Uncertainty Quantification for Hallucination Detection in Large Language Models: Foundations, Methodology, and Future Directions
作者: Sungmin Kang, Yavuz Faruk Bakman, Duygu Nur Yaldiz, Baturalp Buyukates, Salman Avestimehr
分类: cs.CL
发布日期: 2025-10-14
备注: 24 pages, 3 figures, magazine
💡 一句话要点
综述性研究:面向大语言模型幻觉检测的不确定性量化方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 不确定性量化 自然语言处理 可靠性 可信度 综述 LLM
📋 核心要点
- 现有大语言模型容易产生幻觉,输出看似合理但事实错误的文本,影响了其在实际应用中的可靠性和可信度。
- 本文探讨了不确定性量化(UQ)在检测和缓解大语言模型幻觉问题中的作用,并对现有方法进行了系统分类。
- 论文对代表性方法进行了实证分析,总结了当前研究的局限性,并提出了未来研究方向,为该领域提供了清晰的概览。
📝 摘要(中文)
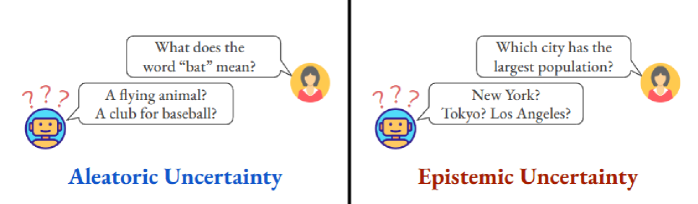
大型语言模型(LLM)的快速发展极大地改变了自然语言处理领域,在问答、机器翻译和文本摘要等领域取得了突破。然而,LLM在实际应用中的部署引发了对其可靠性和可信度的担忧,因为LLM仍然容易产生看似合理但实际上不正确的输出,即幻觉。不确定性量化(UQ)已成为解决此问题的核心研究方向,为评估模型生成的可信度提供了原则性方法。本文首先介绍UQ的基础知识,从其正式定义到认知不确定性和偶然不确定性之间的传统区别,然后重点介绍这些概念如何适应LLM的背景。在此基础上,我们研究了UQ在幻觉检测中的作用,其中量化不确定性提供了一种识别不可靠生成并提高可靠性的机制。我们系统地对现有方法进行了多维度分类,并给出了几种代表性方法的实证结果。最后,我们讨论了当前的局限性,并概述了有希望的未来研究方向,从而更清楚地了解了用于幻觉检测的LLM UQ的当前状况。
🔬 方法详解
问题定义:大语言模型(LLM)的幻觉问题,即生成看似合理但与事实不符的内容,严重阻碍了LLM在实际场景中的应用。现有方法缺乏有效的手段来评估生成内容的可靠性,难以区分真实信息和模型虚构的内容。因此,如何准确检测和量化LLM生成内容的不确定性,成为亟待解决的关键问题。
核心思路:本文的核心思路是利用不确定性量化(Uncertainty Quantification, UQ)技术来评估LLM生成内容的可靠性。通过量化模型输出的不确定性,可以识别出可能存在幻觉的内容,从而提高LLM的整体可信度。这种方法基于一个假设:模型对于不确定的内容,其输出结果也应该表现出相应的不确定性。
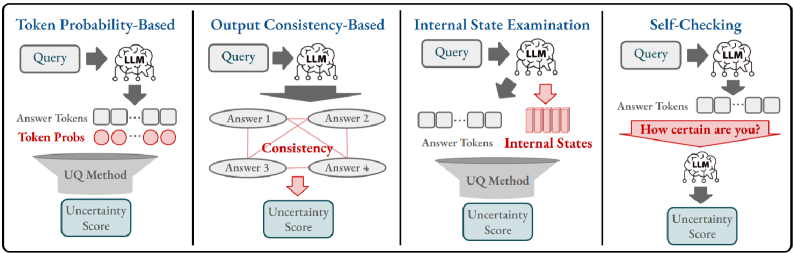
技术框架:本文主要是一个综述性质的工作,其技术框架体现在对现有方法的系统分类和分析上。主要包括:1) 介绍不确定性量化的基本概念,包括认知不确定性和偶然不确定性;2) 探讨UQ在幻觉检测中的应用,分析如何利用不确定性指标来识别不可靠的生成内容;3) 对现有的UQ方法进行多维度分类,例如基于模型的方法、基于数据的方法等;4) 对代表性方法进行实证分析,评估其在幻觉检测任务中的性能;5) 总结当前研究的局限性,并展望未来的研究方向。
关键创新:本文的创新之处在于对LLM幻觉检测中的不确定性量化方法进行了系统的梳理和分类。它不是提出一种新的算法或模型,而是对现有方法进行归纳总结,并从不确定性量化的角度提供了一个统一的视角。这有助于研究人员更好地理解各种方法的优缺点,并为未来的研究提供指导。
关键设计:本文的关键设计在于其分类框架,它将现有的UQ方法按照不同的维度进行划分,例如:1) 基于模型的方法,侧重于修改模型结构或训练方式来提高不确定性估计的准确性;2) 基于数据的方法,侧重于利用外部知识或数据增强技术来提高模型对事实的认知能力;3) 基于解码的方法,侧重于在解码过程中引入不确定性感知机制。此外,本文还对各种方法的优缺点进行了详细的分析,并给出了实验结果的对比。
🖼️ 关键图片

📊 实验亮点
本文对现有的大语言模型幻觉检测方法进行了全面的综述和分类,并对代表性方法进行了实证分析。虽然没有提供具体的性能数据,但通过对各种方法的优缺点进行对比,为研究人员选择合适的方法提供了参考。此外,本文还指出了当前研究的局限性,并提出了未来研究方向,为该领域的发展提供了指导。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的大语言模型应用场景,例如:医疗诊断辅助、金融风险评估、法律咨询等。通过量化模型输出的不确定性,可以帮助用户更好地判断信息的真伪,避免因模型幻觉而导致的决策失误。此外,该研究还可以促进大语言模型在开放域问答、知识图谱构建等领域的应用。
📄 摘要(原文)
The rapid advancement of large language models (LLMs) has transformed the landscape of natural language processing, enabling breakthroughs across a wide range of areas including question answering, machine translation, and text summarization. Yet, their deployment in real-world applications has raised concerns over reliability and trustworthiness, as LLMs remain prone to hallucinations that produce plausible but factually incorrect outputs. Uncertainty quantification (UQ) has emerged as a central research direction to address this issue, offering principled measures for assessing the trustworthiness of model generations. We begin by introducing the foundations of UQ, from its formal definition to the traditional distinction between epistemic and aleatoric uncertainty, and then highlight how these concepts have been adapted to the context of LLMs. Building on this, we examine the role of UQ in hallucination detection, where quantifying uncertainty provides a mechanism for identifying unreliable generations and improving reliability. We systematically categorize a wide spectrum of existing methods along multiple dimensions and present empirical results for several representative approaches. Finally, we discuss current limitations and outline promising future research directions, providing a clearer picture of the current landscape of LLM UQ for hallucination detection.