PHANTOM RECALL: When Familiar Puzzles Fool Smart Models
作者: Souradeep Mukhopadhyay, Rishabh Baral, Nimeesh Mahajan, Samhitha Harish, Aswin RRV, Mihir Parmar, Mutsumi Nakamura, Chitta Baral
分类: cs.CL, cs.AI
发布日期: 2025-10-13
备注: 22 Pages
💡 一句话要点
PHANTOM RECALL基准测试揭示LLM在逻辑推理中对记忆模板的过度依赖
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 逻辑推理 基准测试 幻影回忆 推理错误 提示工程 自动化推理
📋 核心要点
- 现有LLM在逻辑推理中过度依赖记忆模板,缺乏真正的推理能力,导致在谜题稍作修改后性能显著下降。
- 提出PHANTOM RECALL基准测试,包含多种逻辑谜题及其扰动版本,用于系统评估LLM的推理能力。
- 通过实验发现LLM存在“幻影回忆”现象,并提出了自动逻辑等价判断器、错误分类法和提示缓解框架等工具。
📝 摘要(中文)
大型语言模型(LLM),如GPT、Gemini和Claude,在解决经典逻辑谜题时表现出色,但其答案背后有多少是真正的推理?现有证据表明,这些模型经常依赖记忆的模板,而非从第一性原理进行推理。当谜题稍作修改时,它们的性能会急剧下降,暴露出惊人的脆弱性。为了系统地研究这些问题,我们引入了PHANTOM RECALL,一个包含25个著名逻辑谜题和149个精心设计的扰动的基准,这些扰动保留了推理结构,但改变了表面细节和解决方案。我们评估了11个领先的LLM,并发现了一种反复出现的失败模式——幻影回忆——模型自信地重现记忆的解决方案或不再适合改变后的场景的虚假理由。为了探究和缓解这个问题,我们贡献了三个工具:(i)一个自动逻辑等价判断器,用于检测推理不匹配,(ii)一个细粒度推理错误类别分类法,以及(iii)一个由这些类别指导的基于提示的缓解框架。尽管在未修改的谜题上具有接近完美的准确性,但在扰动后的谜题上,模型的表现明显低于人类,表现出幻影回忆和过度阐述。我们的发现揭示了一个关键的局限性:当上下文线索发生变化时,LLM常常无法重新推理——突显了语言流畅性和逻辑理解之间的差距。
🔬 方法详解
问题定义:现有的大型语言模型在解决逻辑谜题时,看似表现出色,但实际上可能只是依赖于记忆中的模板,而非进行真正的逻辑推理。当谜题的表面细节发生变化时,模型的性能会显著下降,暴露出其推理能力的脆弱性。因此,需要一种方法来系统地评估LLM的逻辑推理能力,并识别其潜在的缺陷。
核心思路:论文的核心思路是通过构建一个包含逻辑谜题及其扰动版本的基准测试,来评估LLM在面对表面细节变化时,是否能够进行正确的逻辑推理。扰动的设计旨在保留谜题的推理结构,但改变其表面细节和解决方案,从而迫使模型进行真正的推理,而非简单地回忆记忆中的答案。
技术框架:PHANTOM RECALL基准测试包含25个著名的逻辑谜题和149个精心设计的扰动。论文还提出了三个工具来探究和缓解LLM的推理问题:(1)自动逻辑等价判断器,用于检测推理过程中的逻辑不一致性;(2)细粒度推理错误类别分类法,用于分析LLM推理错误的类型;(3)基于提示的缓解框架,利用错误类别信息来指导LLM进行更准确的推理。
关键创新:论文的关键创新在于提出了PHANTOM RECALL基准测试,该基准测试能够有效地评估LLM在面对表面细节变化时的逻辑推理能力。此外,论文还提出了自动逻辑等价判断器和细粒度推理错误类别分类法,为分析和改进LLM的推理能力提供了有力的工具。
关键设计:扰动的设计原则是保留谜题的推理结构,但改变其表面细节和解决方案。例如,可以将谜题中的人物姓名、地点、物品等进行替换,或者改变谜题的背景故事,但保持其逻辑结构不变。自动逻辑等价判断器使用形式逻辑来验证LLM的推理过程是否正确。基于提示的缓解框架利用错误类别信息,通过在提示中加入相关的约束或提示,来引导LLM进行更准确的推理。
🖼️ 关键图片

📊 实验亮点
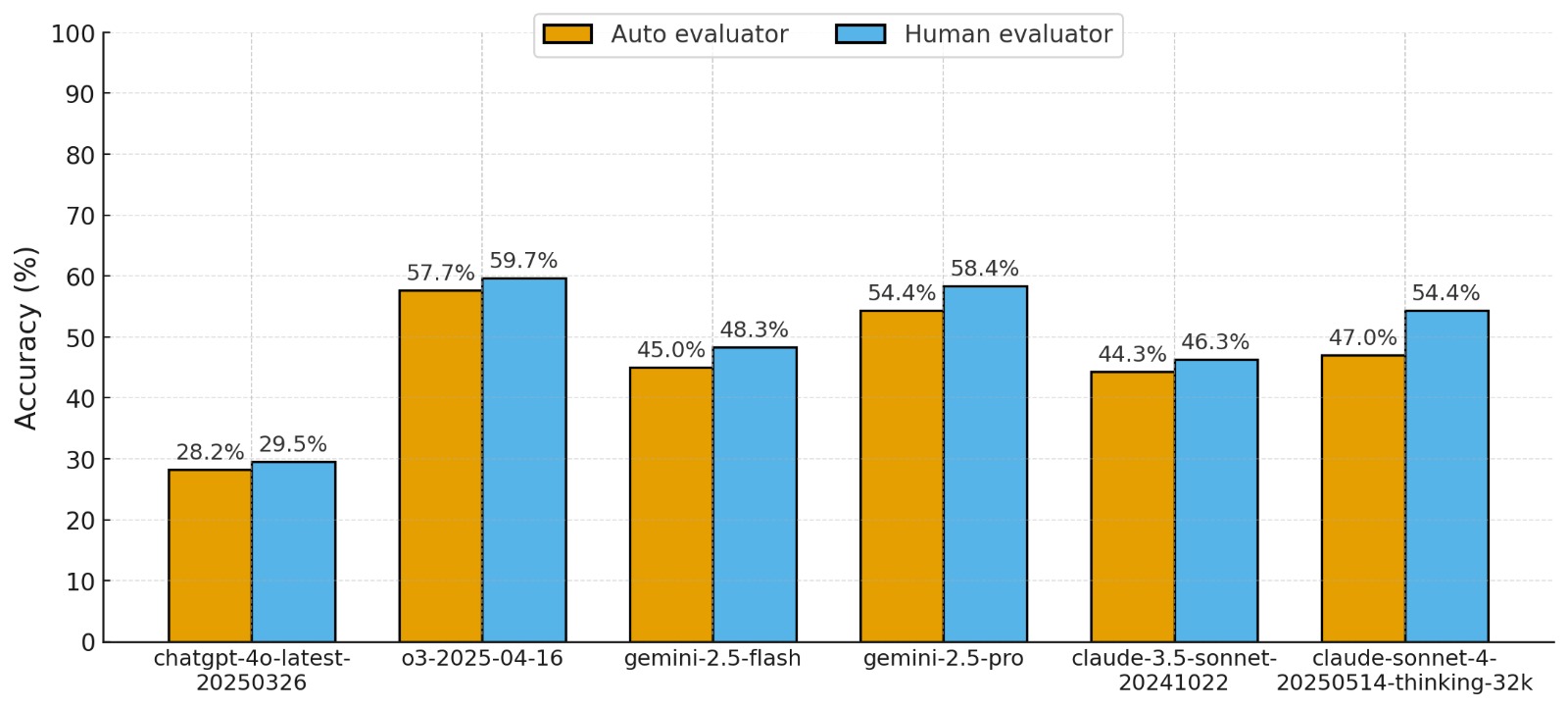
