FaStfact: Faster, Stronger Long-Form Factuality Evaluations in LLMs
作者: Yingjia Wan, Haochen Tan, Xiao Zhu, Xinyu Zhou, Zhiwei Li, Qingsong Lv, Changxuan Sun, Jiaqi Zeng, Yi Xu, Jianqiao Lu, Yinhong Liu, Zhijiang Guo
分类: cs.CL, cs.AI, cs.CE, cs.CY
发布日期: 2025-10-13 (更新: 2025-11-05)
备注: EMNLP 2025 (Findings)
🔗 代码/项目: GITHUB
💡 一句话要点
FaStfact:一种更快、更强的LLM长文本事实性评估框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本事实性评估 大型语言模型 声明提取 证据检索 置信度预验证
📋 核心要点
- 现有长文本事实性评估方法效率低,依赖复杂的pipeline,且声明提取不准确,证据不足。
- FaStfact通过chunk级声明提取和置信度预验证,减少时间和token消耗,提升评估可靠性。
- FaStfact-Bench基准测试表明,FaStfact在效率和效果上优于现有方法,与人类评估对齐度更高。
📝 摘要(中文)
由于效率瓶颈和可靠性问题,评估大型语言模型(LLM)生成长文本的事实性仍然具有挑战性。以往的工作试图通过将文本分解为声明、搜索证据和验证声明来实现这一点,但存在关键缺陷:(1)由于过于复杂的pipeline组件导致效率低下,(2)由于不准确的声明集和不足的证据导致效果不佳。为了解决这些限制,我们提出了 extbf{FaStfact},一种评估框架,在现有基线中实现了与人类评估的最高一致性以及时间/token效率。FaStfact首先采用与基于置信度的预验证集成的chunk级别声明提取,显著降低了时间和token成本,同时确保了可靠性。对于搜索和验证,它从爬取的网页中收集文档级别的证据,并在验证期间选择性地检索它。基于带注释的基准 extbf{FaStfact-Bench}的大量实验证明了FaStfact在高效且有效地评估长文本事实性方面的可靠性。代码、基准数据和注释界面工具可在https://github.com/Yingjia-Wan/FaStfact上找到。
🔬 方法详解
问题定义:论文旨在解决大型语言模型生成长文本的事实性评估问题。现有方法主要通过分解文本为声明、搜索证据并验证声明来实现,但存在效率和效果上的瓶颈。效率瓶颈源于pipeline的复杂性,效果瓶颈则源于不准确的声明集合和不足的证据。
核心思路:FaStfact的核心思路是在保证可靠性的前提下,尽可能提高评估效率。它通过chunk级别的声明提取和置信度预验证来减少需要处理的声明数量,并采用文档级别的证据搜索和选择性检索来提高证据的质量和相关性。
技术框架:FaStfact框架主要包含以下几个阶段:1) Chunk级别的声明提取:将长文本分割成更小的chunk,并从中提取声明。2) 置信度预验证:使用预训练模型对提取的声明进行初步验证,过滤掉明显错误的声明。3) 文档级别证据搜索:从网络上爬取的文档中搜索与剩余声明相关的证据。4) 选择性证据检索:根据声明和文档的相关性,选择性地检索证据。5) 声明验证:使用检索到的证据验证声明的真实性。
关键创新:FaStfact的关键创新在于:1) 结合置信度预验证的chunk级别声明提取,显著减少了需要处理的声明数量,提高了效率。2) 文档级别的证据搜索和选择性检索,提高了证据的质量和相关性。3) 整体框架设计简洁高效,避免了复杂pipeline带来的性能瓶颈。
