TopoAlign: A Framework for Aligning Code to Math via Topological Decomposition
作者: Yupei Li, Philipp Borchert, Gerasimos Lampouras
分类: cs.CL, cs.AI
发布日期: 2025-10-13
💡 一句话要点
TopoAlign框架通过拓扑分解对齐代码与数学,提升数学LLM的自动形式化能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动形式化 大型语言模型 代码对齐 拓扑分解 数学推理
📋 核心要点
- 现有数学LLM在自动形式化方面存在困难,缺乏大规模的非正式-正式数学陈述对训练数据。
- TopoAlign框架通过拓扑分解将代码与数学公式对齐,无需额外人工标注即可利用代码资源训练数学LLM。
- 实验表明,TopoAlign显著提升了DeepSeek-Math和Herald在数学基准测试上的性能,验证了对齐代码数据的有效性。
📝 摘要(中文)
大型语言模型(LLM)在非正式和正式(如Lean 4)数学推理方面表现出色,但仍难以进行自动形式化,即将非正式数学陈述转换为正式陈述的任务。自动形式化有助于将LLM的非正式推理与形式化证明助手配对,从而实现机器可验证的生成并减轻幻觉。然而,当前数学LLM的性能受到大规模语料库稀缺的限制,特别是包含非正式和正式陈述对的语料库。虽然当前的模型经过训练可以从自然语言指令生成代码,但这些代码与形式化数学之间的结构和句法差异限制了有效的迁移学习。我们提出了TopoAlign,一个框架,可以解锁广泛可用的代码存储库作为数学LLM的训练资源。TopoAlign将代码分解为文档字符串、主函数和依赖函数,并将这些组件重新组合成在结构上反映正式陈述的类似物。这产生了结构对齐的代码数据,可用于训练数学LLM,而无需额外的人工注释。我们训练了两个最先进的模型,DeepSeek-Math和Herald,并在minif2f、Putnam和ProofNet基准上评估它们。TopoAlign为DeepSeek-Math提供了显著的收益,在BEq@10上提高了17.77%,在typecheck@10上提高了68.82%。尽管没有引入新的数学知识,我们的框架在BEq@10和typecheck@10上分别实现了0.12%和1.09%的Herald收益,表明即使对于专门的模型,训练对齐的代码数据也是有益的。
🔬 方法详解
问题定义:现有数学大型语言模型在自动形式化任务中表现不佳,主要原因是缺乏大规模的、包含非正式数学描述和对应形式化代码的数据集。直接使用自然语言到代码的迁移学习效果有限,因为代码的结构和语法与形式化数学存在显著差异。这限制了模型理解和生成形式化数学表达的能力。
核心思路:TopoAlign的核心思路是将代码进行结构化的分解和重组,使其在拓扑结构上与形式化数学表达式更加相似。通过这种方式,可以将大量的代码资源转化为可用于训练数学LLM的对齐数据,从而提高模型在自动形式化任务中的性能。这种方法避免了人工标注的成本,并充分利用了现有的代码资源。
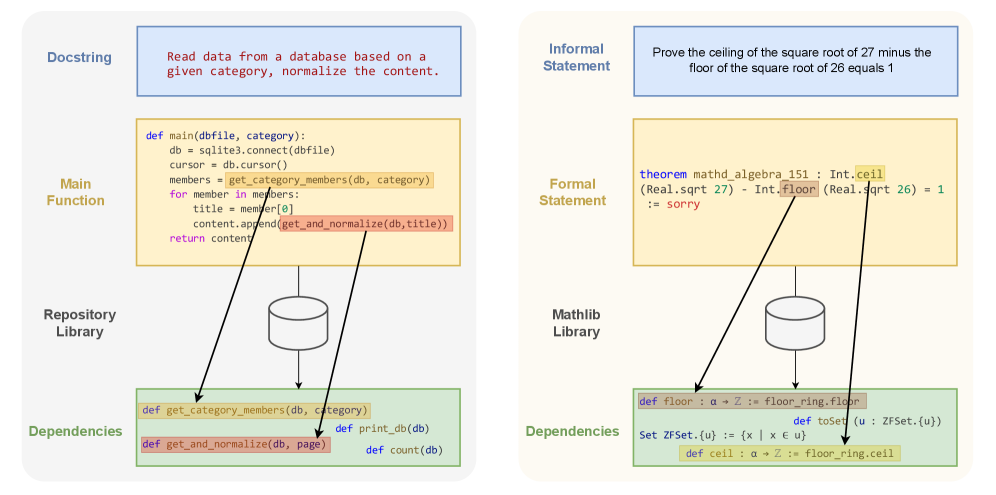
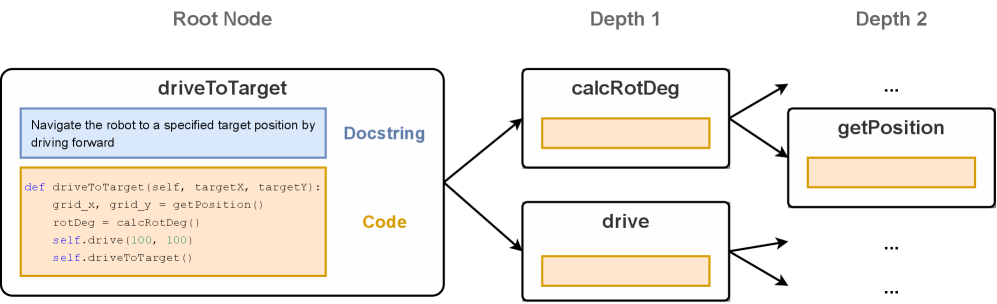
技术框架:TopoAlign框架包含以下主要步骤:1) 代码分解:将代码分解为文档字符串(描述函数功能的注释)、主函数(实现核心逻辑的函数)和依赖函数(被主函数调用的辅助函数)。2) 结构重组:将分解后的组件按照一定的规则重新组合,使其在结构上与形式化数学表达式更加相似。例如,文档字符串可以对应于数学定理的描述,主函数可以对应于定理的证明,依赖函数可以对应于证明过程中使用的引理。3) 数据生成:将重组后的代码数据作为训练数据,用于训练数学LLM。
关键创新:TopoAlign的关键创新在于其拓扑分解和重组的思想。通过将代码分解为具有明确语义的组件,并按照与形式化数学表达式相似的结构进行重组,TopoAlign有效地弥合了代码和数学之间的结构差异。这种方法使得数学LLM能够更好地理解代码中的数学含义,并生成更准确的形式化数学表达式。
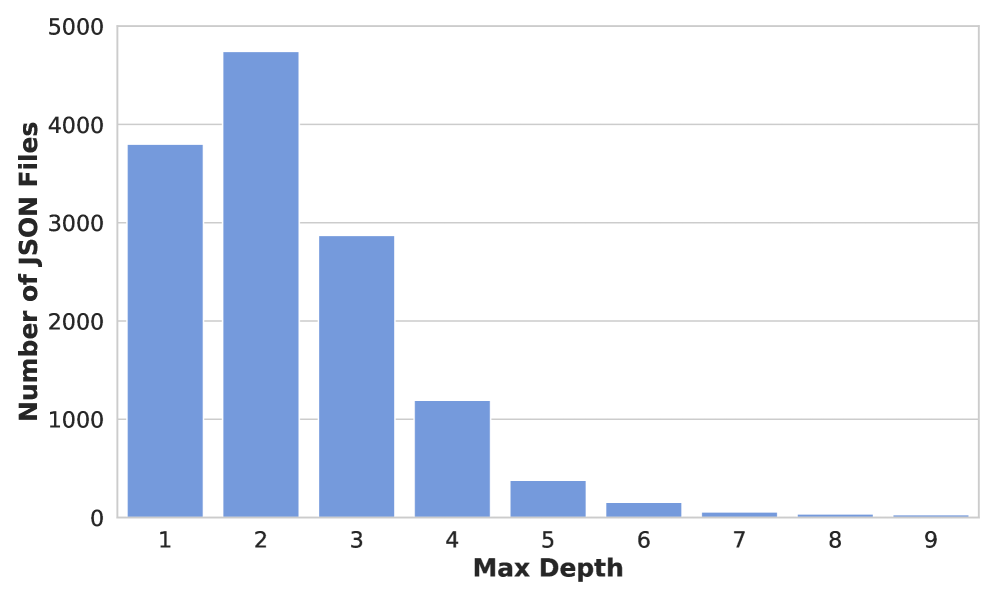
关键设计:TopoAlign框架的关键设计包括:1) 代码分解的粒度:选择合适的代码分解粒度,以确保分解后的组件具有明确的语义,并且易于与形式化数学表达式对应。2) 结构重组的规则:设计合理的结构重组规则,以确保重组后的代码数据在结构上与形式化数学表达式相似。3) 训练数据的选择:选择高质量的代码数据作为训练数据,以提高模型的性能。具体的参数设置、损失函数和网络结构等技术细节取决于所使用的数学LLM。
