TextBandit: Evaluating Probabilistic Reasoning in LLMs Through Language-Only Decision Tasks
作者: Jimin Lim, Arjun Damerla, Arthur Jiang, Nam Le
分类: cs.CL
发布日期: 2025-10-13
备注: COLM 2025 @ ORIGen Workshop
💡 一句话要点
TextBandit:提出基于纯文本反馈的多臂老虎机基准,评估LLM的概率推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多臂老虎机 概率推理 文本反馈 决策任务
📋 核心要点
- 现有方法难以在自然语言环境下评估LLM的序列决策和概率推理能力,缺乏有效的基准测试。
- 提出TextBandit基准,利用纯文本反馈的多臂老虎机环境,考察LLM在无数值提示下的决策能力。
- 实验表明,Qwen3-4B模型在TextBandit基准上表现出色,最佳臂选择率达到89.2%,超越传统算法。
📝 摘要(中文)
大型语言模型(LLM)在执行推理任务方面表现出越来越强的能力,但它们仅使用自然语言在不确定性下进行序列决策的能力仍未得到充分探索。我们引入了一个新的基准,其中LLM与多臂老虎机环境交互,仅使用文本反馈“你获得了一个token”,而无需访问数值线索或显式概率,从而使模型能够仅从语言线索中推断潜在的奖励结构并进行相应调整。我们评估了四个开源LLM的性能,并将它们的性能与标准决策算法(如Thompson Sampling、Epsilon Greedy、Upper Confidence Bound (UCB) 和随机选择)进行比较。虽然大多数LLM的表现不如基线,但Qwen3-4B实现了89.2%的最佳臂选择率,显著优于更大的LLM和传统方法。我们的研究结果表明,概率推理能够仅从语言中产生,我们将此基准作为评估自然、非数值环境中的决策能力的一步。
🔬 方法详解
问题定义:论文旨在评估大型语言模型(LLM)在仅使用自然语言反馈的情况下,进行序列决策和概率推理的能力。现有方法通常依赖于数值线索或显式概率,无法充分测试LLM在更自然、非数值环境中的决策能力。因此,需要一个能够模拟真实世界决策场景,并仅通过文本反馈来评估LLM的基准。
核心思路:论文的核心思路是创建一个基于文本的多臂老虎机环境,其中LLM通过与环境交互并接收文本反馈(例如“你获得了一个token”)来学习。LLM需要根据这些文本线索推断每个臂的潜在奖励结构,并做出相应的决策。这种设计迫使LLM仅依赖于语言理解和推理能力,而不能依赖于数值计算。
技术框架:TextBandit基准包含以下主要组成部分:1) 多臂老虎机环境:每个臂对应一个文本提示,LLM选择一个臂后,环境返回一个文本反馈。2) LLM:作为决策者,根据历史反馈选择下一个要拉动的臂。3) 评估指标:主要评估指标是最佳臂选择率,即LLM选择奖励最高的臂的频率。实验中对比了多个开源LLM和传统决策算法。
关键创新:该论文的关键创新在于提出了一个完全基于文本的多臂老虎机基准,用于评估LLM的概率推理能力。与传统的多臂老虎机环境不同,TextBandit不提供数值奖励或概率信息,而是仅使用自然语言反馈。这使得该基准更接近真实世界的决策场景,并能够更有效地评估LLM的语言理解和推理能力。
关键设计:TextBandit的关键设计包括:1) 文本反馈的设计:反馈必须简洁明了,能够清晰地传达奖励信息,同时避免引入不必要的噪声。2) 臂的数量和奖励结构的设置:需要仔细选择臂的数量和奖励结构,以确保任务的难度适中,并能够有效地区分不同LLM的性能。3) 评估指标的选择:最佳臂选择率是一个简单而有效的指标,能够直接反映LLM的决策能力。
🖼️ 关键图片

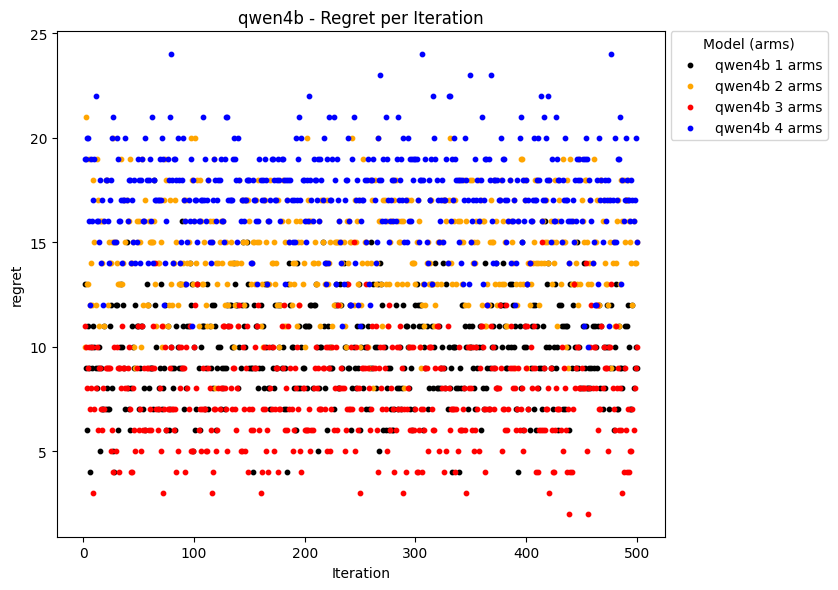
📊 实验亮点
实验结果表明,Qwen3-4B模型在TextBandit基准上表现最佳,最佳臂选择率达到89.2%,显著优于其他更大的LLM(如Llama2-7B)以及传统的决策算法(如Thompson Sampling、Epsilon Greedy和UCB)。这表明,即使在没有数值提示的情况下,LLM也能够通过语言理解和推理进行有效的决策。
🎯 应用场景
该研究成果可应用于开发更智能的对话系统、推荐系统和决策支持系统。通过评估和提升LLM在自然语言环境下的决策能力,可以构建更贴近人类直觉、更具适应性的AI应用。未来,该基准可扩展到更复杂的文本环境,例如模拟商业谈判或医疗诊断等场景。
📄 摘要(原文)
Large language models (LLMs) have shown to be increasingly capable of performing reasoning tasks, but their ability to make sequential decisions under uncertainty only using natural language remains underexplored. We introduce a novel benchmark in which LLMs interact with multi-armed bandit environments using purely textual feedback, "you earned a token", without access to numerical cues or explicit probabilities, resulting in the model to infer latent reward structures purely off linguistic cues and to adapt accordingly. We evaluated the performance of four open-source LLMs and compare their performance to standard decision-making algorithms such as Thompson Sampling, Epsilon Greedy, Upper Confidence Bound (UCB), and random choice. While most of the LLMs underperformed compared to the baselines, Qwen3-4B, achieved the best-arm selection rate of 89.2% , which significantly outperformed both the larger LLMs and traditional methods. Our findings suggest that probabilistic reasoning is able to emerge from language alone, and we present this benchmark as a step towards evaluating decision-making capabilities in naturalistic, non-numeric contexts.