R-WoM: Retrieval-augmented World Model For Computer-use Agents
作者: Kai Mei, Jiang Guo, Shuaichen Chang, Mingwen Dong, Dongkyu Lee, Xing Niu, Jiarong Jiang
分类: cs.CL
发布日期: 2025-10-13
💡 一句话要点
提出R-WoM,通过检索增强LLM世界模型,提升计算机使用Agent在数字环境中的决策能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 世界模型 大型语言模型 检索增强 计算机使用Agent 长时程规划
📋 核心要点
- LLM作为世界模型在数字环境中的应用受限于其幻觉问题和静态知识,导致长时程模拟性能下降。
- R-WoM通过检索外部教程中的知识来增强LLM,弥补了LLM在知识更新和事实性方面的不足。
- 实验结果表明,R-WoM在OSWorld和WebArena等任务上显著优于基线模型,尤其在长时程模拟中。
📝 摘要(中文)
大型语言模型(LLMs)可以通过模拟未来状态和预测行动结果,作为世界模型来增强Agent在数字环境中的决策能力,从而潜在地消除代价高昂的试错探索。然而,这种能力从根本上受到LLMs幻觉倾向和对静态训练知识的依赖的限制,这可能导致复合误差,从而抑制长时程模拟。为了系统地研究LLMs是否适合世界建模,我们通过三个任务——下一状态识别、完整流程规划对齐和里程碑转换识别——来探究世界模型的两个核心能力——未来状态预测和奖励估计。我们的分析表明,虽然LLMs有效地捕获了即时下一状态并识别出有意义的状态转换,但它们在完整流程规划中的性能迅速下降。这突出了LLMs在可靠地建模长时程环境动态方面的局限性。为了解决这些局限性,我们提出了检索增强世界模型(R-WoM),它通过结合从外部教程中检索到的事实性的、最新的知识来支持LLM模拟。实验表明,与基线相比,R-WoM取得了显著的改进,在OSWorld上高达25.3%,在WebArena上高达18.1%,尤其是在长时程模拟中。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在作为计算机使用Agent的世界模型时,由于幻觉和依赖静态训练知识而导致的长期规划能力不足的问题。现有方法难以准确预测未来状态和估计奖励,尤其是在需要多步骤操作的复杂任务中,误差会随着步骤增加而累积。
核心思路:论文的核心思路是通过检索增强的方式,为LLM提供外部的、最新的知识,从而减少幻觉,提高预测的准确性。具体来说,R-WoM从外部教程中检索相关信息,并将这些信息融入到LLM的推理过程中,使其能够更好地理解环境动态,做出更合理的决策。
技术框架:R-WoM的整体框架包含以下几个主要模块:1) 状态表示:将当前环境状态进行编码,输入到检索模块。2) 知识检索:根据当前状态,从外部知识库(例如教程文档)中检索相关信息。3) 知识融合:将检索到的知识与LLM的内部知识进行融合,形成增强的上下文信息。4) 状态预测与奖励估计:利用增强的上下文信息,LLM预测下一步的状态和执行动作的奖励。5) 行动决策:基于状态预测和奖励估计,选择最优的行动。
关键创新:R-WoM的关键创新在于将检索增强技术应用于LLM世界模型,使其能够动态地获取和利用外部知识。与传统的LLM世界模型相比,R-WoM不再仅仅依赖于静态的训练数据,而是能够根据当前环境的需要,实时地获取相关信息,从而提高了模型的适应性和泛化能力。
关键设计:论文中可能涉及的关键设计包括:1) 检索模块的设计:如何高效地从海量知识库中检索到相关信息?可能采用基于向量相似度的检索方法。2) 知识融合策略:如何将检索到的知识有效地融入到LLM的推理过程中?可能采用注意力机制或者其他融合策略。3) 损失函数的设计:如何训练R-WoM,使其能够更好地利用检索到的知识进行预测?可能采用结合预测误差和检索相关性的损失函数。
🖼️ 关键图片
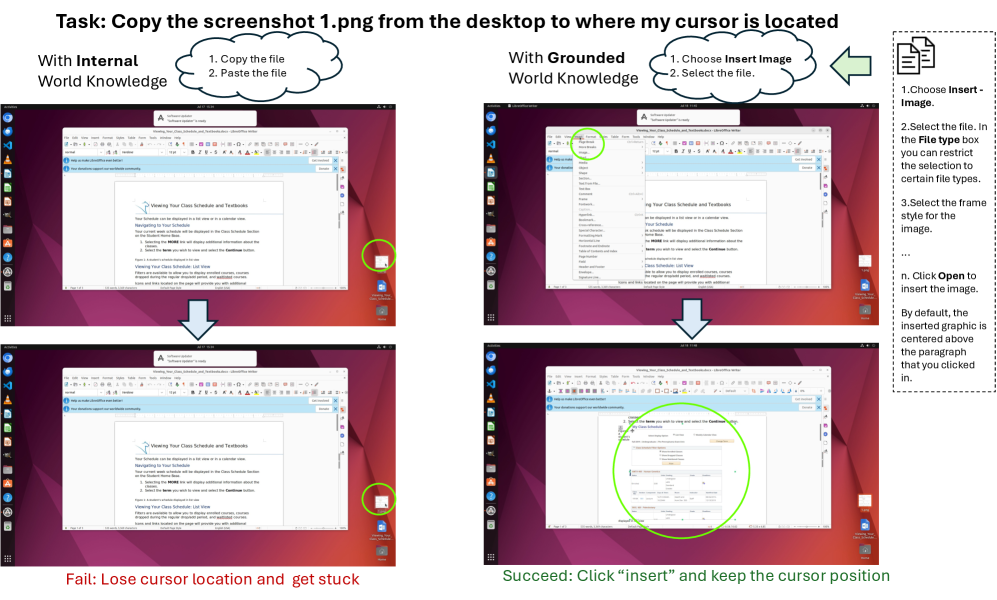
