Information Extraction from Conversation Transcripts: Neuro-Symbolic vs. LLM
作者: Alice Saebom Kwak, Maria Alexeeva, Gus Hahn-Powell, Keith Alcock, Kevin McLaughlin, Doug McCorkle, Gabe McNunn, Mihai Surdeanu
分类: cs.CL
发布日期: 2025-10-14
备注: 15 pages, 2 figures
💡 一句话要点
对比神经符号与LLM方法,评估农业领域对话信息抽取的性能与成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 信息抽取 神经符号 大型语言模型 对话系统 农业领域
📋 核心要点
- 现有信息抽取方法过度依赖大型语言模型,忽略了传统符号或统计IE系统的经验积累,存在一定局限性。
- 本文对比神经符号和LLM两种方法在农业领域对话信息抽取任务上的表现,分析各自的优缺点。
- 实验结果表明,LLM方法在F1值上优于神经符号方法,但神经符号方法在运行速度和可控性上更具优势。
📝 摘要(中文)
本文对比了神经符号(NS)和基于大型语言模型(LLM)的信息抽取(IE)系统在农业领域的性能。评估在猪肉、奶制品和农作物子领域的九次访谈中进行。结果表明,基于LLM的系统优于NS系统(总F1值:69.4 vs. 52.7;核心F1值:63.0 vs. 47.2)。然而,两种系统各有优缺点:NS方法运行速度更快,可控性更强,在无上下文任务中准确率高,但缺乏泛化能力,难以处理上下文细微差别,且开发和维护需要大量资源。基于LLM的系统性能更高,部署更快,维护更容易,但运行速度较慢,可控性有限,存在模型依赖和幻觉风险。研究结果突出了在实际应用中部署NLP系统的“隐性成本”,强调需要在性能、效率和控制之间取得平衡。
🔬 方法详解
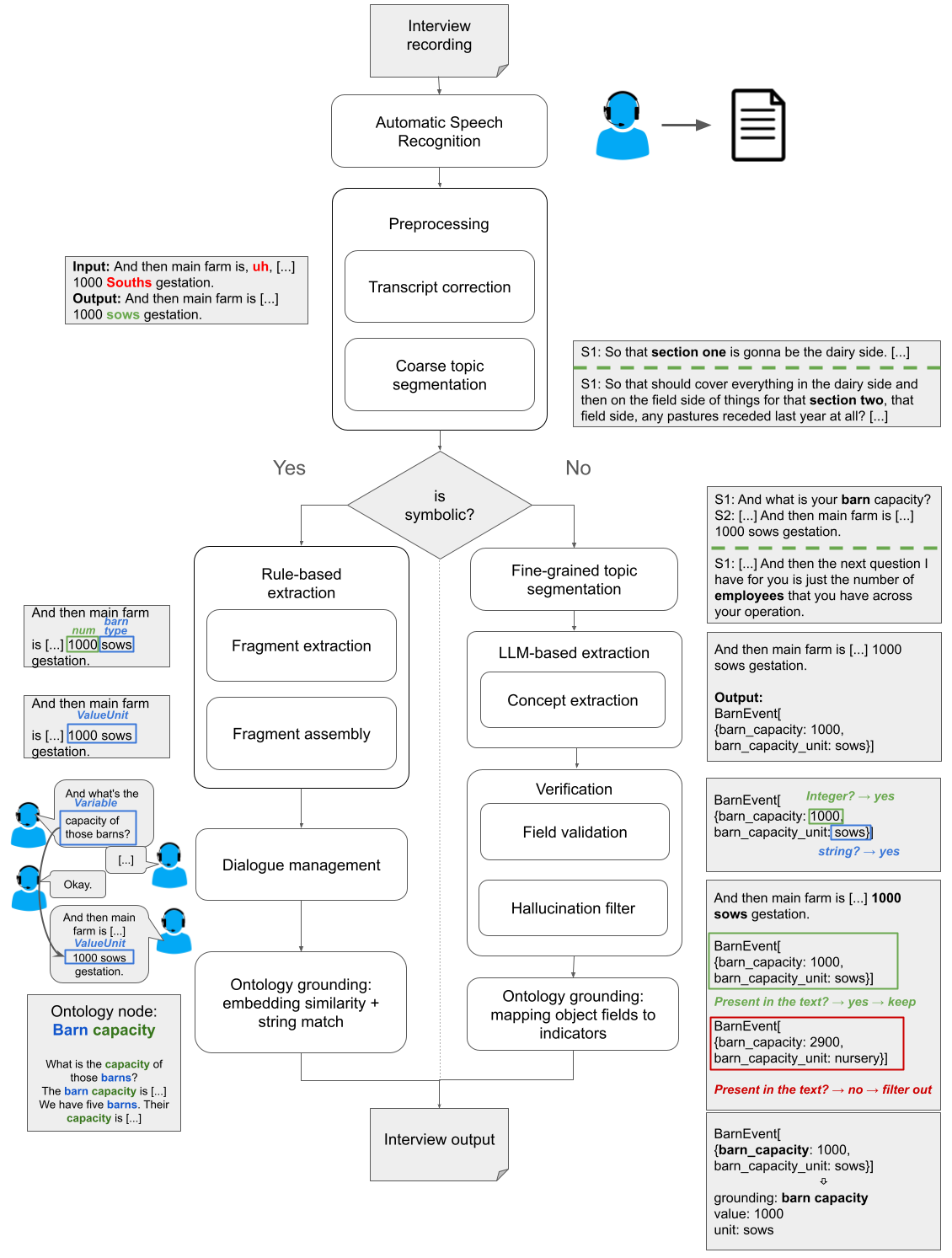
问题定义:论文旨在解决农业领域对话文本的信息抽取问题。现有方法,特别是过度依赖LLM的方法,虽然在性能上有所提升,但存在运行速度慢、可控性差、模型依赖以及幻觉风险等问题。同时,传统的神经符号方法虽然可控性强,但泛化能力弱,开发和维护成本高昂。
核心思路:论文的核心思路是通过对比神经符号方法和LLM方法在同一任务上的表现,揭示两种方法的优缺点,从而为实际应用中选择合适的信息抽取系统提供指导。强调需要在性能、效率和控制之间进行权衡。
技术框架:论文采用对比实验的框架,分别构建了神经符号和基于LLM的信息抽取系统,并在农业领域的对话数据集上进行评估。数据集包含猪肉、奶制品和农作物三个子领域。评估指标包括总F1值和核心F1值,其中核心F1值侧重于评估关键信息的抽取效果。
关键创新:论文的创新点在于对神经符号方法和LLM方法进行了全面的对比分析,不仅关注性能指标,还考虑了运行速度、可控性、开发成本等实际应用中需要考虑的因素。揭示了LLM方法在性能提升的同时,也带来了“隐性成本”。
关键设计:论文中神经符号系统的具体设计细节未知,但强调了其在无上下文任务中的高准确率。LLM系统的具体模型选择和训练策略未知,但提到了其存在的幻觉风险。实验中,对两种方法在不同子领域的数据集上进行了评估,并比较了它们的F1值。
