LLM Knowledge is Brittle: Truthfulness Representations Rely on Superficial Resemblance
作者: Patrick Haller, Mark Ibrahim, Polina Kirichenko, Levent Sagun, Samuel J. Bell
分类: cs.CL, cs.LG
发布日期: 2025-10-13
💡 一句话要点
研究表明LLM的知识脆弱性源于对表面相似性的依赖,而非稳健的知识表示。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 知识表示 鲁棒性 脆弱性 泛化能力
📋 核心要点
- 大型语言模型在不同场景下的泛化能力不足,对输入微小变化敏感,存在知识脆弱性问题。
- 通过研究LLM内部对语句真实性的表示,分析其在经过表面转换的OOD样本上的可分离性,评估知识鲁棒性。
- 实验结果表明,LLM对语句真实性的判断依赖于表面形式,而非稳健的知识表示,这解释了其脆弱的基准性能。
📝 摘要(中文)
为了保证大型语言模型(LLM)的可靠性,它们必须学习能够在各种环境中普遍应用的稳健知识,这些环境通常与训练期间所见的环境不同。然而,大量的研究表明,LLM的性能可能是脆弱的,模型对微不足道的输入变化表现出过度的敏感性。本文探讨了这种脆弱性是否是不稳定的内部知识表示的直接结果。为了探索这个问题,我们建立在先前的工作基础上,这些工作表明LLM表示编码了语句的真实性——即,真实、基于事实的语句可以很容易地与虚假、不准确的语句区分开来。具体来说,我们通过评估经过表面转换使其脱离分布(OOD)的样本(例如,拼写错误或重新表述)上的表示可分离性来测试学习知识的鲁棒性。通过应用语义保留扰动,我们研究了在四个LLM家族、五个评估数据集和三种知识探测方法中,随着语句变得越来越OOD,可分离性如何降低。我们的结果表明,当样本的呈现方式与预训练期间所见的呈现方式不太相似时,语句真实性的内部表示就会崩溃。虽然LLM通常可以区分真实和虚假语句,但这种能力高度依赖于语句的确切表面形式。这些发现为脆弱的基准性能提供了一种可能的解释:LLM可能学习了浅层的、非稳健的知识表示,这些表示只允许有限的泛化。我们的工作对真实性探测的效用提出了根本性的挑战,更广泛地说,呼吁进一步研究以提高学习知识表示的鲁棒性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对与训练数据存在表面差异的输入时,表现出的知识脆弱性问题。现有方法未能充分解决LLM对输入形式的过度依赖,导致其泛化能力受限。LLM在基准测试中表现出的脆弱性,可能源于其学习到的知识表示不够稳健,无法应对分布外的输入。
核心思路:论文的核心思路是通过研究LLM内部对语句真实性的表示,来评估其知识的鲁棒性。具体而言,通过对输入语句进行表面转换(如拼写错误、重新表述),使其脱离原始分布,然后观察LLM内部表示的可分离性如何变化。如果LLM对真实和虚假语句的区分能力随着输入形式的变化而显著下降,则表明其知识表示是脆弱的,依赖于表面相似性。
技术框架:论文的技术框架主要包括以下几个步骤: 1. 选择LLM家族和评估数据集:选择多个LLM家族(例如,不同架构或训练规模的LLM)和多个知识评估数据集,以确保研究结果的普遍性。 2. 生成OOD样本:对评估数据集中的语句进行表面转换,例如添加拼写错误、进行同义词替换或重新表述,从而生成与原始训练数据存在差异的OOD样本。 3. 知识探测:使用知识探测方法(例如,线性分类器)来评估LLM内部表示对语句真实性的编码能力。具体而言,训练一个分类器来区分LLM对真实和虚假语句的内部表示。 4. 评估可分离性:评估分类器在原始数据集和OOD数据集上的性能,以衡量LLM内部表示的可分离性。可分离性的下降表明知识表示的脆弱性。
关键创新:论文最重要的技术创新点在于,它提供了一种评估LLM知识鲁棒性的新方法,通过研究LLM内部表示对OOD样本的敏感性,揭示了LLM知识的脆弱性。与现有方法相比,该方法更直接地关注LLM内部知识表示的质量,而非仅仅关注其在基准测试中的性能。
关键设计:论文的关键设计包括: 1. 语义保留扰动:使用语义保留的扰动方法来生成OOD样本,以确保输入语句的语义不变,从而可以更准确地评估LLM对表面形式变化的敏感性。 2. 多种知识探测方法:使用多种知识探测方法来评估LLM内部表示,以确保研究结果的稳健性。 3. 跨LLM家族和数据集的评估:在多个LLM家族和数据集上进行评估,以确保研究结果的普遍性。
🖼️ 关键图片
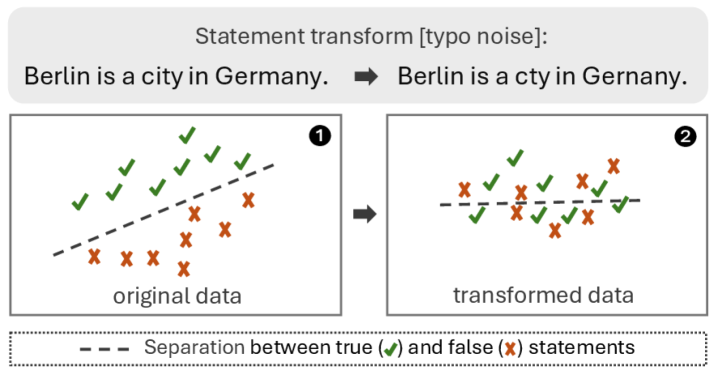
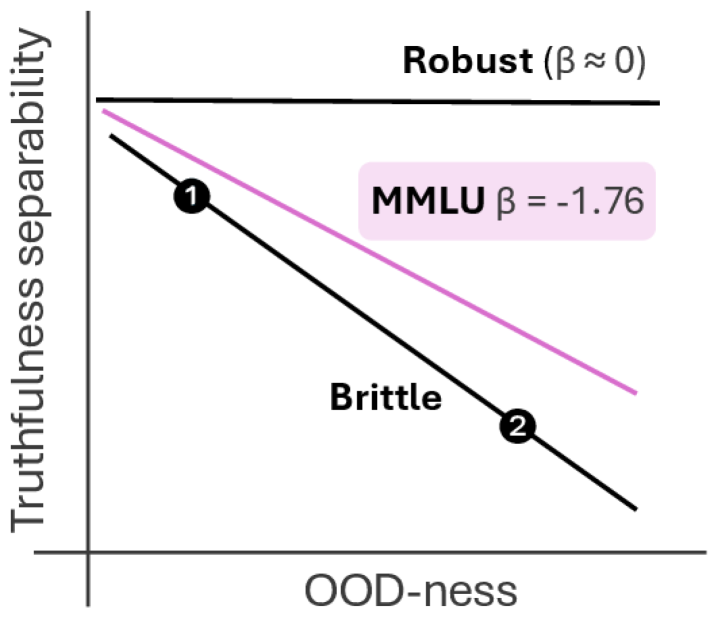
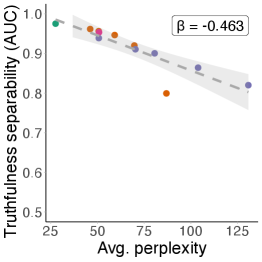
📊 实验亮点