🖼️ 关键图片
📊 实验亮点
TopoAlign框架在minif2f、Putnam和ProofNet基准测试中取得了显著的成果。对于DeepSeek-Math模型,在BEq@10指标上提升了17.77%,在typecheck@10指标上提升了68.82%。即使对于专门的数学模型Herald,在BEq@10和typecheck@10指标上分别实现了0.12%和1.09%的提升。这些结果表明,通过TopoAlign框架对齐的代码数据可以有效地提高数学LLM的性能。
🎯 应用场景
TopoAlign框架可应用于提升数学LLM的自动形式化能力,从而促进数学研究的自动化和验证。该技术可用于构建更强大的数学证明助手,帮助数学家验证其证明的正确性,并发现新的数学定理。此外,该框架还可用于教育领域,帮助学生更好地理解和学习数学知识。
📄 摘要(原文)
Large Language Models (LLMs) excel at both informal and formal (e.g. Lean 4) mathematical reasoning but still struggle with autoformalisation, the task of transforming informal into formal mathematical statements. Autoformalisation helps pair the informal reasoning of LLMs with formal proof assistants which enable machine-verifiable generation and mitigate hallucinations. Yet, the performance of current Math LLMs is constrained by the scarcity of large-scale corpora, particularly those containing pairs of informal and formal statements. Although current models are trained to generate code from natural language instructions, structural and syntactic differences between these and formal mathematics limit effective transfer learning. We propose TopoAlign, a framework that unlocks widely available code repositories as training resources for Math LLMs. TopoAlign decomposes code into docstrings, main functions, and dependency functions, and reassembles these components into analogues that structurally mirror formal statements. This produces structurally aligned code data that can be used for training Math LLMs without requiring additional human annotation. We train two state-of-the-art models, DeepSeek-Math and Herald, and evaluate them on the minif2f, Putnam, and ProofNet benchmarks. TopoAlign provides substantial gains for DeepSeek-Math, improving performance by 17.77% on BEq@10 and 68.82% on typecheck@10. Despite introducing no new mathematical knowledge, our framework achieves gains of 0.12% and 1.09% for Herald on BEq@10 and typecheck@10, respectively, demonstrating that training on aligned code data is beneficial even for specialized models.