实验结果表明,尽管LLM在未修改的谜题上表现出接近完美的准确性,但在扰动后的谜题上,其性能显著低于人类。例如,在某些扰动后的谜题上,LLM的准确率下降了50%以上,这表明LLM在逻辑推理方面存在严重的缺陷。通过使用基于提示的缓解框架,可以有效地提高LLM在扰动后的谜题上的性能,但仍然无法达到人类的水平。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的逻辑推理能力,提高其在复杂问题解决、智能对话、自动化推理等领域的应用效果。通过PHANTOM RECALL基准测试,可以更全面地了解LLM的优势和局限性,从而开发出更可靠、更智能的AI系统。
📄 摘要(原文)
Large language models (LLMs) such as GPT, Gemini, and Claude often appear adept at solving classic logic puzzles--but how much genuine reasoning underlies their answers? Recent evidence suggests that these models frequently rely on memorized templates rather than reasoning from first principles. When puzzles are slightly modified, their performance collapses, revealing a striking fragility. In particular, we asked: Have LLMs addressed these issues? To what extent? How about perturbations to other puzzles? Is there a general way of reformulating the prompt so that the models do better? To examine these things systematically, we introduce PHANTOM RECALL, a benchmark comprising 25 well-known logic puzzles and 149 carefully designed perturbations that preserve reasoning structure but alter superficial details and solutions. We evaluate eleven leading LLMs and identify a recurring failure mode--phantom recall--where models confidently reproduce memorized solutions or spurious rationales that no longer fit the altered scenario. To probe and mitigate this issue, we contribute three tools: (i) an automated logical-equivalence judge to detect reasoning mismatches, (ii) a taxonomy of fine-grained reasoning error categories, and (iii) a prompting-based mitigation framework guided by these categories. Despite near-perfect accuracy on unmodified puzzles, models significantly underperform humans on perturbed ones, exhibiting both phantom recall and over-elaboration. Our findings reveal a crucial limitation: LLMs often fail to re-reason when contextual cues shift--highlighting the gap between linguistic fluency and logical understanding.