Direct Multi-Token Decoding
作者: Xuan Luo, Weizhi Wang, Xifeng Yan
分类: cs.CL, cs.AI
发布日期: 2025-10-13
💡 一句话要点
提出直接多Token解码(DMTD),加速Decoder-only LLM推理且无需额外参数。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理加速 多Token解码 Decoder-only Transformer 模型优化
📋 核心要点
- 现有LLM推理效率受限,需重复遍历所有层,计算成本高昂。
- DMTD利用LLM层级特性,仅用后期层解码多Token,减少计算冗余。
- 实验表明,DMTD在Qwen3-4B模型上实现2倍加速,性能损失小,且可随数据量提升。
📝 摘要(中文)
由于其强大的性能,仅解码器Transformer已成为大型语言模型(LLM)的标准架构。最近的研究表明,在预训练的LLM中,早期、中期和后期层可能具有不同的作用:早期层侧重于理解输入上下文,中间层处理特定于任务的处理,而后期层将抽象表示转换为输出token。我们假设,一旦表示经过早期和中间层的处理,由此产生的隐藏状态可能包含足够的信息,仅使用后期层即可支持生成多个token,从而无需重复遍历早期和中间层。我们将这种推理范式称为直接多Token解码(DMTD)。与推测解码不同,我们的方法不引入额外的参数、辅助例程或生成后验证。尽管在有限的数据集上进行了训练,但经过微调的DMTD Qwen3-4B模型已经展示了有希望的结果,在性能损失很小的情况下,实现了高达2倍的加速。此外,正如我们的缩放分析所示,其性能预计会随着更大的训练数据集而进一步提高。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)推理过程中,decoder-only Transformer架构需要逐个token进行解码,每次解码都需要完整地遍历所有网络层。这种重复计算导致推理速度较慢,计算资源消耗大,尤其是在生成长文本时,效率瓶颈更加明显。
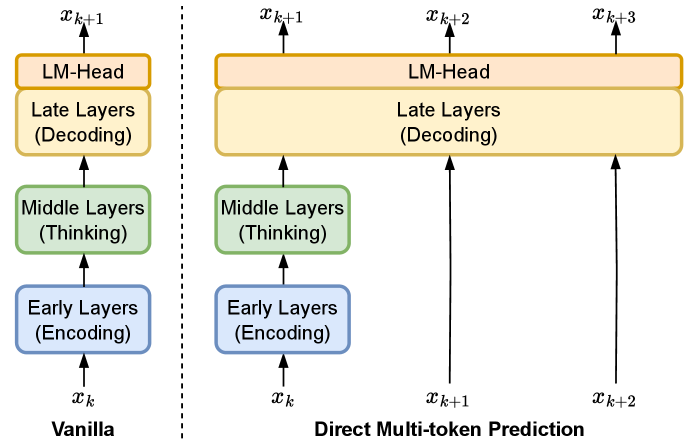
核心思路:论文的核心思路是利用LLM不同层级的特性,认为早期和中间层主要负责理解上下文和进行任务相关的处理,而后期层负责将抽象表示转化为具体的token。因此,一旦经过早期和中间层的处理,得到的隐藏状态就包含了足够的信息来生成多个token,无需每次都遍历所有层。
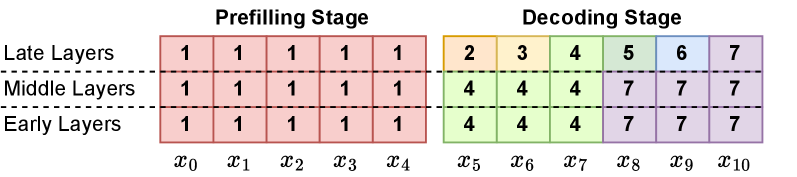
技术框架:DMTD的核心在于直接利用中间层的输出,跳过后续token的早期和中间层计算,直接输入到后期层进行多token的预测。具体流程是:首先,输入序列经过LLM的早期和中间层,得到一个隐藏状态表示;然后,将该隐藏状态输入到LLM的后期层,一次性预测多个token。整个过程无需额外的参数、辅助例程或后处理验证。
关键创新:DMTD的关键创新在于提出了一个无需额外参数、辅助例程或后处理验证的加速LLM推理的方法。与推测解码等方法不同,DMTD直接利用了LLM自身的层级结构,避免了引入额外的复杂性。本质区别在于,DMTD是对LLM内部计算流程的优化,而推测解码等方法是在LLM外部增加辅助机制。
关键设计:论文中没有明确给出关键的参数设置、损失函数或网络结构等技术细节,因为DMTD方法本身是对现有LLM推理流程的优化,并不涉及对模型结构的修改或训练方式的改变。关键在于如何确定哪些层是早期、中期和后期层,以及如何有效地利用中间层的输出进行多token预测。这部分细节可能需要根据具体的LLM架构进行调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在Qwen3-4B模型上,经过微调的DMTD方法可以在性能损失很小的情况下,实现高达2倍的推理速度提升。此外,缩放分析表明,随着训练数据集的增大,DMTD的性能有望进一步提升,这表明DMTD具有良好的可扩展性。
🎯 应用场景
DMTD可广泛应用于各种需要快速文本生成的场景,例如:在线客服、机器翻译、文本摘要、代码生成等。通过提高LLM的推理速度,DMTD可以降低计算成本,提升用户体验,并促进LLM在资源受限设备上的部署。未来,DMTD有望成为LLM推理加速的标准方法之一。
📄 摘要(原文)
Decoder-only transformers have become the standard architecture for large language models (LLMs) due to their strong performance. Recent studies suggest that, in pre-trained LLMs, early, middle, and late layers may serve distinct roles: Early layers focus on understanding the input context, middle layers handle task-specific processing, and late layers convert abstract representations into output tokens. We hypothesize that once representations have been processed by the early and middle layers, the resulting hidden states may encapsulate sufficient information to support the generation of multiple tokens using only the late layers, eliminating the need to repeatedly traverse the early and middle layers. We refer to this inference paradigm as Direct Multi-Token Decoding (DMTD). Unlike speculative decoding, our method introduces no additional parameters, auxiliary routines, or post-generation verification. Despite being trained on a limited dataset, a fine-tuned DMTD Qwen3-4B model has already demonstrated promising results, achieving up to a 2x speedup with only minor performance loss. Moreover, as shown in our scaling analysis, its performance is expected to further improve with larger training datasets.