关键设计:FaStfact使用预训练语言模型进行置信度预验证和声明验证。Chunk的大小、置信度阈值、证据检索策略等是关键的参数设置。损失函数的设计目标是最大化评估结果与人类评估的一致性。具体的网络结构和损失函数细节在论文中可能未详细描述,属于未知信息。
🖼️ 关键图片


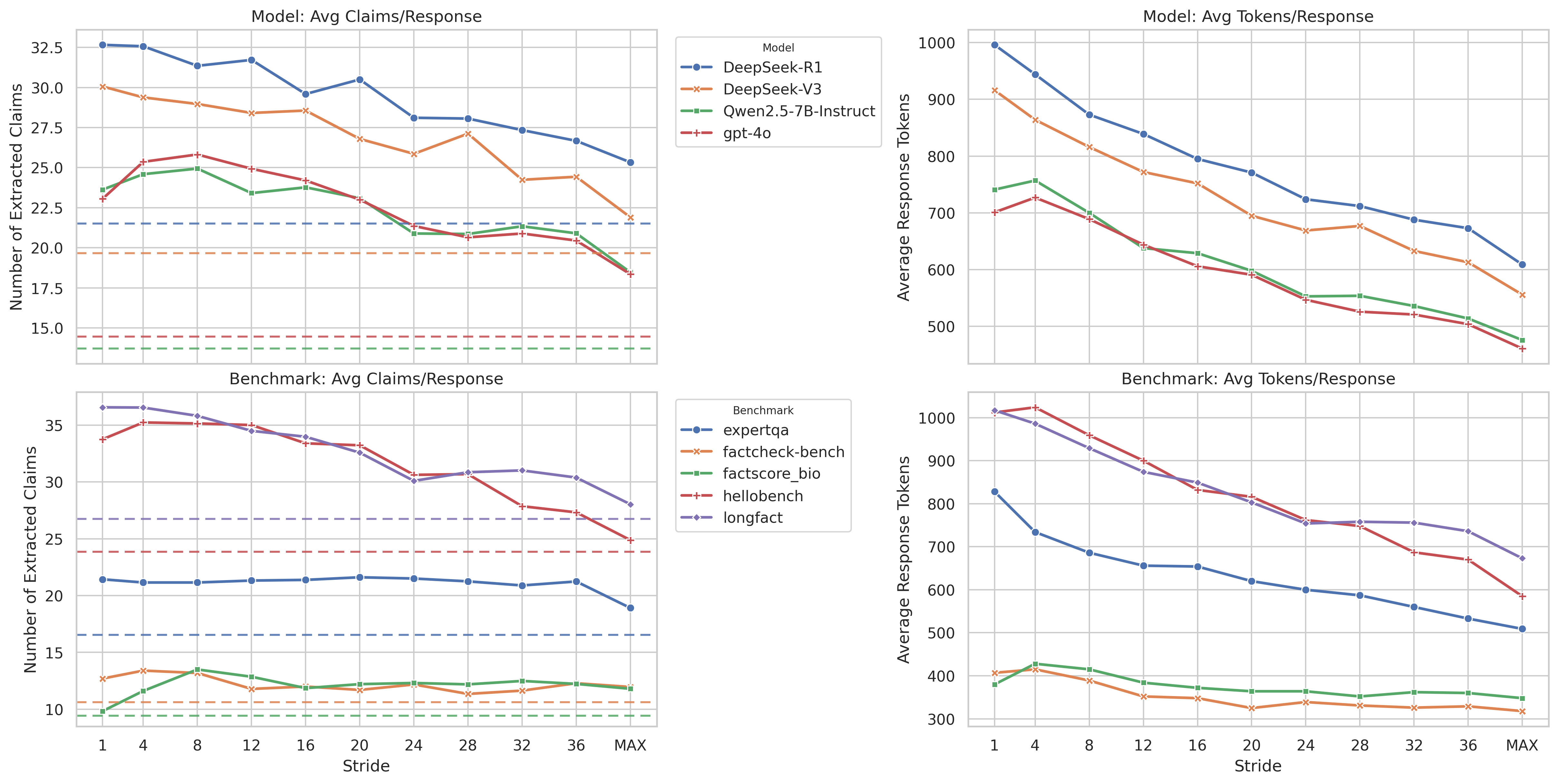
📊 实验亮点
FaStfact在FaStfact-Bench基准测试中表现出色,在效率和效果上均优于现有基线方法。具体性能数据和提升幅度在论文中进行了详细展示,表明FaStfact能够更准确、更快速地评估长文本的事实性,并与人类评估结果具有更高的相关性。实验结果验证了FaStfact框架的有效性和可靠性。
🎯 应用场景
FaStfact可用于评估各种大型语言模型生成长文本的事实性,例如新闻报道、科学论文、故事创作等。该研究有助于提高LLM生成内容的质量和可靠性,减少虚假信息的传播,并促进LLM在各个领域的应用。未来,该方法可以扩展到评估多模态生成内容的事实性。
📄 摘要(原文)
Evaluating the factuality of long-form generations from Large Language Models (LLMs) remains challenging due to efficiency bottlenecks and reliability concerns. Prior efforts attempt this by decomposing text into claims, searching for evidence, and verifying claims, but suffer from critical drawbacks: (1) inefficiency due to overcomplicated pipeline components, and (2) ineffectiveness stemming from inaccurate claim sets and insufficient evidence. To address these limitations, we propose \textbf{FaStfact}, an evaluation framework that achieves the highest alignment with human evaluation and time/token efficiency among existing baselines. FaStfact first employs chunk-level claim extraction integrated with confidence-based pre-verification, significantly reducing the time and token cost while ensuring reliability. For searching and verification, it collects document-level evidence from crawled web-pages and selectively retrieves it during verification. Extensive experiments based on an annotated benchmark \textbf{FaStfact-Bench} demonstrate the reliability of FaStfact in both efficiently and effectively evaluating long-form factuality. Code, benchmark data, and annotation interface tool are available at https://github.com/Yingjia-Wan/FaStfact.