🖼️ 关键图片

📊 实验亮点
实验结果显示,基于LLM的系统在总F1值(69.4)和核心F1值(63.0)上均优于神经符号系统(总F1值:52.7;核心F1值:47.2)。然而,神经符号系统在运行速度和可控性方面更具优势。该研究揭示了LLM方法在性能提升的同时,也带来了运行速度慢、可控性差等“隐性成本”。
🎯 应用场景
该研究成果可应用于农业知识图谱构建、智能农业咨询、农产品溯源等领域。通过选择合适的信息抽取方法,可以更高效地从农业对话数据中提取关键信息,为农业生产和管理提供决策支持,并降低NLP系统在实际应用中的部署成本。
📄 摘要(原文)
The current trend in information extraction (IE) is to rely extensively on large language models, effectively discarding decades of experience in building symbolic or statistical IE systems. This paper compares a neuro-symbolic (NS) and an LLM-based IE system in the agricultural domain, evaluating them on nine interviews across pork, dairy, and crop subdomains. The LLM-based system outperforms the NS one (F1 total: 69.4 vs. 52.7; core: 63.0 vs. 47.2), where total includes all extracted information and core focuses on essential details. However, each system has trade-offs: the NS approach offers faster runtime, greater control, and high accuracy in context-free tasks but lacks generalizability, struggles with contextual nuances, and requires significant resources to develop and maintain. The LLM-based system achieves higher performance, faster deployment, and easier maintenance but has slower runtime, limited control, model dependency and hallucination risks. Our findings highlight the "hidden cost" of deploying NLP systems in real-world applications, emphasizing the need to balance performance, efficiency, and control.