Scaling Language-Centric Omnimodal Representation Learning
作者: Chenghao Xiao, Hou Pong Chan, Hao Zhang, Weiwen Xu, Mahani Aljunied, Yu Rong
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-10-13
备注: NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出LCO-Emb框架,通过语言中心的多模态表征学习,提升跨模态检索性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态表征学习 跨模态检索 大型语言模型 对比学习 生成式预训练 表征对齐 缩放定律
📋 核心要点
- 现有基于MLLM的多模态嵌入方法缺乏对其优越性的深入理解,需要探究其内在机制。
- LCO-Emb框架利用MLLM生成式预训练中的隐式跨模态对齐,并通过对比学习进行轻量级优化。
- 实验表明,LCO-Emb在多种模态上实现了SOTA性能,并验证了生成能力与表征能力之间的缩放定律。
📝 摘要(中文)
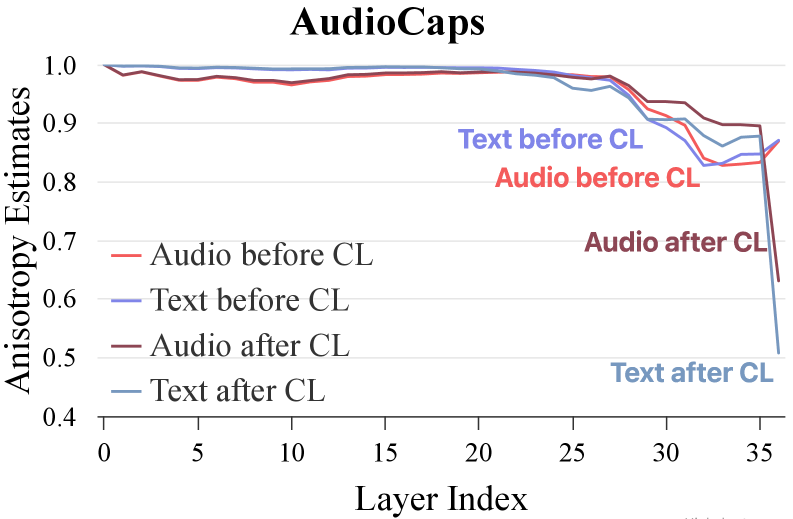
本文深入研究了基于多模态大型语言模型(MLLM)并采用对比学习(CL)进行微调的多模态嵌入方法的优势。研究表明,MLLM方法的一个关键优势在于生成式预训练过程中实现的隐式跨模态对齐,其中语言解码器学习利用共享表征空间内的多模态信号来生成单模态输出。通过对各向异性和核相似性结构的分析,证实了MLLM表征中潜在对齐的出现,使得CL可以作为轻量级的优化阶段。基于此,本文提出了一个以语言为中心的全模态嵌入框架,称为LCO-Emb。在不同的骨干网络和基准测试中进行的大量实验证明了其有效性,并在各种模态中实现了最先进的性能。此外,本文还提出了一个生成-表征缩放定律(GRSL),表明通过对比优化获得的表征能力与MLLM的生成能力呈正相关。这表明,提高生成能力是增强表征质量的有效范例。本文对GRSL进行了理论解释,将MLLM的生成质量与其表征性能的上限正式联系起来,并在具有挑战性的低资源视觉-文档检索任务中验证了它,表明在CL之前进行持续的生成式预训练可以进一步增强模型嵌入能力的潜力。代码、模型和资源可在https://github.com/LCO-Embedding/LCO-Embedding获得。
🔬 方法详解
问题定义:现有基于对比学习微调的多模态大语言模型在跨模态表征学习中表现出色,但其内在机制尚不明确。特别是,为什么基于MLLM的方法比其他多模态嵌入方法更有效?论文旨在揭示MLLM在多模态表征学习中的优势,并提出更有效的学习框架。
核心思路:论文的核心思路是,MLLM在生成式预训练阶段已经学习到了隐式的跨模态对齐,这使得后续的对比学习能够更有效地提升表征质量。具体来说,语言解码器在生成单模态输出时,需要利用共享表征空间中的多模态信息,从而实现了模态间的对齐。
技术框架:LCO-Emb框架主要包含两个阶段:1) 基于MLLM的生成式预训练阶段,用于学习跨模态对齐的初始表征;2) 对比学习微调阶段,用于进一步优化表征,提升其区分能力。框架的输入是多模态数据(例如,图像和文本),输出是多模态数据的嵌入向量。
关键创新:论文的关键创新在于:1) 揭示了MLLM生成式预训练中的隐式跨模态对齐机制;2) 提出了LCO-Emb框架,该框架充分利用了MLLM的生成能力和对比学习的优化能力;3) 提出了生成-表征缩放定律(GRSL),该定律表明MLLM的生成能力与其表征能力之间存在正相关关系。
关键设计:在生成式预训练阶段,使用标准的语言模型损失函数。在对比学习微调阶段,使用InfoNCE损失函数,鼓励相似的样本具有相似的嵌入向量,不相似的样本具有不同的嵌入向量。论文还研究了不同的MLLM骨干网络和对比学习策略对性能的影响。具体来说,使用了CLIP作为视觉编码器,并探索了不同的文本编码器和对比学习目标。
🖼️ 关键图片


📊 实验亮点
LCO-Emb框架在多个跨模态检索任务上取得了SOTA性能。例如,在视觉-文档检索任务中,LCO-Emb相比于现有方法取得了显著的提升。此外,实验验证了生成-表征缩放定律,表明通过持续的生成式预训练可以进一步提升模型嵌入能力的潜力。在低资源视觉-文档检索任务中,持续生成式预训练后,模型性能得到显著提升。
🎯 应用场景
该研究成果可广泛应用于跨模态信息检索、视觉问答、图像描述生成等领域。通过提升多模态表征的质量,可以提高这些应用在实际场景中的性能和用户体验。此外,该研究提出的生成-表征缩放定律,为未来多模态表征学习的研究方向提供了新的思路。
📄 摘要(原文)
Recent multimodal embedding approaches leveraging multimodal large language models (MLLMs) fine-tuned with contrastive learning (CL) have shown promising results, yet the underlying reasons behind their superiority remain underexplored. This work argues that a crucial advantage of MLLM-based approaches stems from implicit cross-modal alignment achieved during generative pretraining, where the language decoder learns to exploit multimodal signals within a shared representation space for generating unimodal outputs. Through analysis of anisotropy and kernel similarity structure, we empirically confirm that latent alignment emerges within MLLM representations, allowing CL to serve as a lightweight refinement stage. Leveraging this insight, we propose a Language-Centric Omnimodal Embedding framework, termed LCO-Emb. Extensive experiments across diverse backbones and benchmarks demonstrate its effectiveness, achieving state-of-the-art performance across modalities. Furthermore, we identify a Generation-Representation Scaling Law (GRSL), showing that the representational capabilities gained through contrastive refinement scales positively with the MLLM's generative capabilities. This suggests that improving generative abilities evolves as an effective paradigm for enhancing representation quality. We provide a theoretical explanation of GRSL, which formally links the MLLM's generative quality to the upper bound on its representation performance, and validate it on a challenging, low-resource visual-document retrieval task, showing that continual generative pretraining before CL can further enhance the potential of a model's embedding capabilities. Codes, models, and resources are available at https://github.com/LCO-Embedding/LCO-Embedding.