UALM: Unified Audio Language Model for Understanding, Generation and Reasoning
作者: Jinchuan Tian, Sang-gil Lee, Zhifeng Kong, Sreyan Ghosh, Arushi Goel, Chao-Han Huck Yang, Wenliang Dai, Zihan Liu, Hanrong Ye, Shinji Watanabe, Mohammad Shoeybi, Bryan Catanzaro, Rafael Valle, Wei Ping
分类: cs.SD, cs.CL, cs.LG
发布日期: 2025-10-13
💡 一句话要点
提出UALM统一音频语言模型,实现音频理解、生成和跨模态推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音频语言模型 统一建模 文本到音频生成 多模态推理 跨模态生成 音频理解 自回归模型
📋 核心要点
- 现有音频语言模型通常将音频理解和文本到音频生成视为独立任务,缺乏统一建模方法。
- UALM通过统一的架构和训练策略,将音频理解、文本到音频生成和多模态推理整合到一个模型中。
- 实验表明,UALM在各项任务中均能达到或超过现有专用模型的性能,并首次实现了跨模态生成推理。
📝 摘要(中文)
本文提出了一种统一音频语言模型(UALM),旨在将音频理解、文本到音频生成和多模态推理整合到一个模型中。为了实现这一目标,首先提出了UALM-Gen,一个直接预测音频token的文本到音频语言模型,其性能可与最先进的基于扩散的模型相媲美。然后,通过适当的数据混合、训练技巧和推理技术,证明了单个UALM模型在音频理解、文本到音频生成和文本推理方面,能够达到最先进的专用模型的质量。此外,还提出了UALM-Reason,一个多模态推理模型,它在中间的思考步骤中利用文本和音频,以促进复杂的生成任务。据我们所知,这是音频研究中首次展示跨模态生成推理,其有效性已通过主观评估得到证实。
🔬 方法详解
问题定义:现有音频语言模型通常针对特定任务进行优化,例如音频理解或文本到音频生成,缺乏一个能够同时处理多种任务的统一模型。这限制了模型在复杂场景下的应用,例如需要结合音频和文本信息进行推理和生成的任务。
核心思路:UALM的核心思路是构建一个统一的音频语言模型,该模型能够理解音频和文本信息,并能够生成音频。通过将不同的任务(音频理解、文本到音频生成、多模态推理)统一到同一个模型中,可以实现知识共享和迁移,从而提高模型的性能和泛化能力。
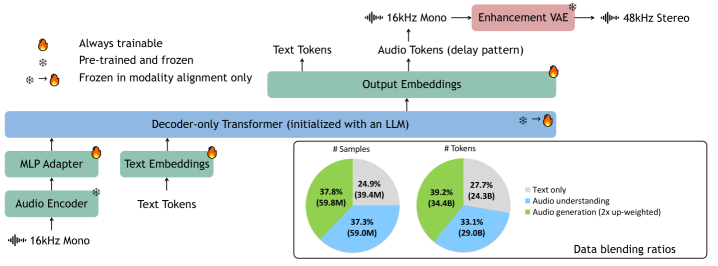
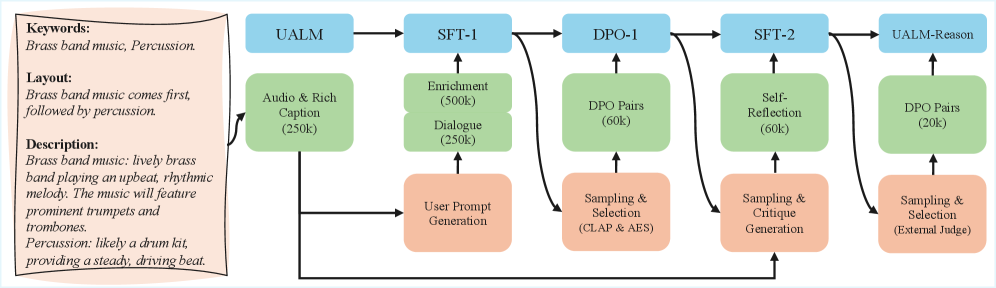
技术框架:UALM包含两个主要模块:UALM-Gen和UALM-Reason。UALM-Gen是一个文本到音频的语言模型,它直接预测音频token。UALM-Reason是一个多模态推理模型,它利用文本和音频信息进行中间推理步骤,以促进复杂的生成任务。整个框架通过数据混合、训练技巧和推理技术进行优化。
关键创新:UALM的关键创新在于其统一的建模方法,它将音频理解、文本到音频生成和多模态推理整合到一个模型中。此外,UALM-Reason首次在音频研究中展示了跨模态生成推理的能力。
关键设计:UALM-Gen采用自回归Transformer架构,直接预测音频token。UALM-Reason则利用文本和音频信息进行中间推理步骤,具体实现细节未知。数据混合策略用于平衡不同任务的数据量,训练技巧包括学习率调整和正则化方法,推理技术包括beam search和sampling。
🖼️ 关键图片
📊 实验亮点
UALM在音频理解、文本到音频生成和文本推理任务中均取得了与最先进的专用模型相当的性能。此外,UALM-Reason首次实现了跨模态生成推理,并通过主观评估验证了其有效性。具体的性能指标和对比基线在论文中进行了详细描述,但此处未提供具体数值。
🎯 应用场景
UALM具有广泛的应用前景,例如智能语音助手、音频内容创作、音乐生成、语音修复等。通过统一建模,UALM能够更好地理解和生成音频,并能够进行跨模态推理,从而实现更智能、更自然的人机交互。未来,UALM有望在教育、娱乐、医疗等领域发挥重要作用。
📄 摘要(原文)
Recent advances in the audio language modeling (ALM) domain tackle audio understanding and text-to-audio generation as separate tasks. Very few studies attempt to unify these tasks -- an essential step toward advanced multimodal reasoning. This paper introduces U}nified Audio Language Model (UALM), which aims to unify audio understanding, text-to-audio generation, and multimodal reasoning in a single model. To achieve this goal, we first present UALM-Gen, a text-to-audio language model that directly predicts audio tokens and is comparable to state-of-the-art diffusion-based models. We then demonstrate, using proper data blending, training recipes, and inference techniques, that our single UALM model matches the quality of state-of-the-art specialized models in audio understanding, text-to-audio generation, and text reasoning. Furthermore, we present UALM-Reason, a multimodal reasoning model that utilizes both text and audio in the intermediate thinking steps to facilitate complex generation tasks. To our knowledge, this is the first demonstration in audio research of cross-modal generative reasoning, with its effectiveness confirmed by subjective evaluations.