实验结果表明,LLM在经过表面转换的OOD样本上的表现显著下降,验证了LLM知识的脆弱性。例如,在某些数据集上,经过简单拼写错误的语句,其真实性判断准确率下降了超过20%。该研究还发现,不同LLM家族和知识探测方法都表现出类似的脆弱性,表明该现象具有普遍性。
🎯 应用场景
该研究成果可应用于提升大型语言模型的可靠性和泛化能力。通过理解LLM知识表示的脆弱性,可以指导模型训练和知识表示学习,使其能够更好地应对真实世界中复杂多变的输入。这对于开发更值得信赖的AI系统,尤其是在需要高度准确性和可靠性的应用领域(如医疗诊断、金融分析等)至关重要。
📄 摘要(原文)
For Large Language Models (LLMs) to be reliable, they must learn robust knowledge that can be generally applied in diverse settings -- often unlike those seen during training. Yet, extensive research has shown that LLM performance can be brittle, with models exhibiting excessive sensitivity to trivial input variations. In this work, we explore whether this brittleness is a direct result of unstable internal knowledge representations. To explore this question, we build on previous work showing that LLM representations encode statement truthfulness -- i.e., true, factual statements can be easily separated from false, inaccurate ones. Specifically, we test the robustness of learned knowledge by evaluating representation separability on samples that have undergone superficial transformations to drive them out-of-distribution (OOD), such as typos or reformulations. By applying semantically-preserving perturbations, we study how separability degrades as statements become more OOD, across four LLM families, five evaluation datasets, and three knowledge probing methods. Our results reveal that internal representations of statement truthfulness collapse as the samples' presentations become less similar to those seen during pre-training. While LLMs can often distinguish between true and false statements when they closely resemble the pre-training data, this ability is highly dependent on the statement's exact surface form. These findings offer a possible explanation for brittle benchmark performance: LLMs may learn shallow, non-robust knowledge representations that allow for only limited generalizability. Our work presents a fundamental challenge for the utility of truthfulness probes, and more broadly, calls for further research on improving the robustness of learned knowledge representations.