ACADREASON: Exploring the Limits of Reasoning Models with Academic Research Problems
作者: Xin Gui, King Zhu, JinCheng Ren, Qianben Chen, Zekun Moore Wang, Yizhi LI, Xinpeng Liu, Xiaowan Li, Wenli Ren, Linyu Miao, Tianrui Qin, Ziqi Shu, He Zhu, Xiangru Tang, Dingfeng Shi, Jiaheng Liu, Yuchen Eleanor Jiang, Minghao Liu, Ge Zhang, Wangchunshu Zhou
分类: cs.CL
发布日期: 2025-10-13
💡 一句话要点
提出Acadreason基准,评估LLM和Agent在学术研究问题上的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 学术基准 知识推理 智能Agent
📋 核心要点
- 现有评估侧重于数学/代码或通用任务,缺乏针对高水平学术推理的基准。
- 提出Acadreason基准,包含五个领域的高难度学术问题,评估LLM和Agent的推理能力。
- 实验表明,现有LLM和Agent在Acadreason上的表现远未达到人类水平,存在显著差距。
📝 摘要(中文)
近年来,大型语言模型(LLM)和Agent的研究重点日益从展示新能力转向复杂推理和解决具有挑战性的任务。然而,现有的评估主要集中在数学/代码竞赛或通用任务上,而现有的多领域学术基准缺乏足够的推理深度,使得该领域缺乏一个用于高水平推理的严格基准。为了填补这一空白,我们引入了Acadreason基准,旨在评估LLM和Agent获取和推理学术知识的能力。它由50个专家注释的学术问题组成,涵盖计算机科学、经济学、法律、数学和哲学五个高推理领域。所有问题均来自近年来的顶级出版物,并经过严格的注释和质量控制,以确保它们既具有挑战性又可解答。我们对10多个主流LLM和Agent进行了系统评估。结果表明,大多数LLM的得分低于20分,即使是最前沿的GPT-5也仅获得16分。虽然Agent取得了更高的分数,但没有一个超过40分。这表明LLM和Agent在超智能学术研究任务中的能力差距,并突出了Acadreason的挑战性。
🔬 方法详解
问题定义:现有的大型语言模型(LLM)和Agent在复杂推理和解决挑战性任务方面取得了显著进展,但缺乏一个专门用于评估其在学术研究领域高水平推理能力的基准。现有的评估主要集中在数学/代码竞赛或通用任务上,而现有的多领域学术基准缺乏足够的推理深度,无法充分测试LLM和Agent的学术推理能力。因此,需要一个更具挑战性和深度的基准来评估LLM和Agent在学术研究问题上的表现。
核心思路:Acadreason的核心思路是构建一个高质量、高难度的学术推理基准,该基准包含来自不同学术领域的复杂问题,需要LLM和Agent具备深入的领域知识和强大的推理能力才能解决。通过对LLM和Agent在Acadreason上的表现进行评估,可以更准确地了解它们在学术研究领域的推理能力,并为未来的研究提供指导。
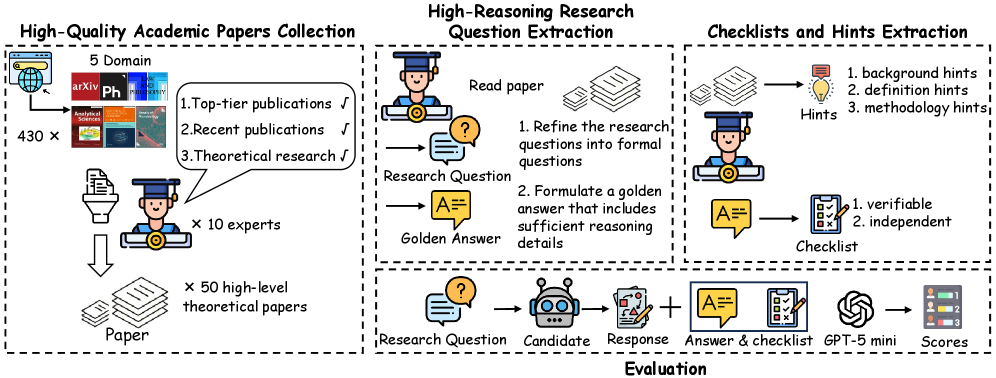
技术框架:Acadreason基准包含以下几个主要组成部分:1)问题收集:从计算机科学、经济学、法律、数学和哲学五个高推理领域的顶级出版物中收集问题。2)问题注释:由领域专家对问题进行注释,包括正确答案和推理过程。3)质量控制:对注释进行严格的质量控制,确保问题的准确性和可解答性。4)评估:使用Acadreason基准评估LLM和Agent的推理能力。
关键创新:Acadreason的关键创新在于其问题的难度和深度。与现有的基准相比,Acadreason的问题更具挑战性,需要LLM和Agent具备更深入的领域知识和更强大的推理能力才能解决。此外,Acadreason还提供了详细的注释,包括正确答案和推理过程,这有助于研究人员更好地理解LLM和Agent的推理过程。