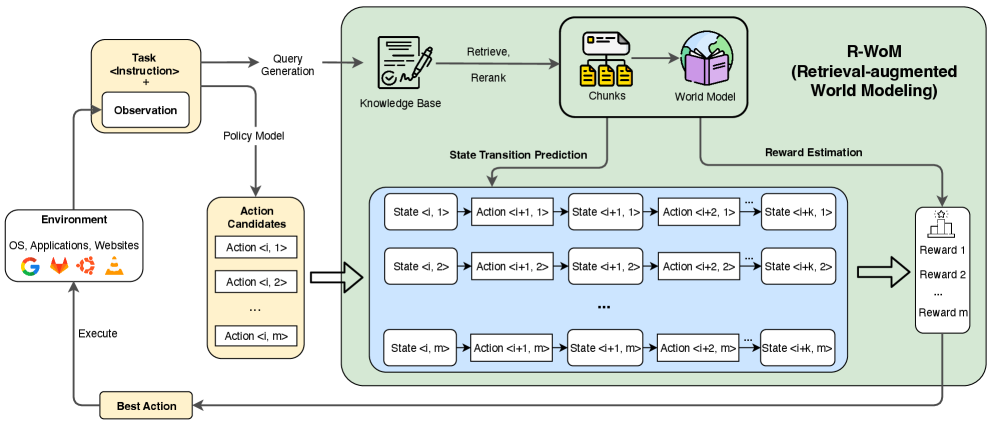
📊 实验亮点
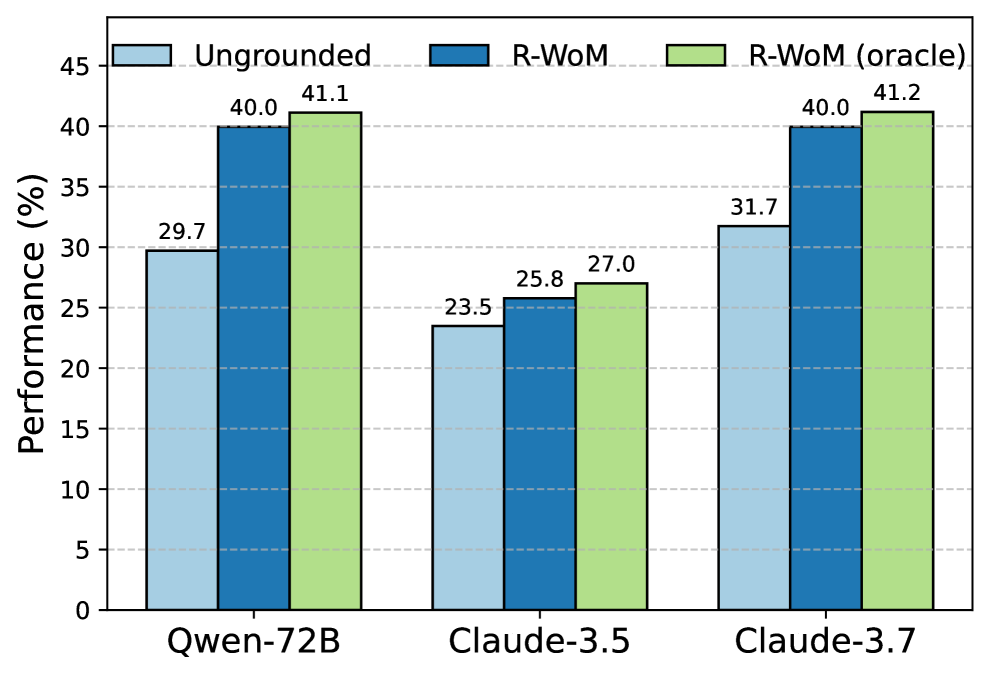
实验结果表明,R-WoM在OSWorld和WebArena两个数据集上均取得了显著的性能提升。在OSWorld上,R-WoM相比基线模型提升了高达25.3%,在WebArena上提升了18.1%。尤其是在长时程模拟任务中,R-WoM的优势更加明显,证明了其在复杂环境中的有效性。
🎯 应用场景
R-WoM具有广泛的应用前景,例如自动化办公、智能客服、游戏AI等领域。它可以帮助Agent更好地理解用户意图,执行复杂任务,并提供更智能化的服务。未来,R-WoM可以进一步扩展到更复杂的环境和任务中,例如机器人控制、自动驾驶等。
📄 摘要(原文)
Large Language Models (LLMs) can serve as world models to enhance agent decision-making in digital environments by simulating future states and predicting action outcomes, potentially eliminating costly trial-and-error exploration. However, this capability is fundamentally limited by LLMs' tendency toward hallucination and their reliance on static training knowledge, which can lead to compounding errors that inhibit long-horizon simulations. To systematically investigate whether LLMs are appropriate for world modeling, we probe two core capabilities of world models--future state prediction and reward estimation--through three tasks: next-state identification, full-procedure planning alignment, and milestone transition recognition. Our analysis shows that while LLMs effectively capture immediate next states and identify meaningful state transitions, their performance rapidly degrades in full-procedure planning. This highlights LLMs' limitations in reliably modeling environment dynamics over long horizons. To address these limitations, we propose the Retrieval-augmented World Model (R-WoM), which grounds LLM simulations by incorporating factual, up-to-date knowledge retrieved from external tutorials. Experiments show that R-WoM achieves substantial improvements of up to 25.3% (OSWorld) and 18.1% (WebArena) compared to baselines, with particular advantages in longer-horizon simulations.