Demystifying Reinforcement Learning in Agentic Reasoning
作者: Zhaochen Yu, Ling Yang, Jiaru Zou, Shuicheng Yan, Mengdi Wang
分类: cs.CL
发布日期: 2025-10-13
备注: Code and models: https://github.com/Gen-Verse/Open-AgentRL
🔗 代码/项目: GITHUB
💡 一句话要点
通过系统性研究揭示Agentic RL在LLM推理中的关键设计原则与实践方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: Agentic RL 强化学习 大型语言模型 工具使用 推理能力
📋 核心要点
- 现有Agentic RL方法在提升LLM推理能力方面缺乏清晰的设计原则和最佳实践指导,导致性能提升受限。
- 该研究从数据、算法和推理模式三个角度,系统性地探索Agentic RL的关键要素,旨在揭示其内在机制。
- 实验结果表明,高质量数据集、探索友好的算法和审慎的推理策略能够显著提升Agentic RL的性能,甚至超越更大模型。
📝 摘要(中文)
本文旨在揭示Agentic RL在提升LLM的Agentic推理能力方面的关键设计原则和最佳实践。通过数据、算法和推理模式三个关键角度的全面系统性研究,我们发现:(1)使用真实的端到端工具使用轨迹替换拼接的合成轨迹,可以产生更强大的SFT初始化;高多样性、模型感知的训练数据集能够维持探索并显著提高RL性能。(2)探索友好的技术对于Agentic RL至关重要,例如clip higher、overlong reward shaping以及维持足够的策略熵可以提高训练效率。(3)采用工具调用次数较少的审慎策略优于频繁工具调用或冗长的自我推理,从而提高工具效率和最终准确性。这些简单实践能够持续增强Agentic推理和训练效率,在具有挑战性的基准测试中以较小的模型实现了强大的结果,并为未来的Agentic RL研究建立了实用的基线。此外,我们还贡献了一个高质量的真实端到端Agentic SFT数据集和一个高质量的RL数据集,并证明了我们的见解在提升LLM在四个具有挑战性的基准测试(包括AIME2024/AIME2025、GPQA-Diamond和LiveCodeBench-v6)中的Agentic推理能力方面的有效性。通过我们的方法,4B大小的模型也可以实现优于32B大小模型的Agentic推理性能。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在Agentic推理中,如何有效利用强化学习(RL)提升其工具使用能力和推理准确性的问题。现有方法通常依赖于合成数据或简单的奖励函数,导致训练效率低下,且难以泛化到复杂任务中。此外,频繁的工具调用和冗长的自我推理也会降低效率和准确性。
核心思路:论文的核心思路是通过系统性地研究数据、算法和推理模式三个关键要素,找到提升Agentic RL性能的关键设计原则和最佳实践。具体而言,论文强调使用真实数据进行预训练,采用探索友好的RL算法,并鼓励模型采用审慎的推理策略。
技术框架:整体框架包括三个主要阶段:(1)使用真实端到端工具使用轨迹训练SFT模型,作为RL的初始化。(2)使用高多样性、模型感知的RL数据集,并采用探索友好的RL算法进行训练。(3)在推理阶段,鼓励模型采用工具调用次数较少的审慎策略。该框架旨在提高训练效率和推理准确性。
关键创新:论文最重要的技术创新点在于对Agentic RL进行了系统性的解构,并提出了三个关键的实践方法:使用真实数据进行SFT初始化、采用探索友好的RL算法、以及鼓励审慎的推理策略。与现有方法相比,该方法更加注重数据的质量和多样性,以及算法的探索能力,从而能够更有效地提升Agentic推理能力。
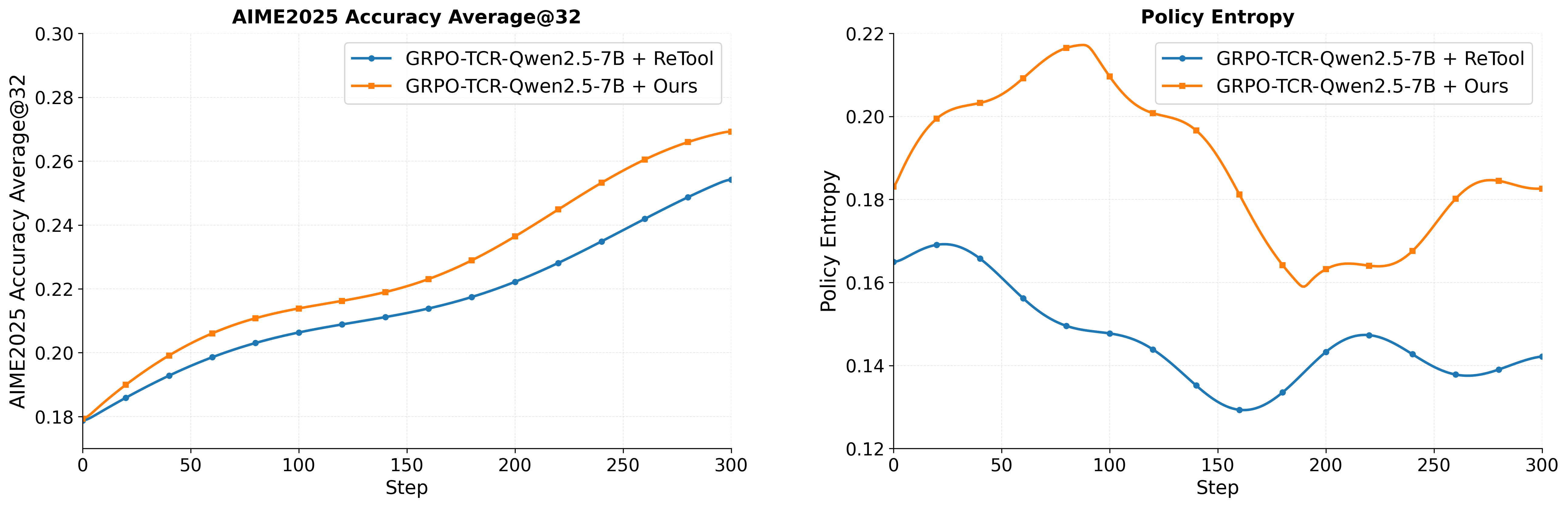
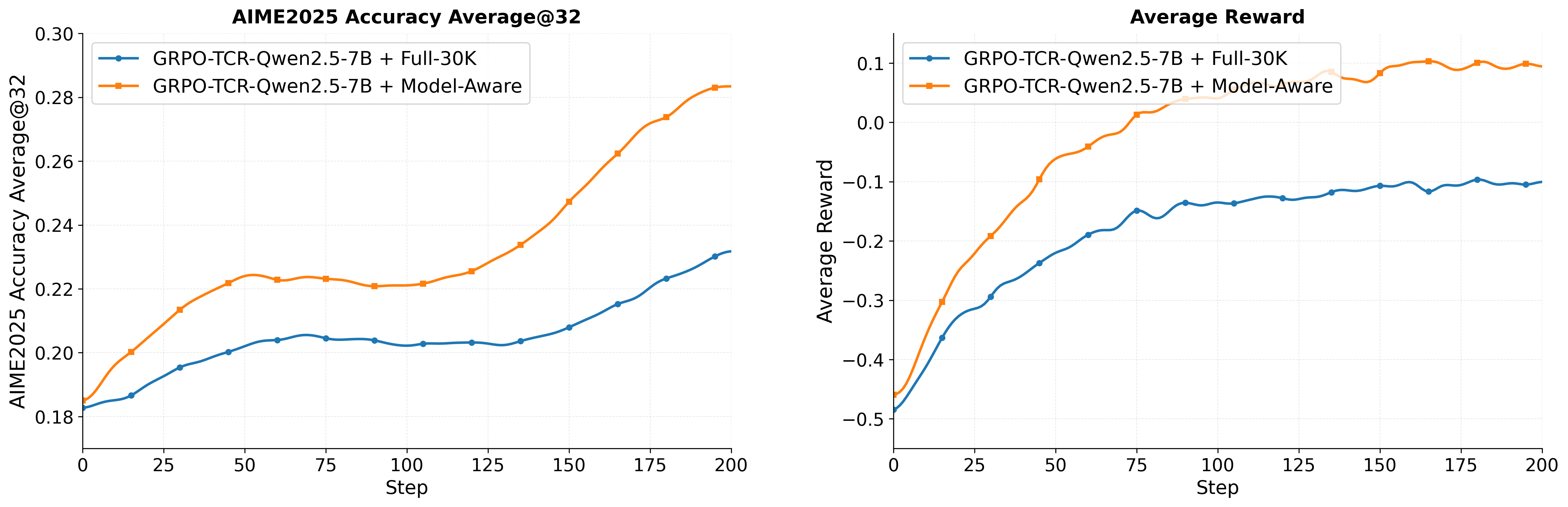
关键设计:在数据方面,论文构建了高质量的真实端到端Agentic SFT和RL数据集。在算法方面,论文采用了clip higher和overlong reward shaping等探索友好的技术,并维持了足够的策略熵。在推理模式方面,论文鼓励模型采用工具调用次数较少的审慎策略。具体参数设置和损失函数细节在论文中进行了详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用该论文提出的方法,4B大小的模型在AIME2024/AIME2025、GPQA-Diamond和LiveCodeBench-v6等基准测试中,可以达到甚至超过32B大小模型的Agentic推理性能。这表明该方法能够显著提升Agentic RL的训练效率和性能,为未来的研究提供了有价值的参考。