关键设计:Acadreason的关键设计包括:1)问题选择:选择来自顶级出版物的问题,确保问题的质量和难度。2)领域覆盖:涵盖计算机科学、经济学、法律、数学和哲学五个领域,确保基准的全面性。3)注释质量:由领域专家进行注释,并进行严格的质量控制,确保注释的准确性。
🖼️ 关键图片
📊 实验亮点
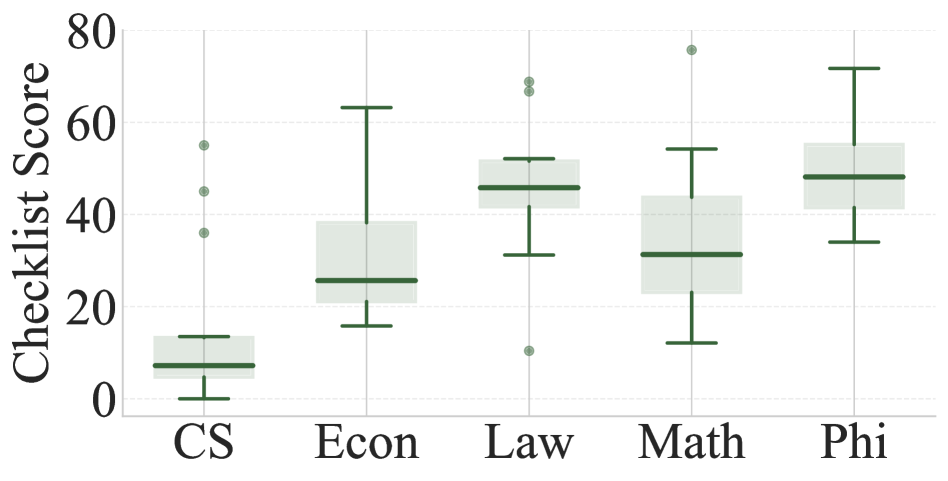
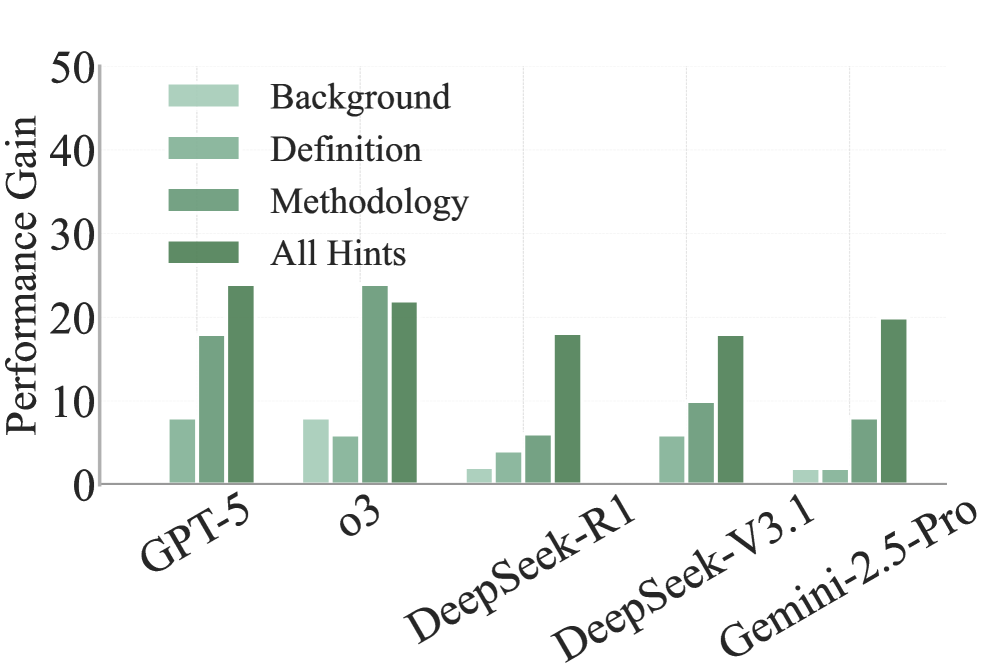
对10多个主流LLM和Agent的评估结果表明,即使是最先进的GPT-5在Acadreason上的得分也仅为16分,而Agent的最高得分也未超过40分。这表明当前LLM和Agent在解决高难度学术研究问题方面仍存在显著差距,Acadreason能够有效区分不同模型的推理能力。
🎯 应用场景
Acadreason基准可用于评估和提升LLM和Agent在学术研究领域的推理能力,促进AI在科研领域的应用。例如,可以利用LLM和Agent辅助科研人员进行文献综述、问题求解和假设验证等工作,提高科研效率和创新能力。此外,该基准还可以用于开发更智能的教育系统,帮助学生更好地理解和掌握学术知识。
📄 摘要(原文)
In recent years, the research focus of large language models (LLMs) and agents has shifted increasingly from demonstrating novel capabilities to complex reasoning and tackling challenging tasks. However, existing evaluations focus mainly on math/code contests or general tasks, while existing multi-domain academic benchmarks lack sufficient reasoning depth, leaving the field without a rigorous benchmark for high-level reasoning. To fill this gap, we introduce the Acadreason benchmark, designed to evaluate the ability of LLMs and agents to acquire and reason over academic knowledge. It consists of 50 expert-annotated academic problems across five high-reasoning domains, including computer science, economics, law, mathematics, and philosophy. All questions are sourced from top-tier publications in recent years and undergo rigorous annotation and quality control to ensure they are both challenging and answerable. We conduct systematic evaluations of over 10 mainstream LLMs and agents. The results show that most LLMs scored below 20 points, with even the cutting-edge GPT-5 achieving only 16 points. While agents achieved higher scores, none exceeded 40 points. This demonstrates the current capability gap between LLMs and agents in super-intelligent academic research tasks and highlights the challenges of Acadreason.