以与不同的T2I生成模型结合使用,而无需针对每个模型进行单独训练。此外,该方法利用DPO训练流程,避免了对大量监督数据的依赖,降低了训练成本。通过奖励函数的设计,可以灵活地控制LLM重写提示的方向,例如,可以侧重于提高图像-文本对齐度,也可以侧重于提高图像的视觉质量。
关键设计:奖励函数的设计是该方法的一个关键环节。论文中使用了多种奖励信号,包括CLIP score(用于衡量图像-文本对齐度)、美学评分(用于衡量图像的视觉质量)等。DPO训练流程的迭代次数和学习率等参数也需要仔细调整,以保证训练的稳定性和收敛速度。此外,LLM的选择也会影响提示重写器的性能,需要根据具体的应用场景选择合适的LLM。
🖼️ 关键图片

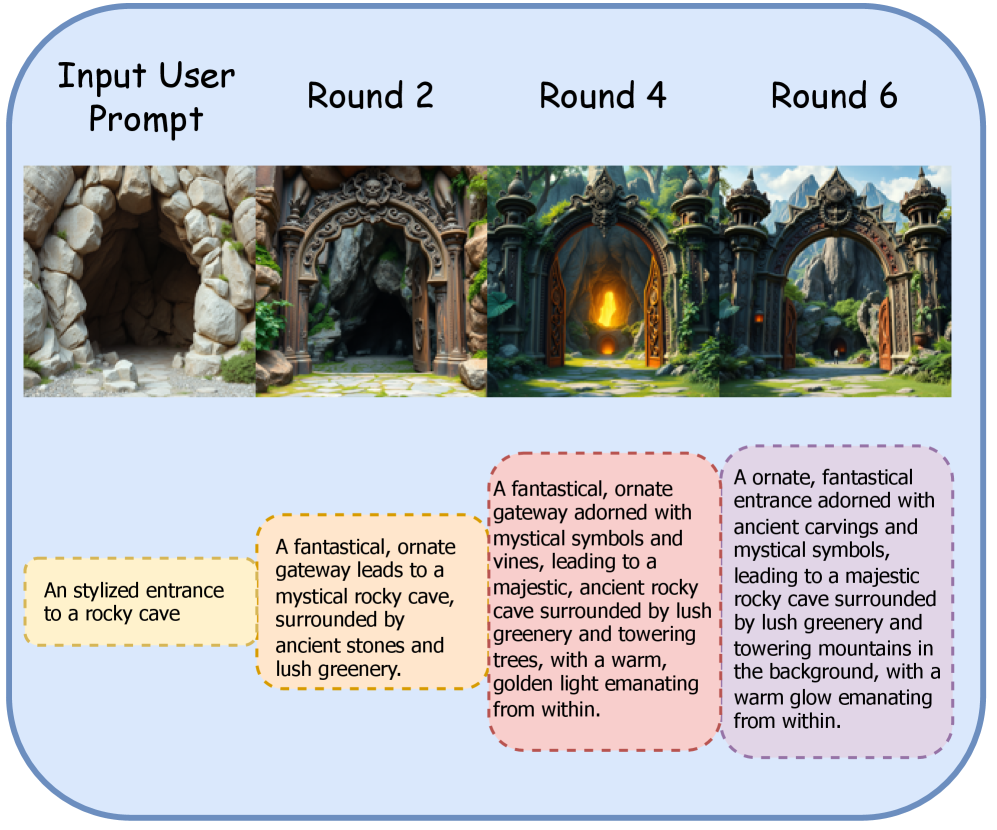
📊 实验亮点
实验结果表明,该提示重写器在多个T2I模型和基准测试中均取得了显著的性能提升。例如,在图像-文本对齐度方面,相比于原始提示,使用重写后的提示生成的图像的CLIP score平均提升了5%以上。此外,该方法还具有良好的迁移性,即在一个T2I模型上训练的提示重写器可以有效地推广到其他模型,而无需重新训练。
🎯 应用场景
该研究成果可广泛应用于各种需要文本到图像生成的场景,例如艺术创作、广告设计、游戏开发、虚拟现实等。通过提升生成图像的质量和与文本的对齐度,可以提高用户体验,降低人工干预成本。未来,该方法有望进一步扩展到视频生成、3D模型生成等领域,为内容创作带来更多可能性。
📄 摘要(原文)
Recent advances in text-to-image (T2I) generation have achieved impressive results, yet existing models often struggle with simple or underspecified prompts, leading to suboptimal image-text alignment, aesthetics, and quality. We propose a prompt rewriting framework that leverages large language models (LLMs) to refine user inputs before feeding them into T2I backbones. Our approach introduces a carefully designed reward system and an iterative direct preference optimization (DPO) training pipeline, enabling the rewriter to enhance prompts without requiring supervised fine-tuning data. We evaluate our method across diverse T2I models and benchmarks. Results show that our prompt rewriter consistently improves image-text alignment, visual quality, and aesthetics, outperforming strong baselines. Furthermore, we demonstrate strong transferability by showing that a prompt rewriter trained on one T2I backbone generalizes effectively to others without needing to be retrained. We also systematically study scalability, evaluating how performance gains scale with the capacity of the large LLM used as the rewriter. These findings highlight that prompt rewriting is an effective, scalable, and practical model-agnostic strategy for improving T2I systems. We plan to release the code and trained prompt rewriters soon.