🎯 应用场景
该研究成果可广泛应用于需要LLM进行复杂推理和工具使用的场景,例如智能助手、自动化编程、科学研究等。通过提升LLM的Agentic推理能力,可以使其更好地完成各种复杂任务,提高工作效率和决策质量。未来的影响包括更智能的自动化系统和更高效的科学发现。
📄 摘要(原文)
Recently, the emergence of agentic RL has showcased that RL could also effectively improve the agentic reasoning ability of LLMs, yet the key design principles and optimal practices remain unclear. In this work, we conduct a comprehensive and systematic investigation to demystify reinforcement learning in agentic reasoning from three key perspectives: data, algorithm, and reasoning mode. We highlight our key insights: (i) Replacing stitched synthetic trajectories with real end-to-end tool-use trajectories yields a far stronger SFT initialization; high-diversity, model-aware datasets sustain exploration and markedly improve RL performance. (ii) Exploration-friendly techniques are crucial for agentic RL, such as clip higher, overlong reward shaping, and maintaining adequate policy entropy could improve the training efficiency. (iii) A deliberative strategy with fewer tool calls outperforms frequent tool calls or verbose self-reasoning, improving tool efficiency and final accuracy. Together, these simple practices consistently enhance agentic reasoning and training efficiency, achieving strong results on challenging benchmarks with smaller models, and establishing a practical baseline for future agentic RL research. Beyond these empirical insights, we further contribute a high-quality, real end-to-end agentic SFT dataset along with a high-quality RL dataset, and demonstrate the effectiveness of our insights in boosting the agentic reasoning ability of LLMs across four challenging benchmarks, including AIME2024/AIME2025, GPQA-Diamond, and LiveCodeBench-v6. With our recipes, 4B-sized models could also achieve superior agentic reasoning performance compared to 32B-sized models. Code and models: https://github.com/Gen-Verse/Open-AgentRL